\[\tilde{X_t}-\sum_{j=1}^p \phi_j \tilde{X}_{t-j}= a_t - \sum_{j=1}^q \theta_j {a}_{t-j}\] donde \(\tilde{X_t}=X_t-\mu\).
Entonces, si un VARMA es estacionario se puede expresar su versión centrada, o bien sin pérdida de generalidad suponer que \(\phi_0=0\).
Además, su representación es similar al caso univariado
\[\phi(B) X_{t}= \theta(B) a_{t}\] en donde
\(\phi(B)=I- \phi_1 B-...- \phi_p B^p\) es el operador autorregresivo y
\(\theta(B)=I-\theta_1 B-...- \theta_q B^q\) es el operador de medias móviles.
VAR(p)
Contenido
VARMA(p,q)
VAR(p)
Causalidad de Granger
Invertibilidad
Estacionariedad
Estimación, selección de modelos y diagnósticos
VMA(q)
VAR(p)
El modelo VAR(p): \[X_{t}=\phi_0+\phi_1 X_{t-1}+...+\phi_pX_{t-p}+a_{t}\] donde \(\phi_0\) es un vector de dimensión \(k\), \(\phi_i\) matrices \(k \times k\) para \(i=1,...,p\), \(\phi_p \neq 0\) y \(a_t\) es una secuencia de i.i.d. vectores aleatorios con media 0 y matriz de covariancias \(\Sigma_a\), que es definida positiva.
Su representación con el operador autorregresivo. \[\phi(B) X_{t}=\phi_0+a_{t}\] donde \(\phi(B)=I_k- \phi_1 B-...- \phi_p B^p\) es el operador autorregresivo.
De la misma forma, se puede considerar su versión centrada (si es estacionario): \[\phi(B) \tilde{X}_{t}= a_{t}\]
Tenemos que \(X_{1,t}\) no depende de los valores pasados de \(X_{2,t}\), pero \(X_{2,t}\) depende de los valores pasados de \(X_{1,t}\). Se dice que \(X_{1,t}\) y \(X_{2,t}\) tienen una relación de función de transferencia.
En econometría, se dice que \(X_{t,1}\)causa a \(X_{t,2}\) en el sentido de Granger, pero inversamente no: \(X_{t,2}\)no causa a \(X_{t,1}\) en el sentido de Granger.
Causalidad de Granger
Contenido
VARMA(p,q)
VAR(p)
Causalidad de Granger
Invertibilidad
Estacionariedad
Estimación, selección de modelos y diagnósticos
VMA(q)
Causalidad de Granger
El concepto de causalidad de Granger fue introducido por Granger (1969) considerando una serie bivariada \((X_{1,t,},X_{2,t})\) y el ajuste de un modelo VAR y los modelos univariados para realizar predicción.
Se dice que \(X_{1,t}\) causa a \(X_{2,t}\) en el sentido de Granger, si la predicción usando modelo VAR es más precisa que la predicción utilizando el modelo univariado.
Formalmente, sean:
\(F_t\) toda la información disponible hasta el tiempo t (inclusive),
\(F_{-i,t}\) como toda la información \(F_t\) pero sin el \(i-\)ésimo componente \(X_{i,t}\).
En término del VAR(1) bidimensional descrito anteriormente,
\(X_{j,t+h}|F_{t}\), \(j=1,2\) como las predicciones \(h\) pasos adelante basado en toda la información disponible \(F_{t}\) y \(e_{j,t+h}|F_{t}\) sus errores de pronósticos respectivos.
\(X_{j,t+h}|F_{-i,t}\), \(j=1,2\) como las predicciones \(h\) pasos adelante basado en \(F_{-i,t}\) y \(e_{j,t+h}|F_{-i,t}\) sus errores de pronósticos respectivos.
Se dice que que \(X_{1,t}\)causa a \(X_{2,t}\)en el sentido de Granger, si
Se dice que \(X_{1,t}\) causa a \(X_{2,t}\) en el sentido de Granger si \(\phi_{1,21} \neq 0\). Sin embargo, \(X_{2,t}\) no causa a \(X_{1,t}\) en el sentido de Granger.
Recuerden que \(\Sigma_a\) no necesariamente es una matriz diagonal.
Si \(\Sigma_a\) no es una matriz diagonal, se dice que \(X_{1,t}\) y \(X_{2,t}\) tienen causalidad instantánea en sentido de Granger.
Invertibilidad
Contenido
VARMA(p,q)
VAR(p)
Causalidad de Granger
Invertibilidad
Estacionariedad
Estimación, selección de modelos y diagnósticos
VMA(q)
Invertibilidad
Por definición VAR(p) es invertible ya que está expresada en término de sus valores pasados:
\[X_t=c+a_t+\sum_{j=0}^\infty \pi_j X_{t-j}\]
Estacionariedad
Contenido
VARMA(p,q)
VAR(p)
Causalidad de Granger
Invertibilidad
Estacionariedad
Estimación, selección de modelos y diagnósticos
VMA(q)
Estacionariedad de un VAR(1)
Empezamos con un VAR(1):
Sin pérdida de generalidad, suponga que \(\phi_0=0\),
Al igual que el caso univariado, para que el proceso esté bien definido, es necesario que \(\phi_1^{J}\rightarrow 0\) cuando \(J \rightarrow \infty\).
La condición de \(\phi_1^{J}\rightarrow 0\) cuando \(J \rightarrow \infty\) significa que todos los autovalores de \(\lambda_i\) de la matriz \(\phi_1\) satisfacen la condición de que \(\lambda_i^{J}\rightarrow 0\) cuando \(J \rightarrow \infty\).
Y esto significa que el valor absoluto de todos los autovalores \(\lambda_i\) de \(\phi_1\) es menor a 1.
Recordemos que para la matriz \(\phi_1\), sus autovalores son las soluciones de la ecuación: \[|\lambda I_k - \phi_1|=0.\]
y es posible reescribir la condición \[\lambda^k \left|I_k - \phi_1\frac{1}{\lambda}\right|=0.\]
Es decir, \(\left|I_k - \phi_1 x\right|=0\) donde \(x=1/\lambda\). Los autovalores de \(\phi_1\) son inversos de la solución de esta ecuación.
Como consecuencia, la condición necesaria y suficiente de la estacionariedad de un VAR(1) es que las soluciones de la ecuación \(\left|I_k - \phi_1 x\right|=0\) tengan valor absoluto mayor a 1.
Es decir, la condición de estacionariedad de un VAR(1) es que las soluciones de \(|\phi(B)|=0\) estén fuera del círculo unitario.
VAR(p)
El modelo VAR(p): \[X_{t}=\phi_0+\phi_1 X_{t-1}+...+\phi_pX_{t-p}+a_{t}\] donde \(\phi_0\) es un vector de dimensión \(k\), \(\phi_i\) matrices \(k \times k\) para \(i=1,...,p\), \(\phi_p \neq 0\) y \(a_t\) es una secuencia de i.i.d. vectores aleatorios con media 0 y matriz de covariancias \(\Sigma_a\), que es definida positiva.
De la misma forma, se puede considerar su versión centrada (si es estacionario): \[\phi(B) \tilde{X}_{t}= a_{t}\]
donde \(\phi(B)=I_k- \phi_1 B-...- \phi_p B^p\) es el operador autorregresivo, y \(\tilde{X}_{t}={X}_{t}-\mu_X\).
VAR(p) como representación de VAR(1)
Sin pérdida de generalidad, asuma \(\phi_0=0\). Defina \(\boldsymbol{X}_t=\left(X_t',X_{t-1}',...,X_{t-p+1}' \right)'\) una serie temporal \(pk-\)dimensional.
La matrix \(\Phi\) es conocida como la matriz compañera del polinomio autorregresivo \(\phi(B)\).
Condición de estacionariedad de VAR(p)
Como consecuencia de que \(\boldsymbol{X}_t\) es VAR(1), la condición de estacionariedad es VAR(1) es que las soluciones de la ecuación \(\left|I_{kp} - \Phi B\right|=0\) tengan valor absoluto mayor a 1.
Utilizando resultados de matrices en bloques, se puede concluir que la condición de estacionariedad de VAR(p) es que todas las soluciones de \(\left|I_{kp} - \Phi B\right|=|\phi(B)|=0\) estén fuera del círculo unitario.
Estimación, selección de modelos y diagnósticos
Contenido
VARMA(p,q)
VAR(p)
Causalidad de Granger
Invertibilidad
Estacionariedad
Estimación, selección de modelos y diagnósticos
VMA(q)
Estimación
Existen una extensa literatura en la estimación de un VAR.
Los más utilizados:
mínimos cuadrados,
máxima verosimilitud y
métodos Bayesianos.
Estimación de Máxima Verosimilitud
Asumiendo que \(a_t\) es normal multivariada y suponga que \(X_{1:T}=\left\lbrace X_1,...,X_T \right\rbrace\) son observaciones en el tiempo, la función de verosimlitud es:
donde \(c\) es una constante que no influye en el proceso de optimización.
Note que las propiedades \(tr(CD)=tr(DC)\) y \(tr(C+D)=tr(C)+tr(D)\) son utilizadas.
Se puede reescribir la función de log-verosimlitud como: \[\ell \left(\beta,\Sigma_a \right) = c- \frac{T-p}{2} \log|\Sigma_a| -\frac{1}{2} S(\beta)\] donde \(S(\beta)\) es la cantidad a minimizar del método de mínimos cuadrados.
No vamos a entrar a los detalles de la distribución muestral de los estimadores.
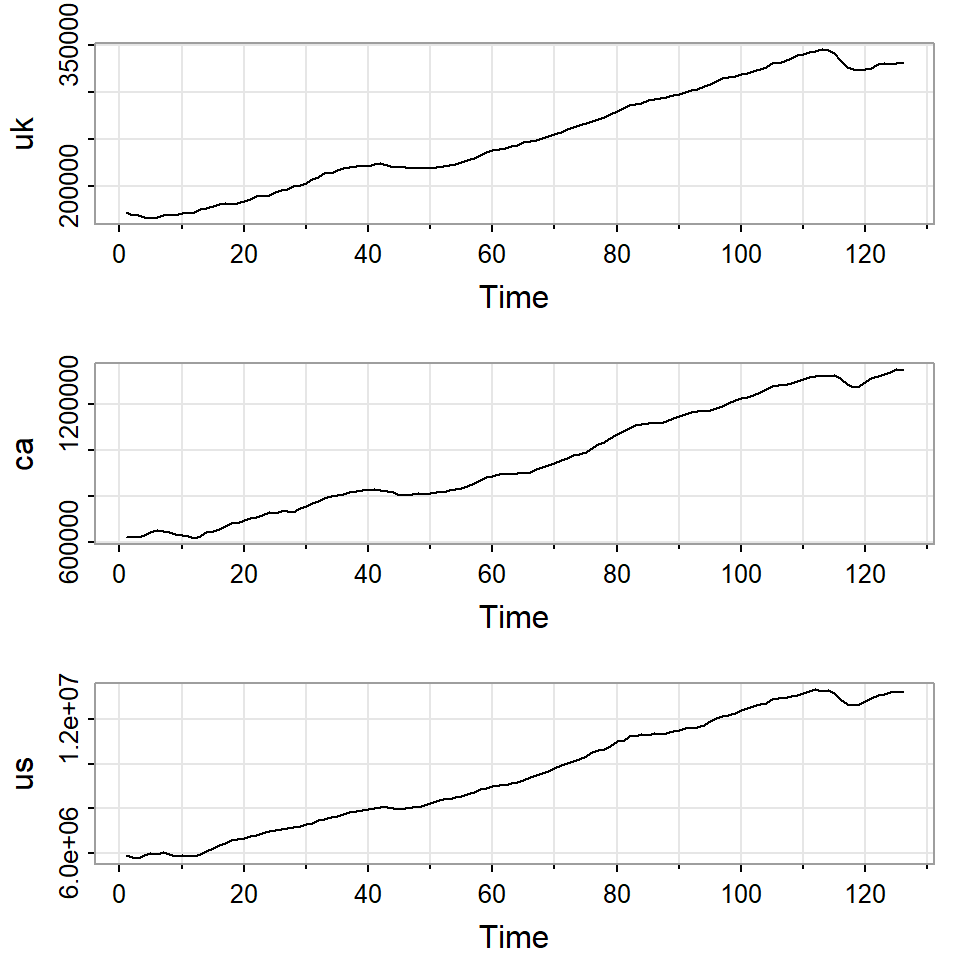
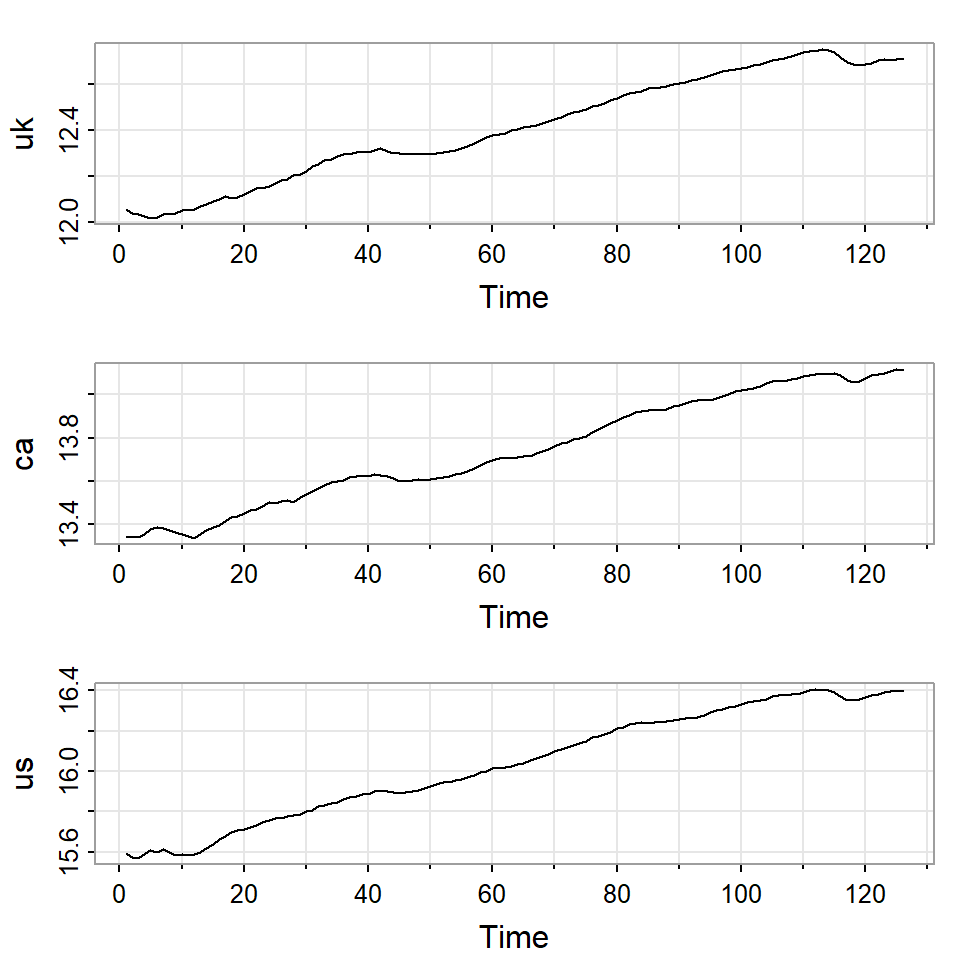
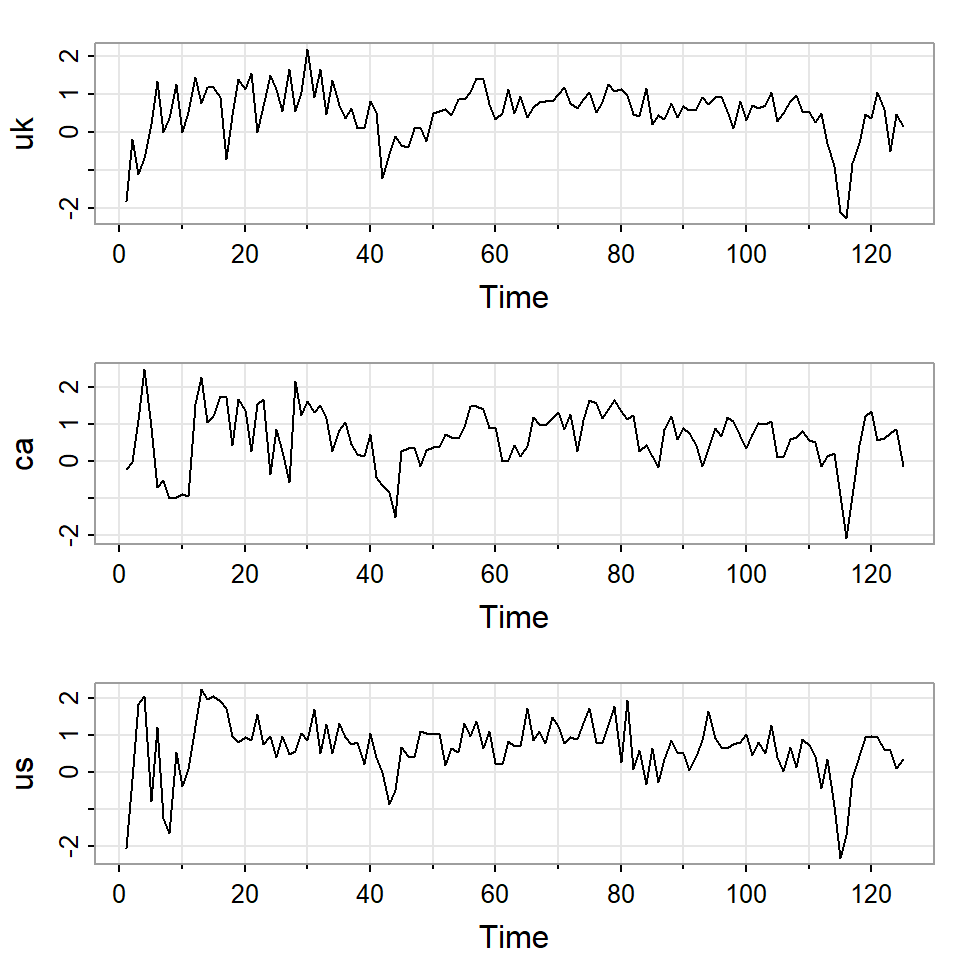
Ejemplo
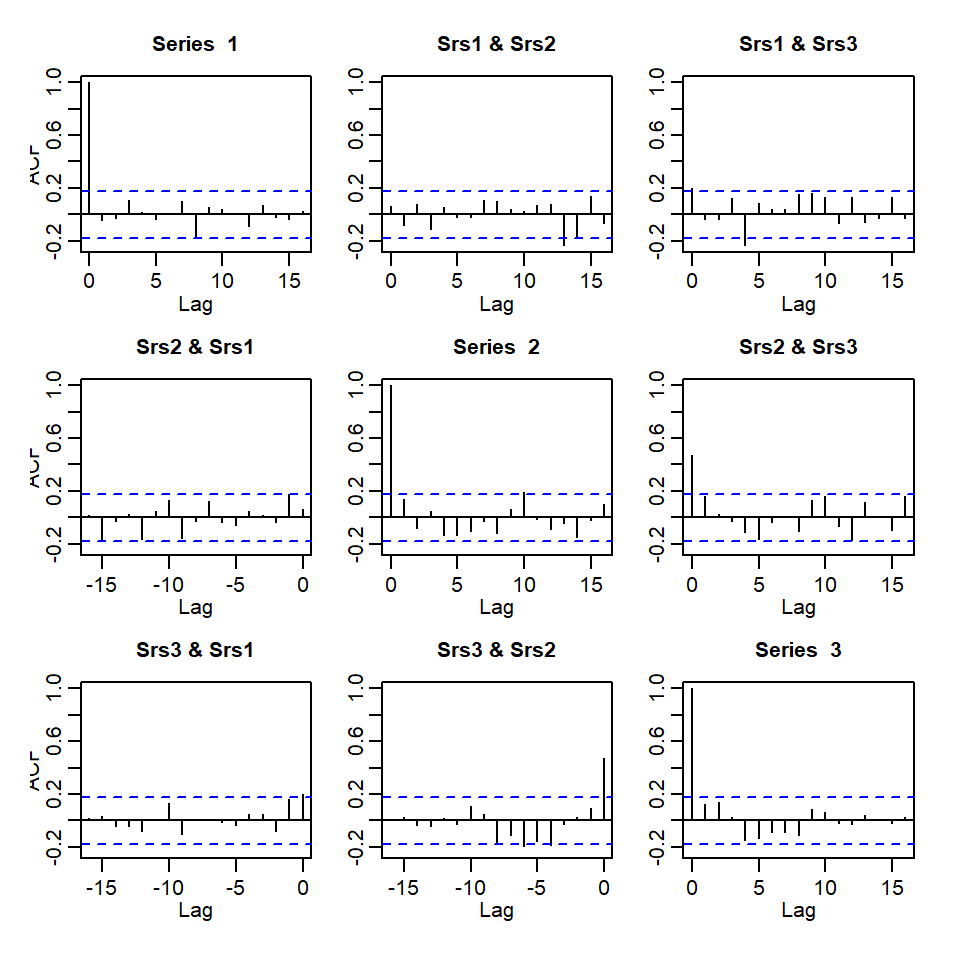
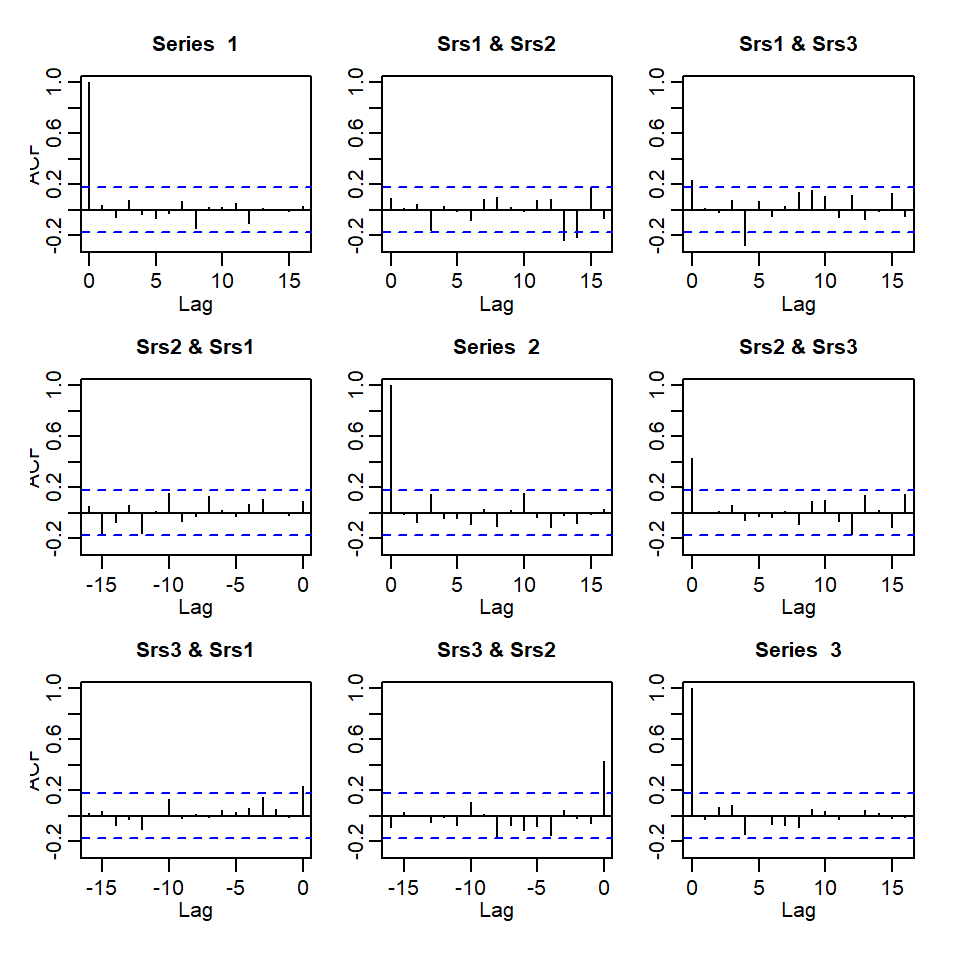
El producto interno bruto de Reino Unido, Canadá y Estados Unidos de segundo trimestre del 1980 al segundo trimestre del 2011.
Recuerde que para una función \(f(x)\), el polinomio de Taylor es una aproximación polinómica de una función n veces derivable en un punto \(a\). Concretamente:
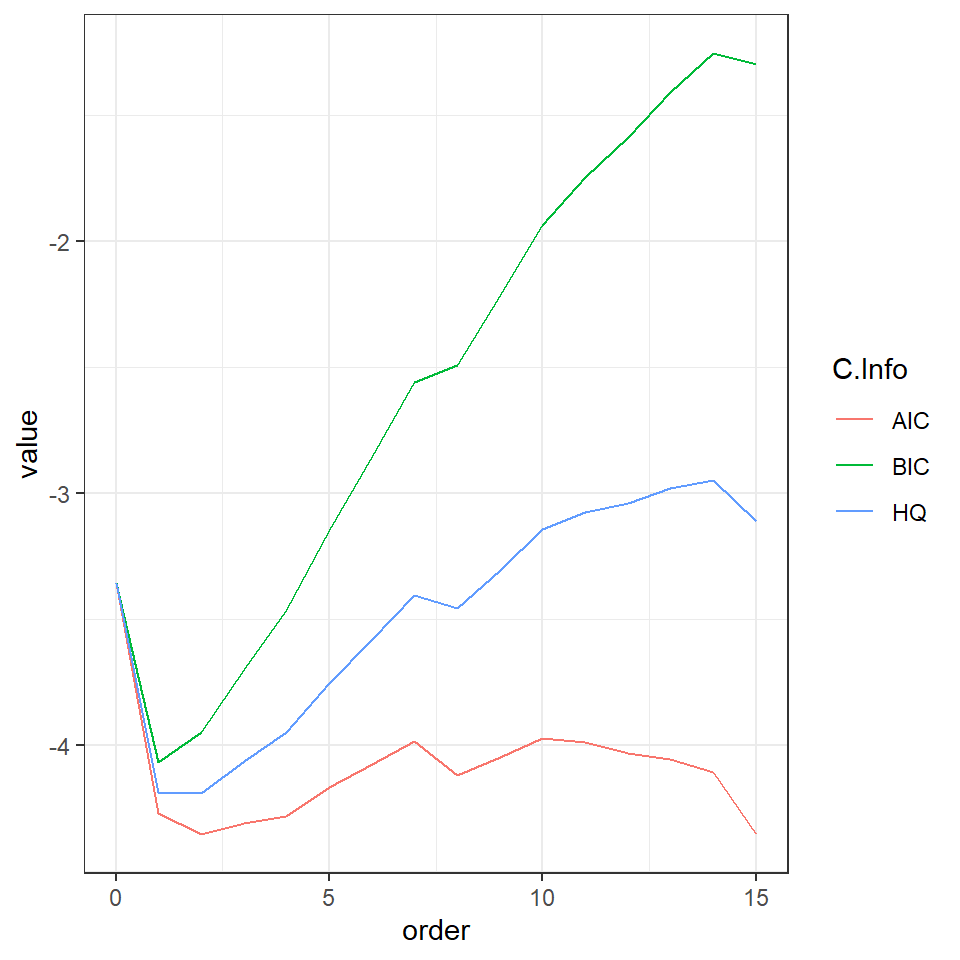
La idea básica es comparar un VAR(p) con un VAR(p-1).
Formalmente, se plantean: \(H_0:\phi_p=0\) contra \(H_1:\phi_p \neq 0\)
Sea \(\boldsymbol{\beta}=\left[\phi_0,\phi_1,...,\phi_p \right]\) el conjunto de las matrices de coeficientes de un VAR(p), y \(\Sigma_{a,p}\) la matriz de covariancias de las inovaciones del modelo.
Bajo el supuesto de normalidad, la razón de verosimilitud es dada por
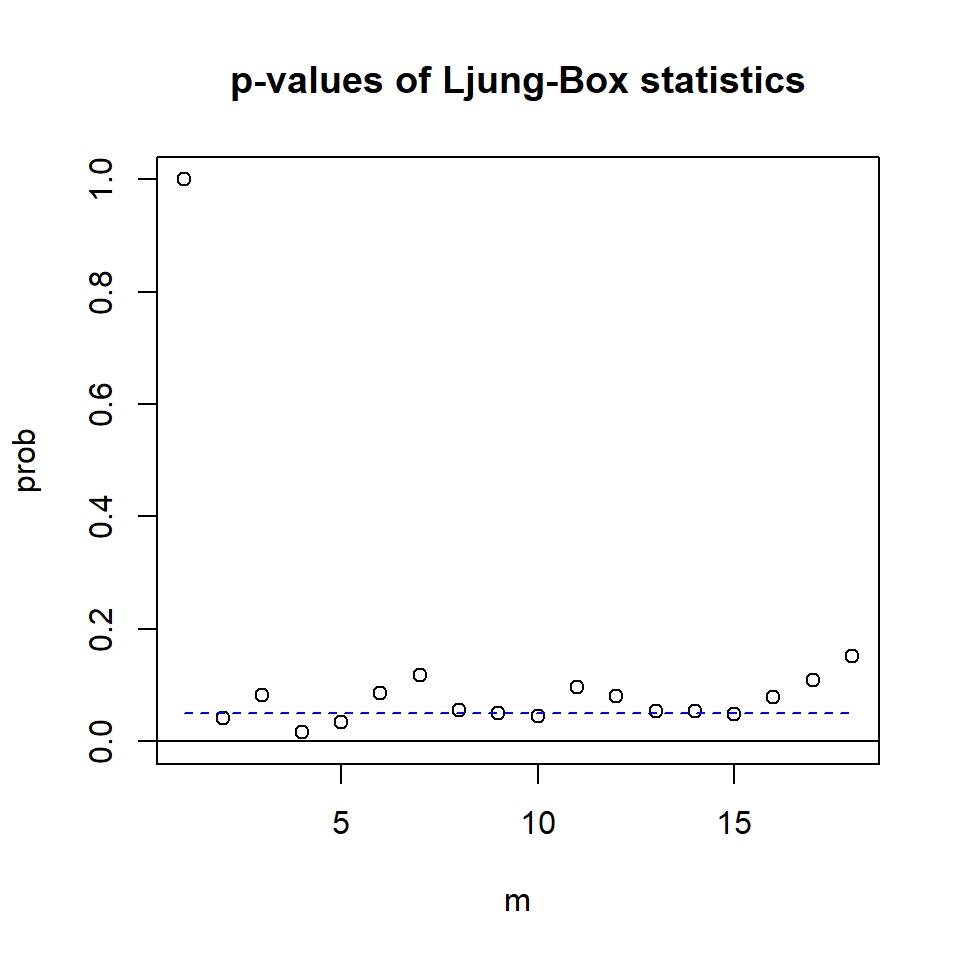
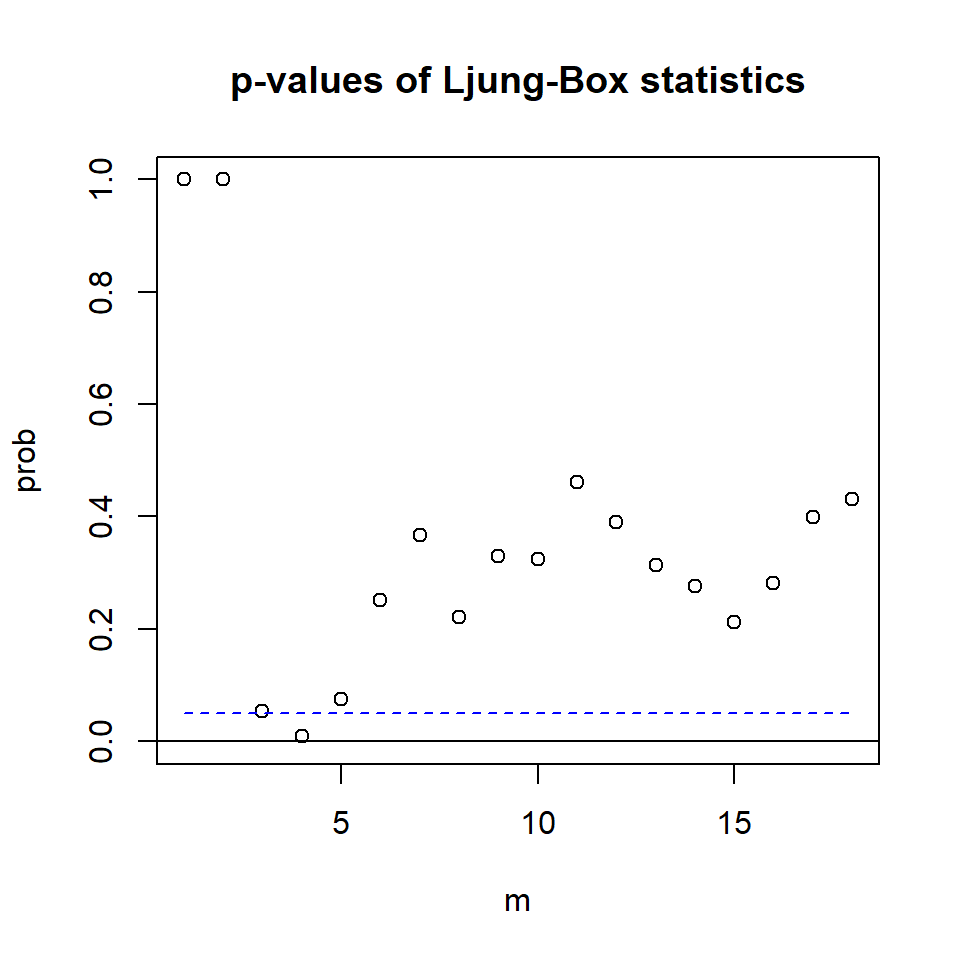
Denote \(R_j\) como la matriz de correlaciones de \(j\) rezago de los residuales. Se plantean las hipótesis: \(H_0: R_1=\cdots=R_m=0\) \(H_1: R_j \neq 0\), para algún \(1\leq j \leq m\)
Recuerden que el estadístico de Portmanteau multivariado es la versión multivariada de la prueba de Ljung-Box. \[Q_m=T^2 \sum_{l=1}^m \frac{1}{T-l} tr \left(\hat{R}'_l\hat{R}^{-1}_0\hat{R}_l\hat{R}^{-1}_0\right)\]
Bajo el supuesto de \(H_0\),i.e. \(R_l=0,~ l>0\), y \(X_t\) es distribuída normalmente, para \(T\) y \(m\) suficientemente grandes, el estadístico se aproxima a la distribución \(\chi^2_{mk^2}\).
Para el caso de un VAR(p) se deben corregir los grados de libertad. Note que \(\chi^2_{(m-p)k^2} = \chi^2_{mk^2-pk^2}\) [El valor de corrección es \(pk^2\)].
El modelo VMA(q): \[X_{t}=\mu+a_t -\theta_1 a_{t-1}-...-\theta_q a_{t-q}\] donde \(\mu\) es un vector de dimensión \(k\) que es su media, \(\theta_i\) matrices \(k \times k\) para \(i=1,...,q\), \(\theta_q \neq 0\) y \(a_t\) es una secuencia de i.i.d. vectores aleatorios con media 0 y matriz de covariancias \(\Sigma_a\), que es definida positiva.
Su representación con el operador de medias móviles. \[X_{t}=\mu + \theta(B) a_{t}\] donde \(\theta(B)=I_k- \theta_1 B-...- \theta_q B^q\) es el operador de medias móviles.
De la misma forma, se puede considerar su versión centrada: \[X_{t}-\mu = \theta(B) a_{t}\]
El VMA(q) siempre es estacionario pero no siempre es invertible.
La condición de invertibilidad se deriva muy similar al caso de estacionariedad de VAR(p).
Un VMA(q) es invertible si todas las soluciones de \(|\theta(B)|=0\) estén fuera del círculo unitario.
VARMA(p,q)
El modelo VARMA(p,q):
\[\phi(B) X_{t} = \phi_0 + \theta(B) a_{t}\] donde \(\phi(B)=I- \phi_1 B-...- \phi_p B^p\) es el operador autorregresivo y \(\theta(B)=I-\theta_1 B-...- \theta_q B^q\) es el operador de medias móviles.
La condición de estacionariedad es que todas las soluciones de \(|\phi(B)|=0\) estén fuera del círculo unitario.
La condición de invertibilidad es que todas las soluciones de \(|\theta(B)|=0\) estén fuera del círculo unitario.
El VARMA tiene problemas de identificabilidad debido a que su representación no es única. Se requieren adicionalmente dos condiciones:
Si \(u(B)\) es factor común por izquierda de \(\phi(B)\) y \(\theta(B)\), entonces \(|u(B)|\) es constante no nula.
El rango de la matriz conjunta \(\left[ \phi_p, \theta_q \right]\) es \(k\), la dimensión de la serie multivariada \(X_t\).
Algunos paquetes de R que estiman VARMA
MTS
marima
En la próxima clase
Enfocamos en el VAR(p) y veremos con más detalles
Causalidad de Granger
Raíz unitarias
Procesos cointegrados
Paquetes en R
Para replicar los ejemplos de esta presentación, necesitan estos paquetes:
Granger, C. W. J. 1969. «Investigating Causal Relations by Econometric Models and Cross-spectral Methods». Econometrica 37 (3): 424-38. http://www.jstor.org/stable/1912791.