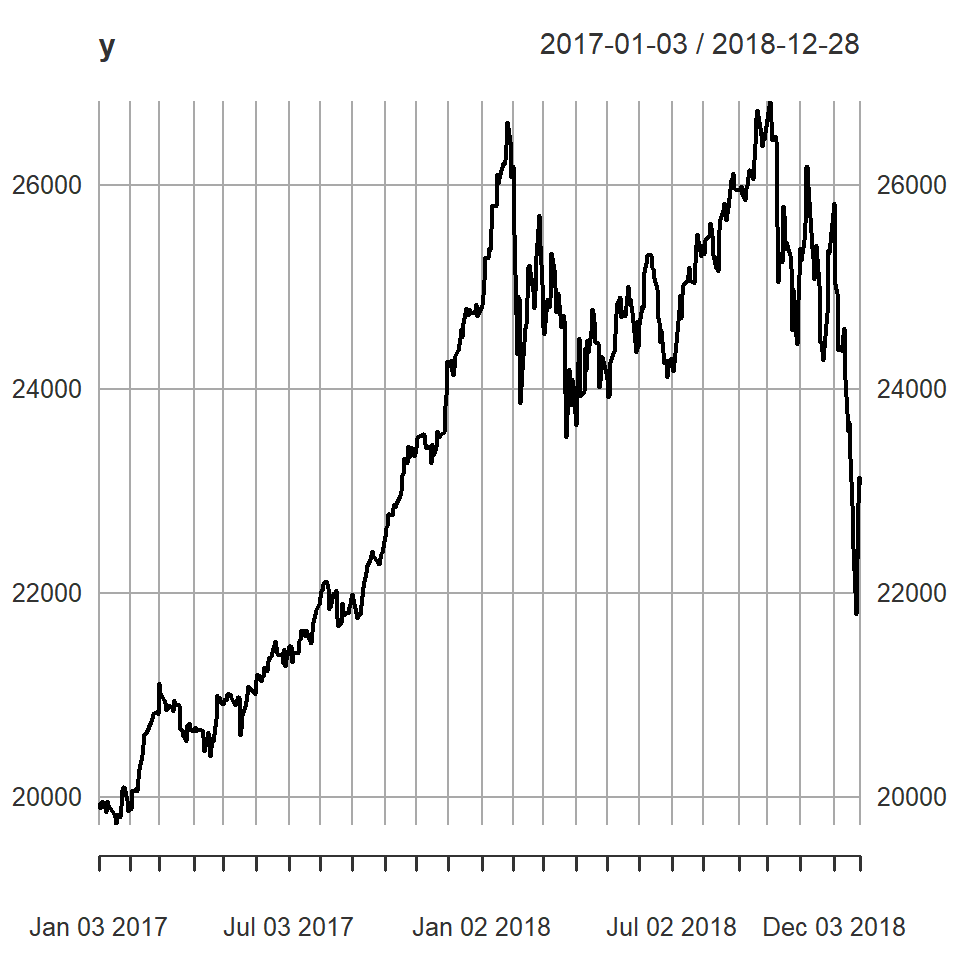
[1] "DJI"Tema 4: Modelos no lineales(1)
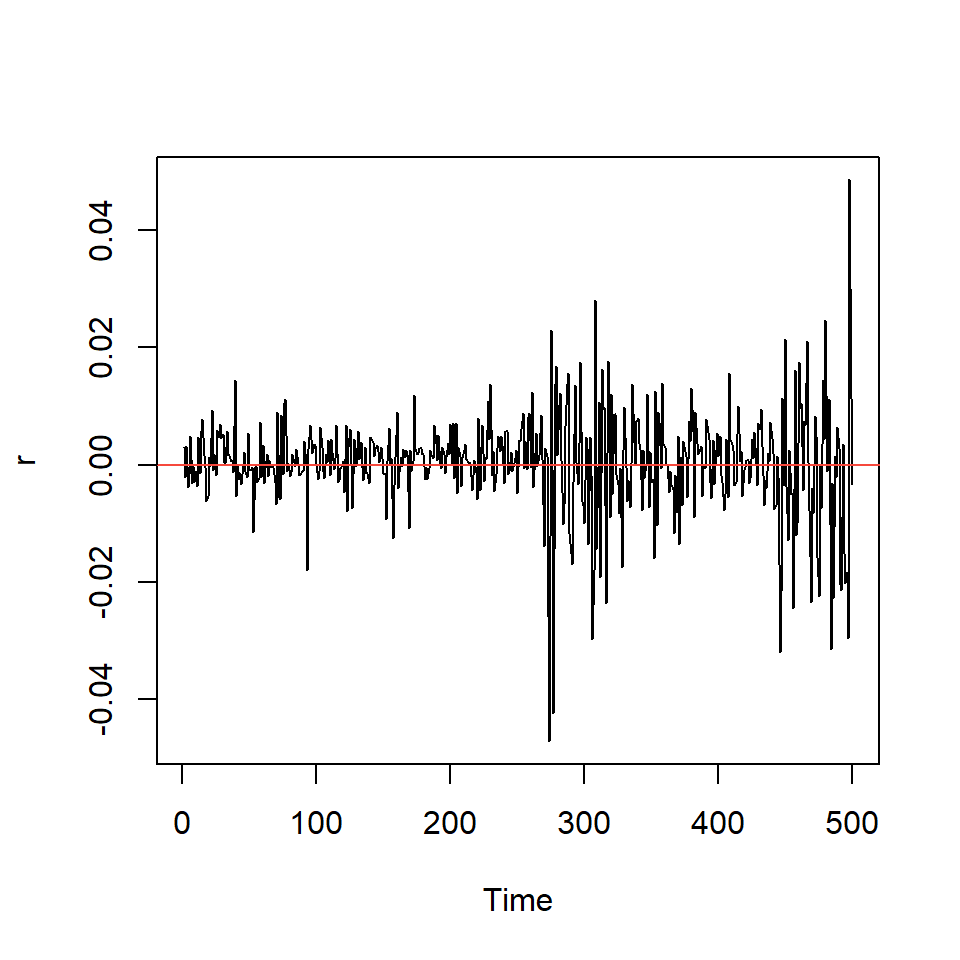
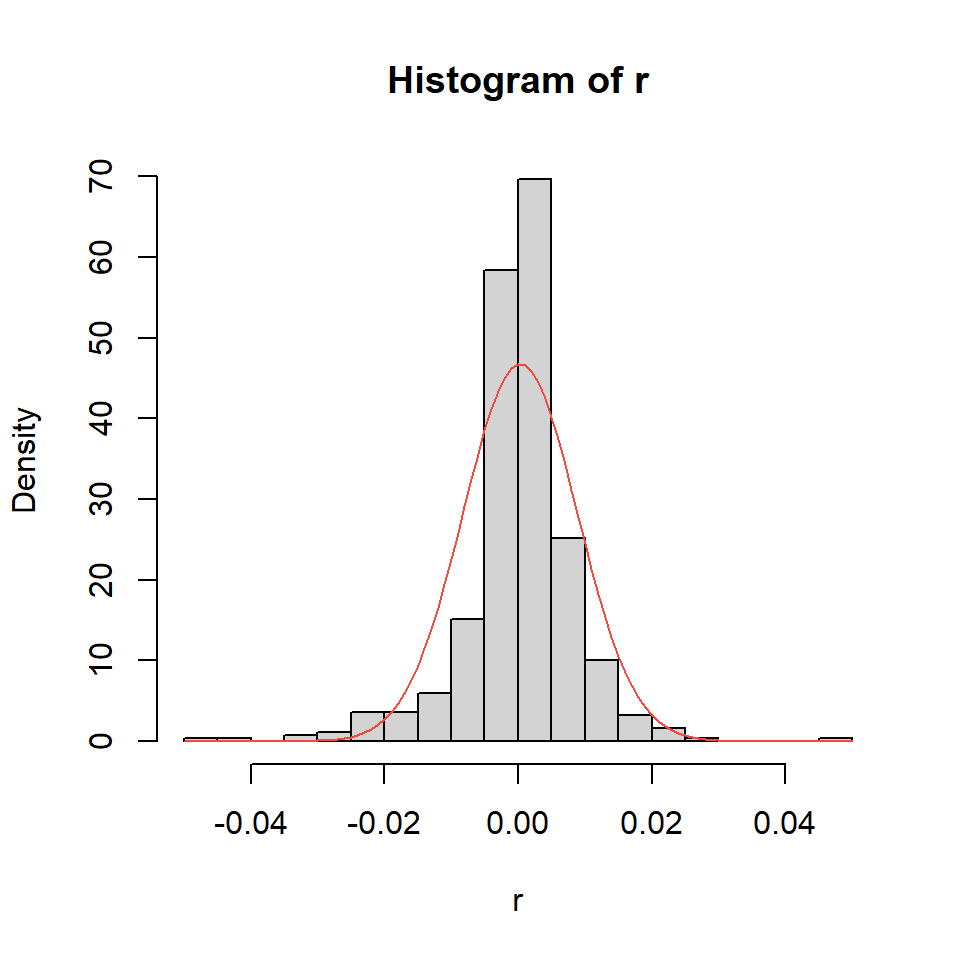
Ejemplo: promedio diario industrial Dow Jone
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13]
ACF 0.02 -0.07 0.05 -0.03 -0.02 -0.03 0.04 -0.11 0.01 0.01 0.00 -0.02 -0.04
PACF 0.02 -0.08 0.05 -0.04 -0.01 -0.04 0.04 -0.12 0.03 -0.02 0.02 -0.03 -0.03
[,14] [,15] [,16] [,17] [,18] [,19] [,20] [,21] [,22] [,23] [,24] [,25]
ACF -0.12 -0.01 0.04 0.09 0.05 -0.04 -0.05 0.05 0.10 0.02 -0.14 0.02
PACF -0.14 0.01 0.01 0.11 0.03 -0.03 -0.07 0.06 0.07 0.04 -0.15 0.04
[,26] [,27] [,28] [,29] [,30] [,31] [,32] [,33]
ACF 0.06 -0.01 0.03 0.03 0.01 -0.14 0.05 0.08
PACF 0.04 0.02 -0.01 0.04 0.03 -0.10 0.04 0.07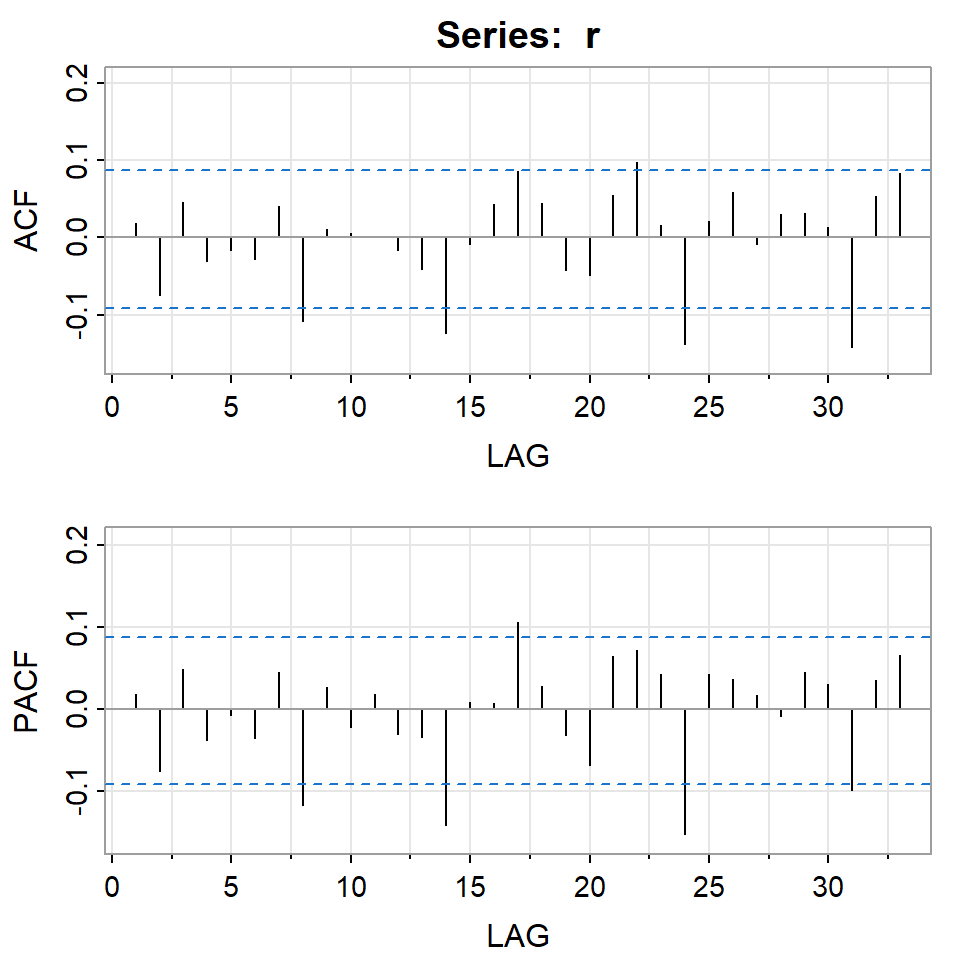
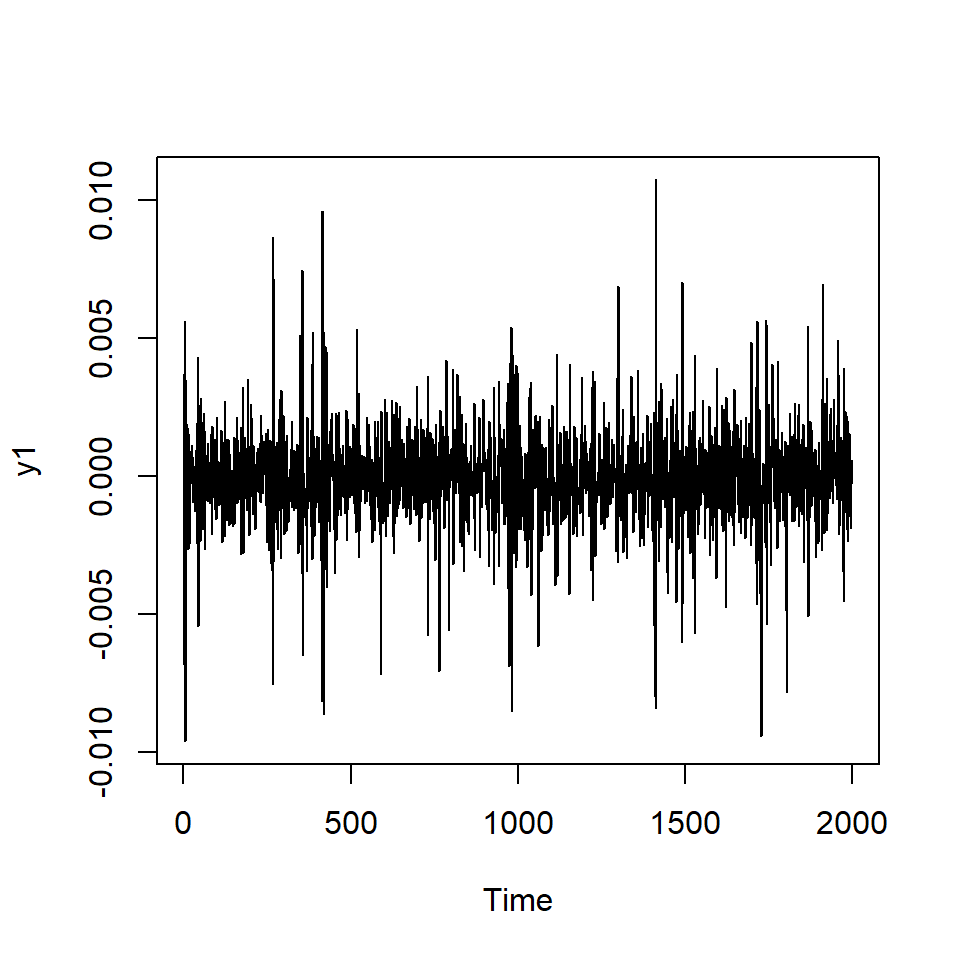
Simulación de ARCH(1) con \(\alpha_0=0.01\), \(\alpha_1=0.8\)
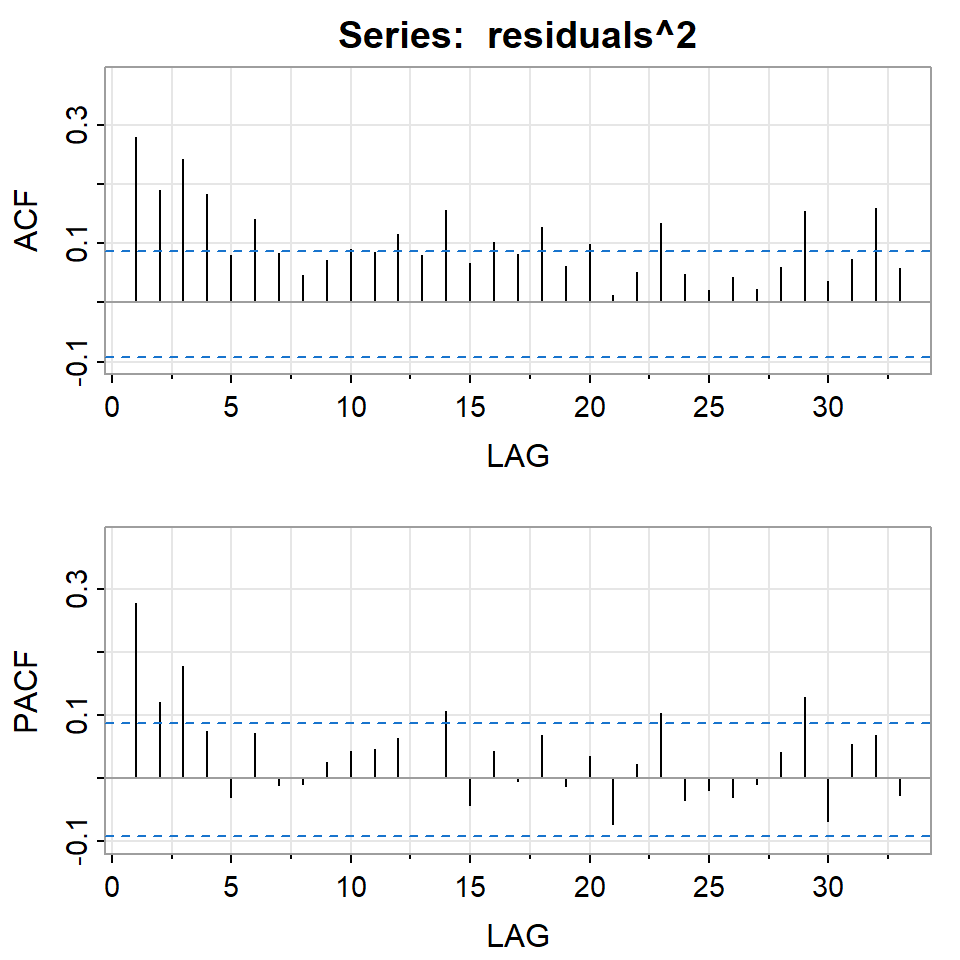
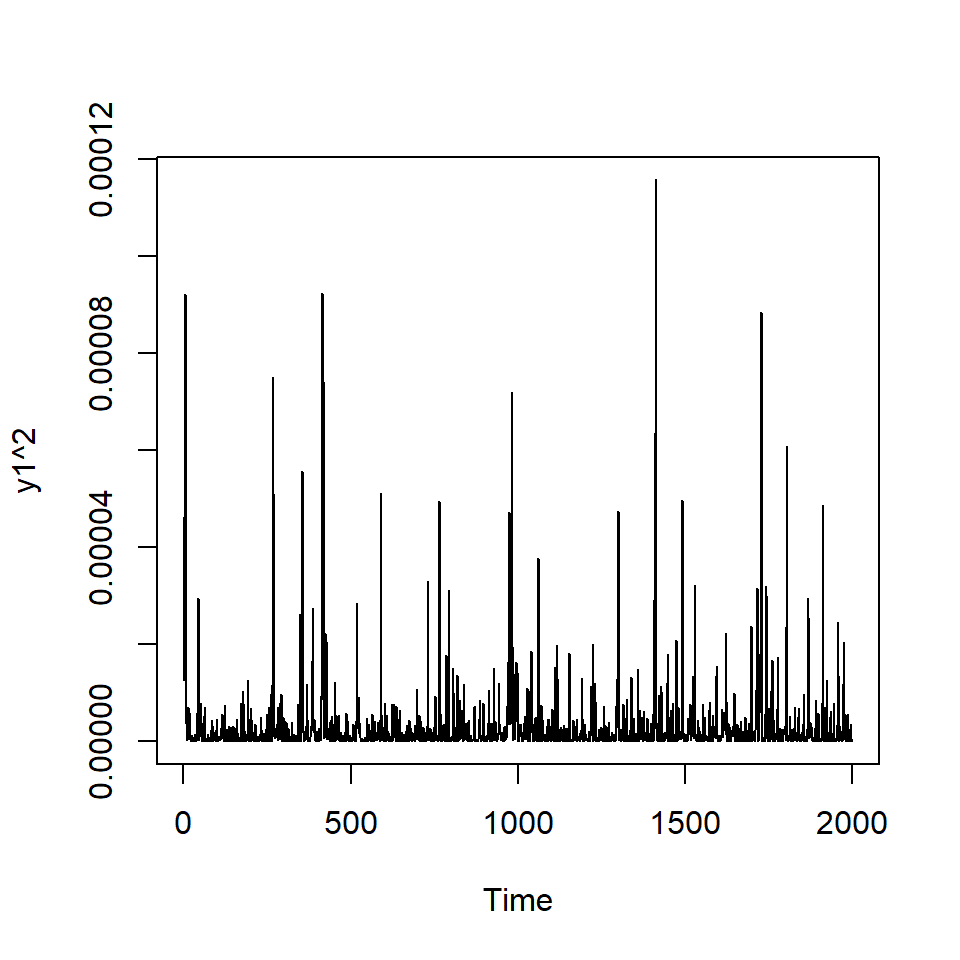
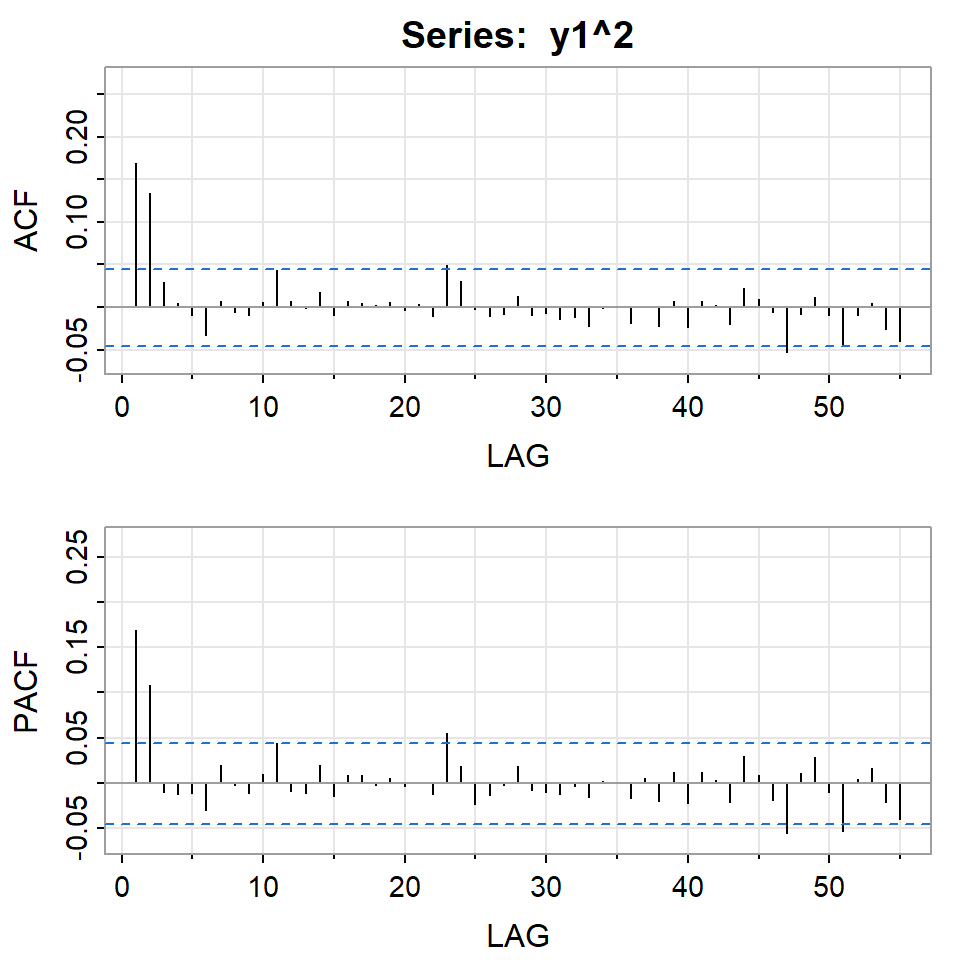
Si elevamos al cuadrado la serie simulada \(X_t\).
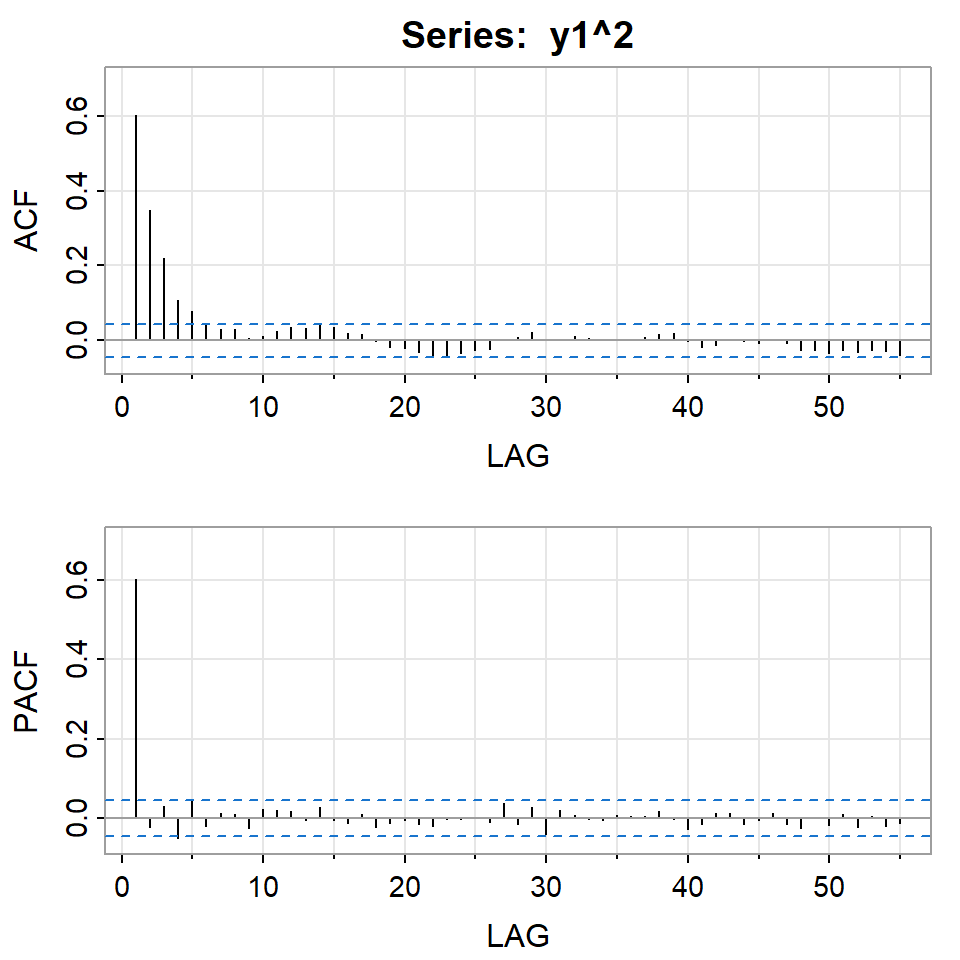
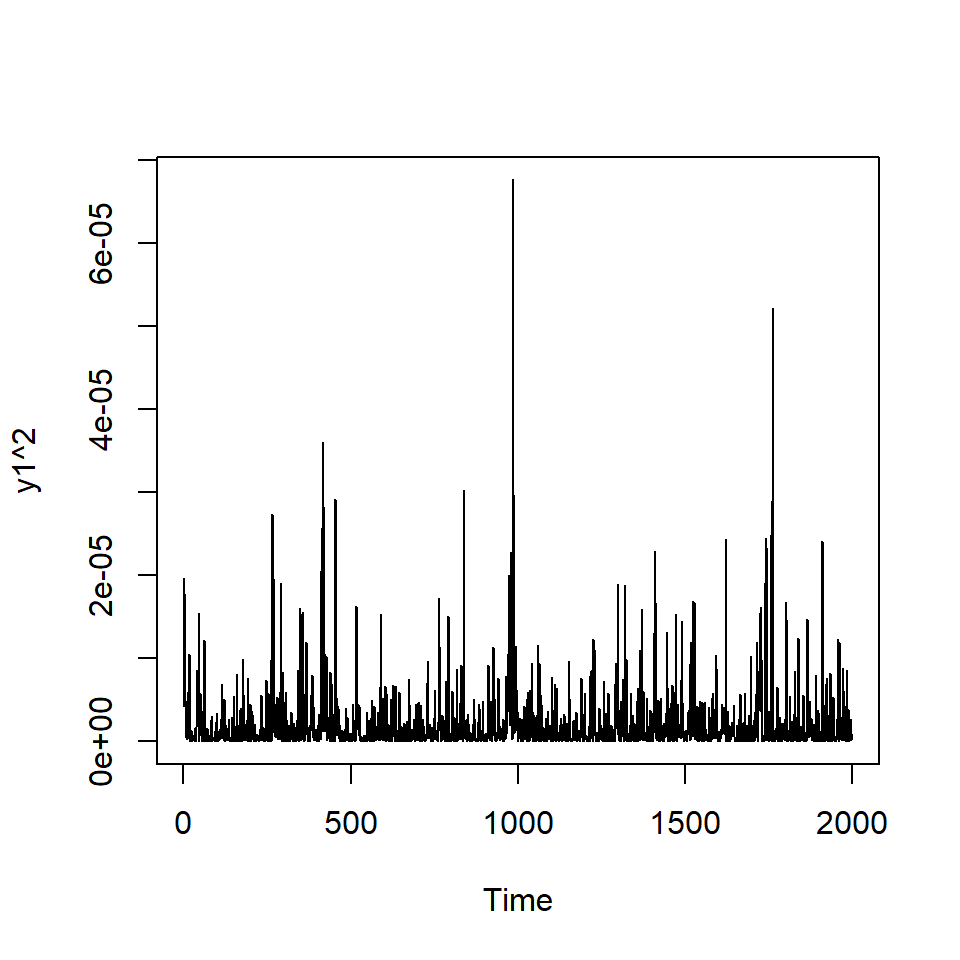
Simulación de ARCH(2) con \(\alpha_0=0.01\), \(\alpha_1=0.2\), \(\alpha_2=0.4\)
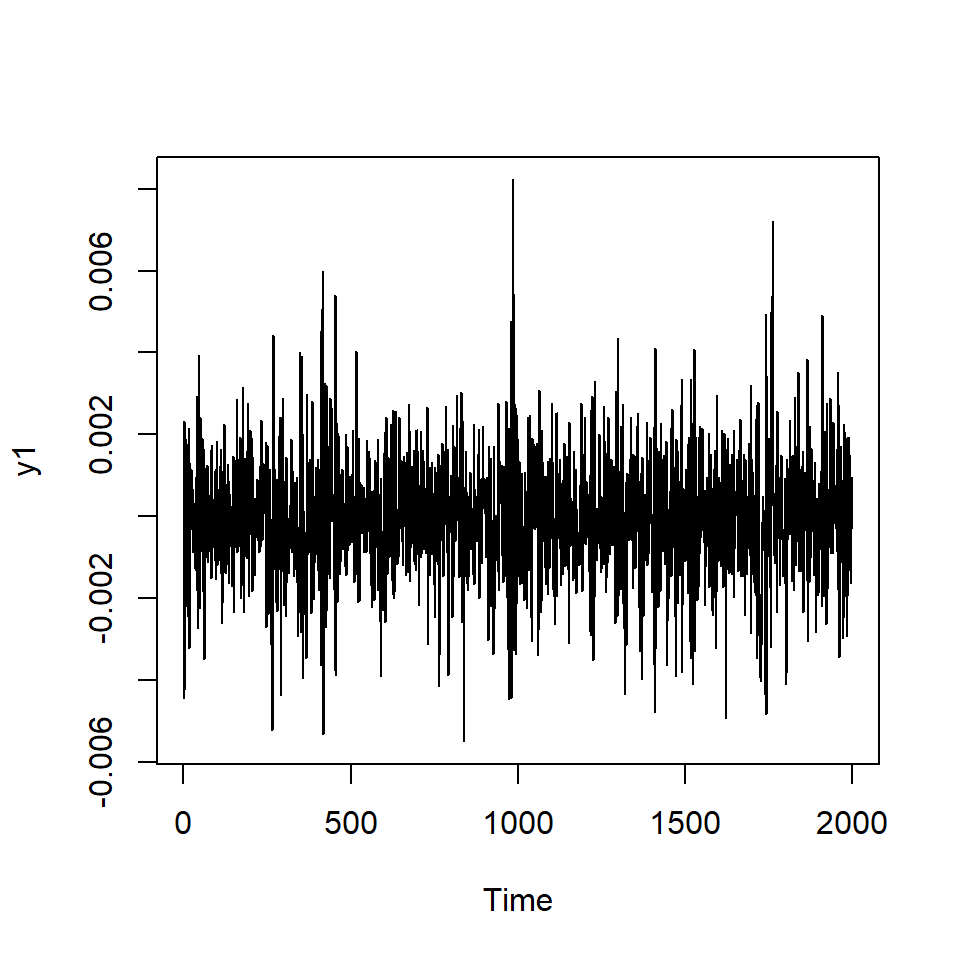
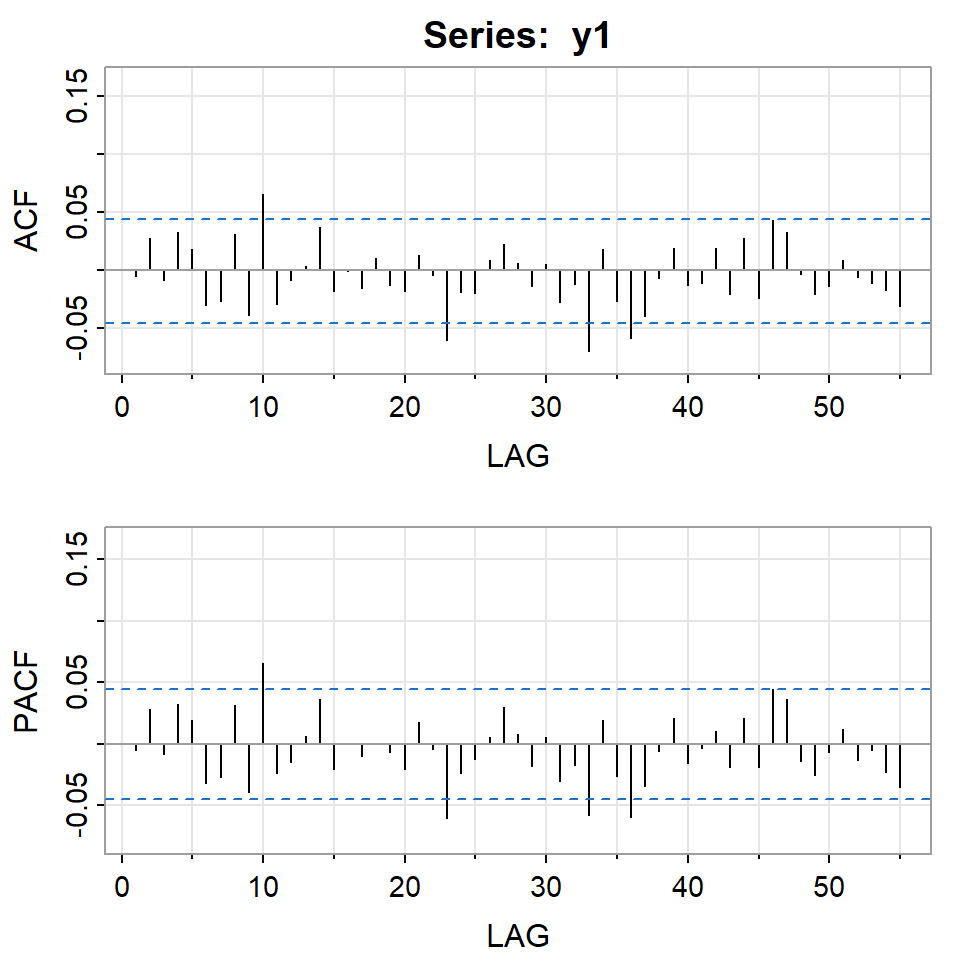
Si elevamos al cuadrado la serie simulada \(X_t\).
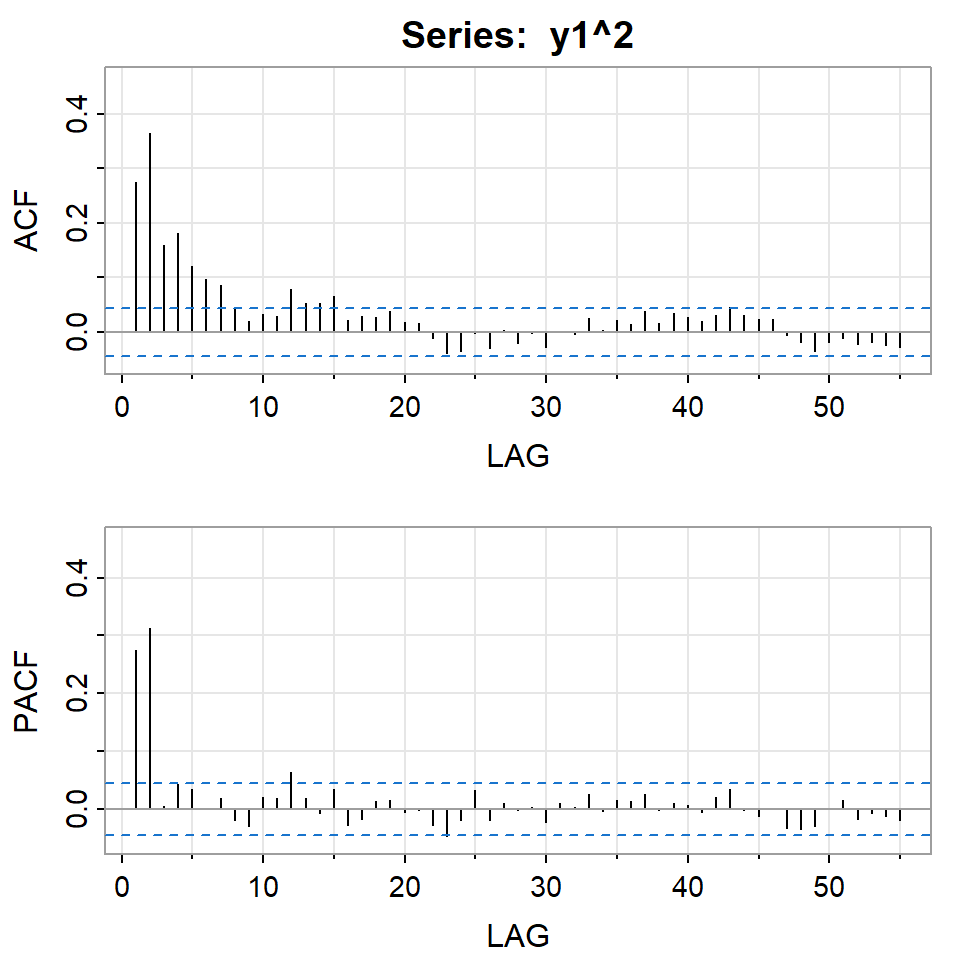
Simulación de GARCH(1,1) con \(\alpha_0=0.01\), \(\alpha_1=0.2\), \(\beta_2=0.4\)
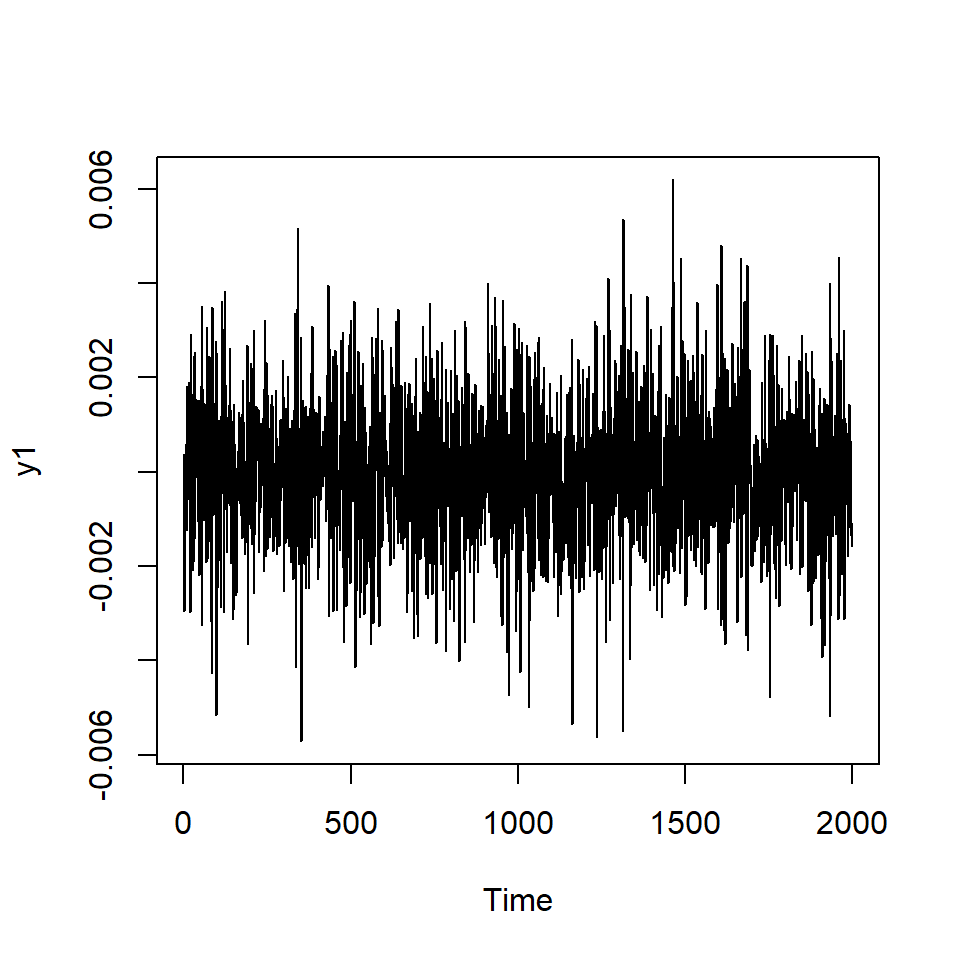
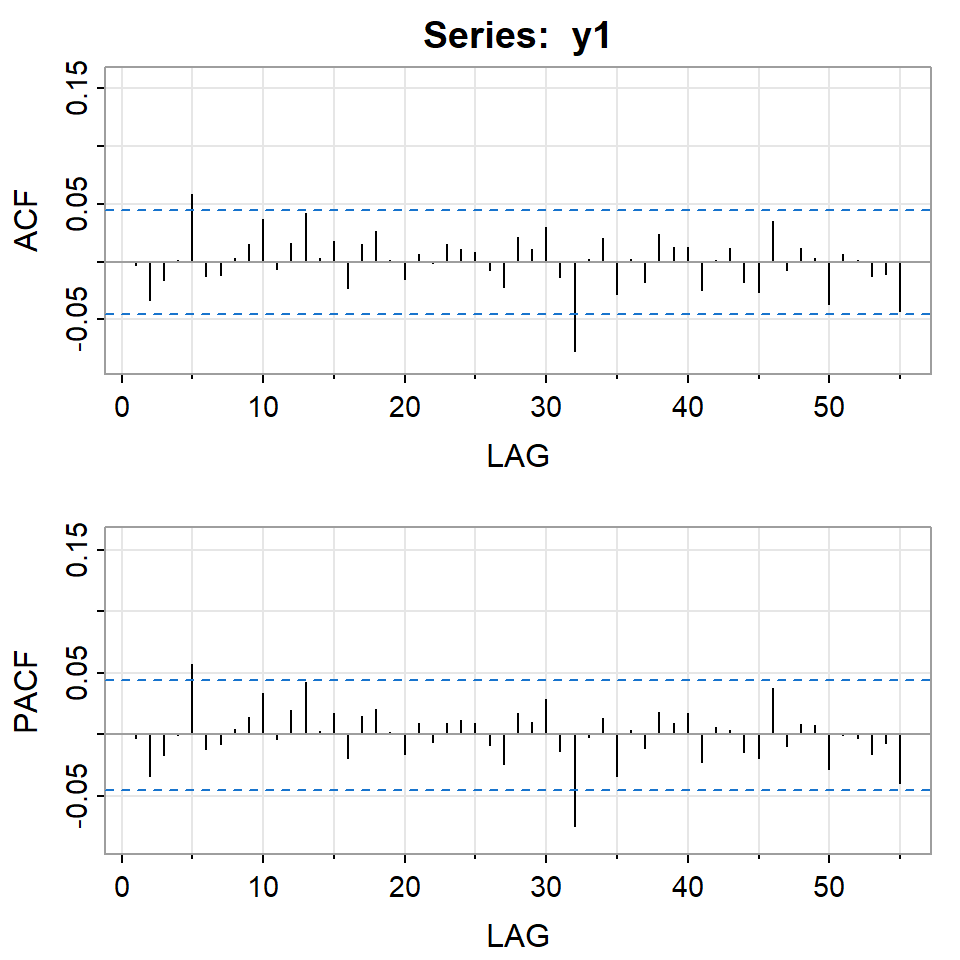
Si elevamos al cuadrado la serie simulada \(X_t\).
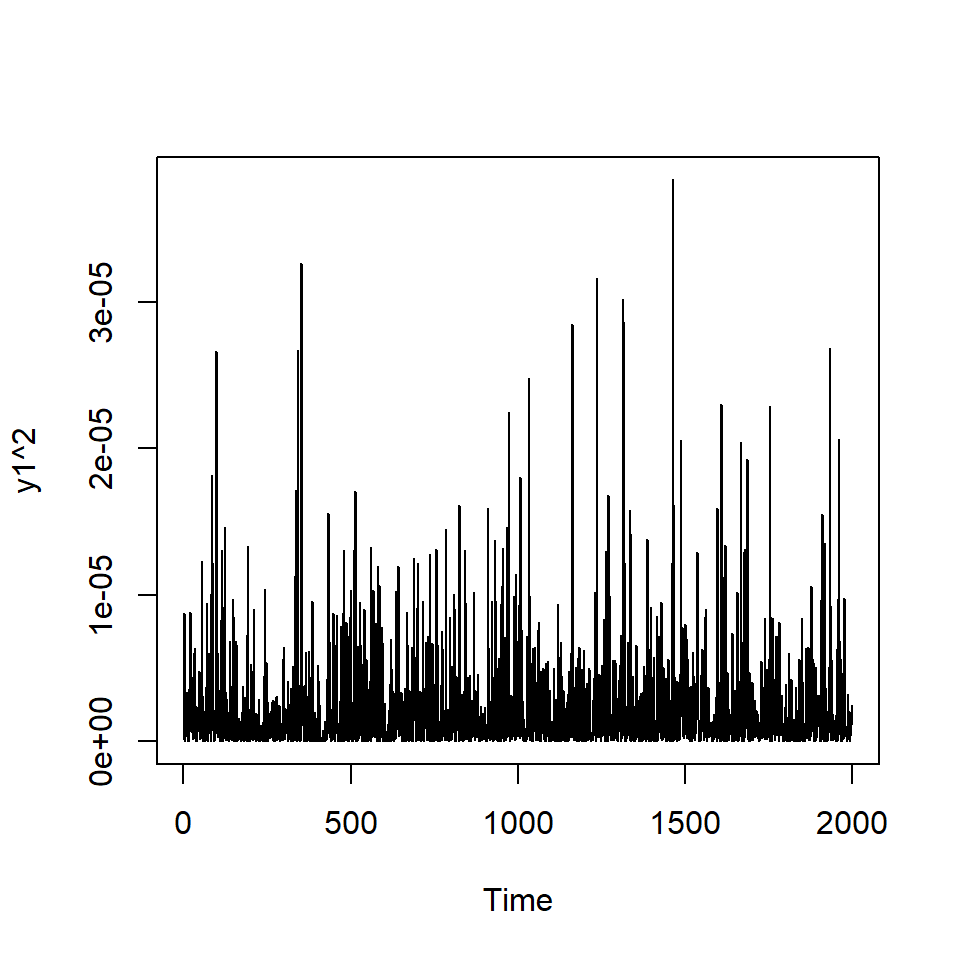
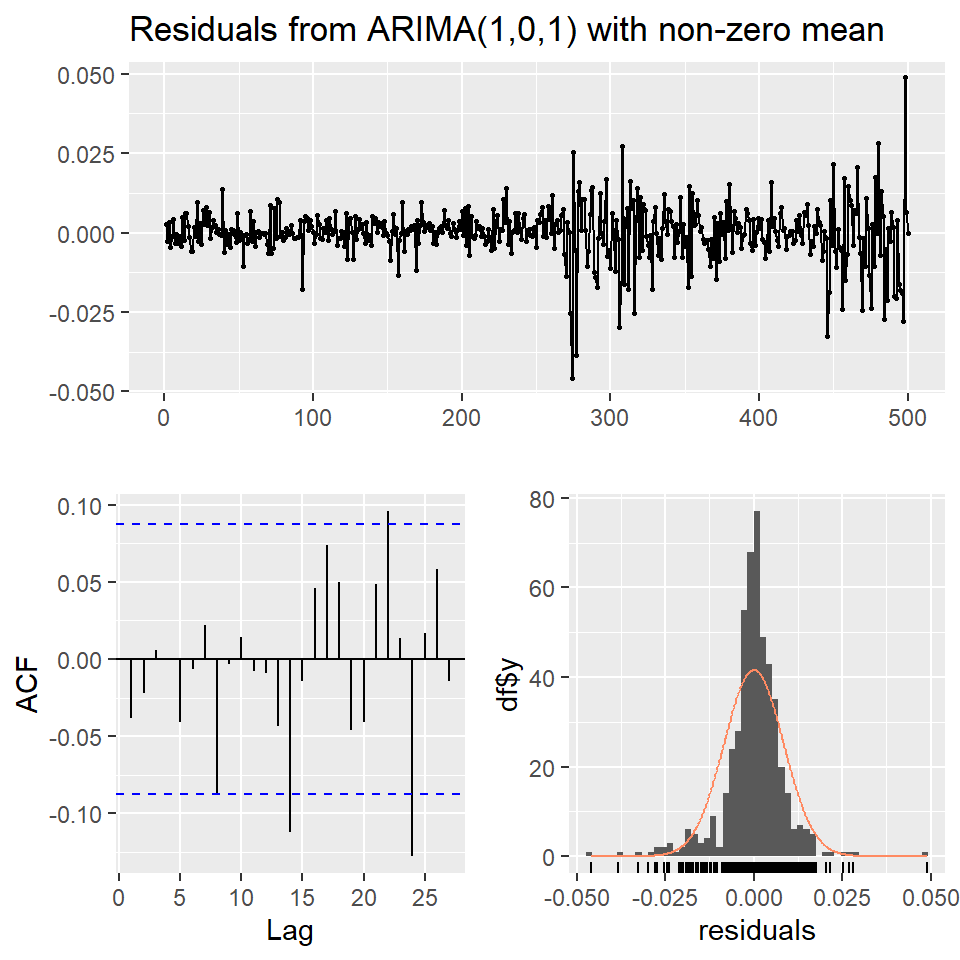
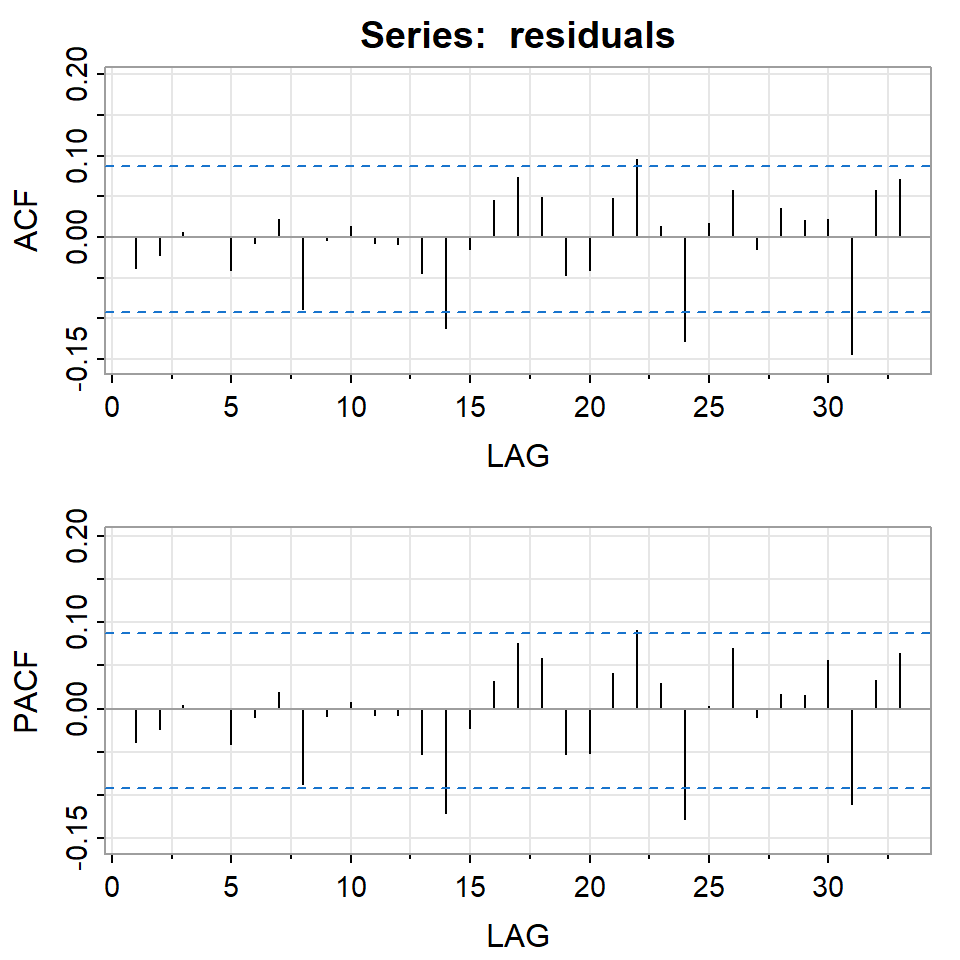
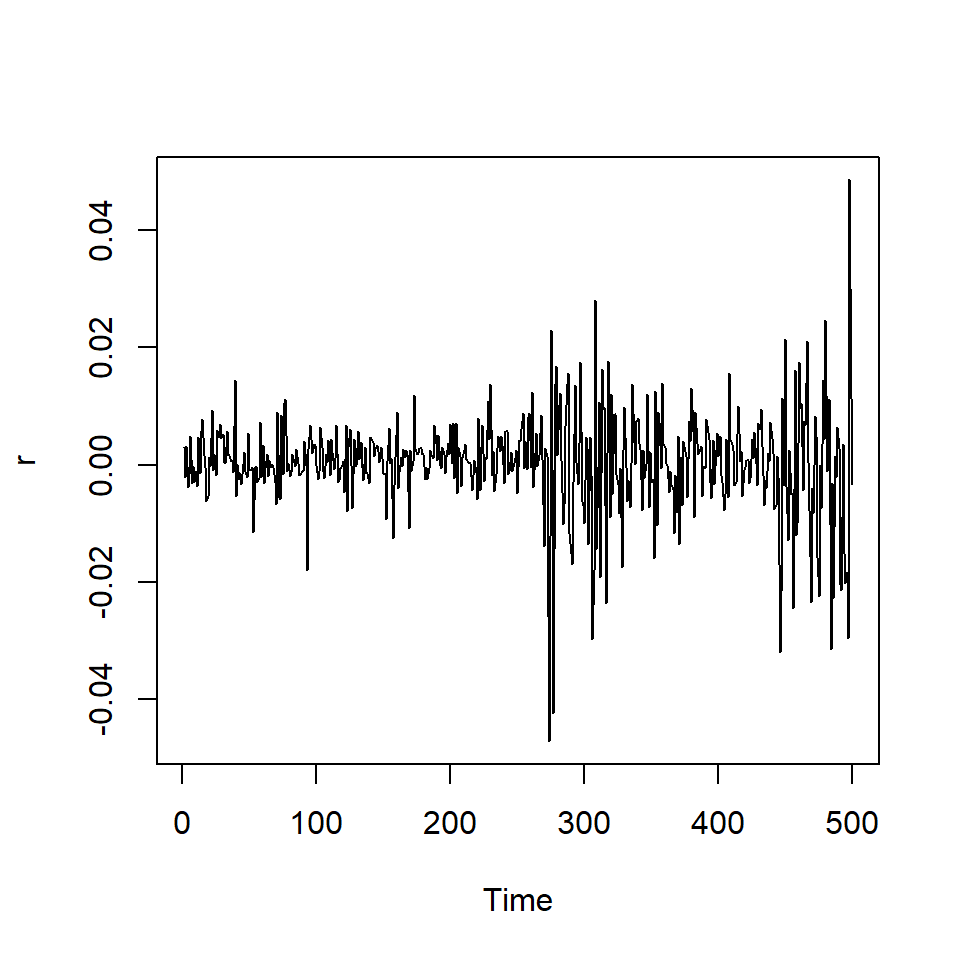
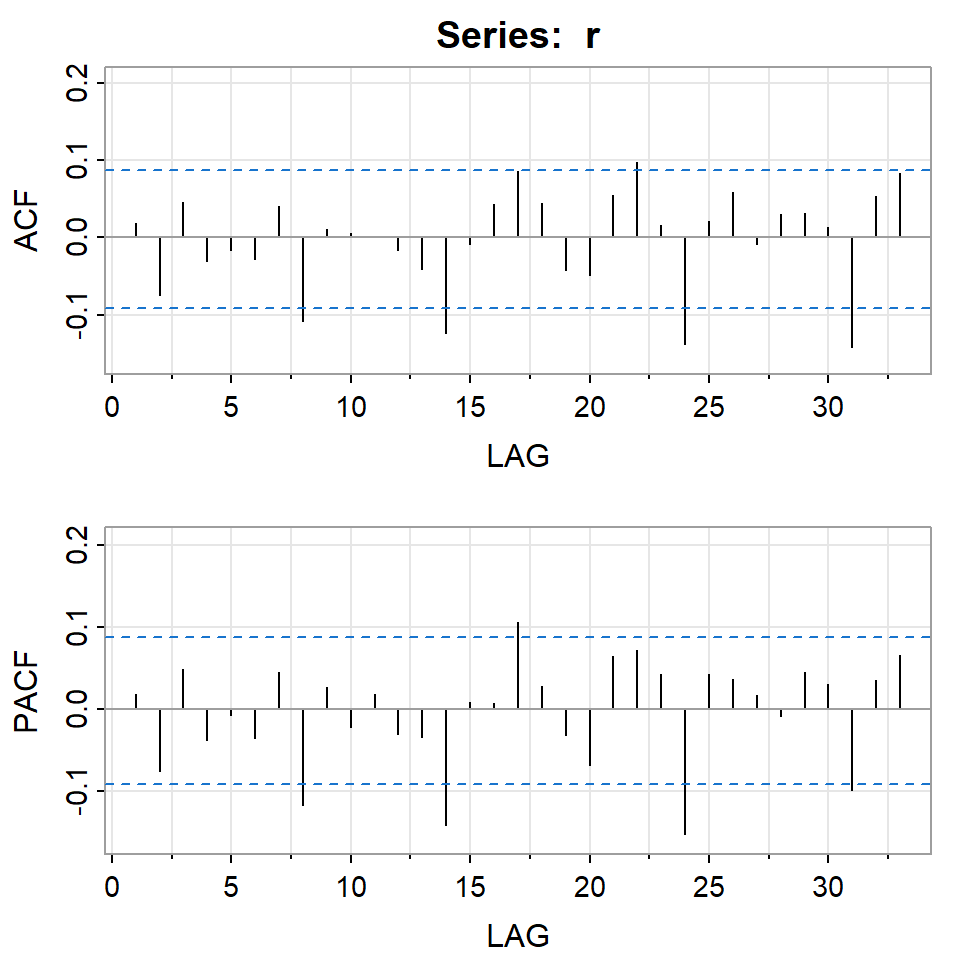
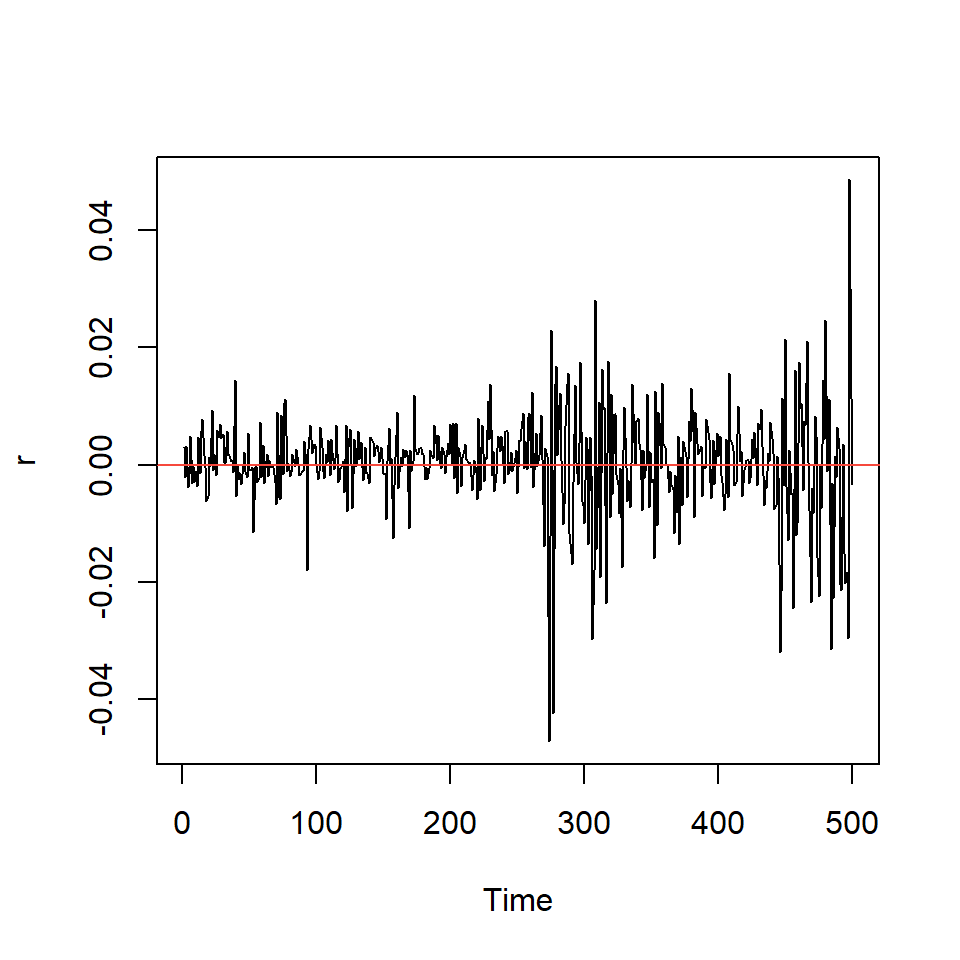
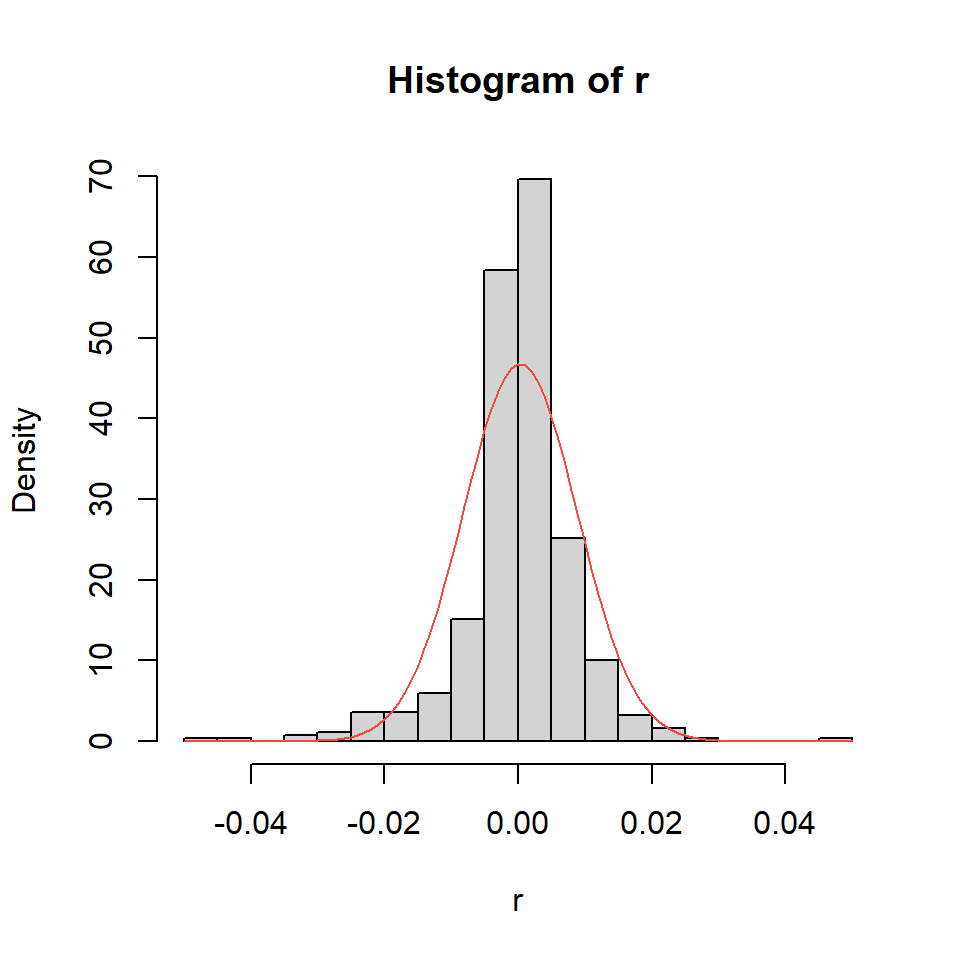
Ejemplo: promedio diario industrial Dow Jone
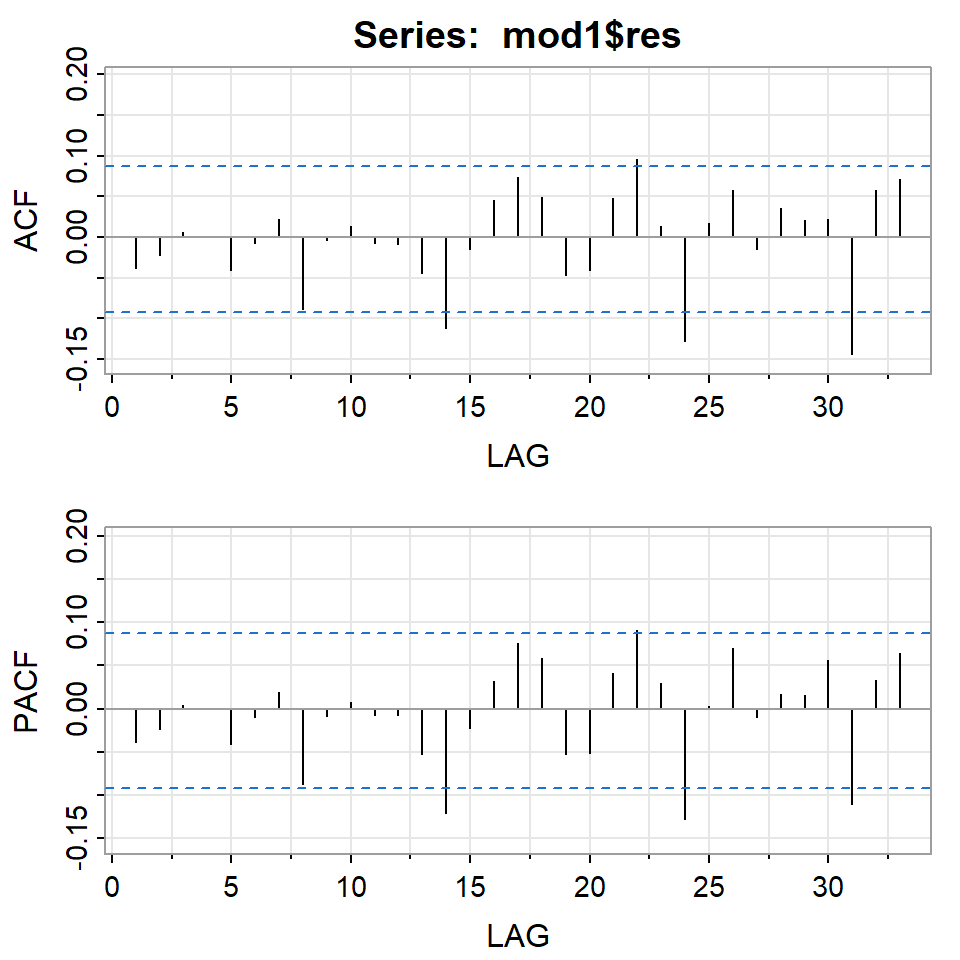
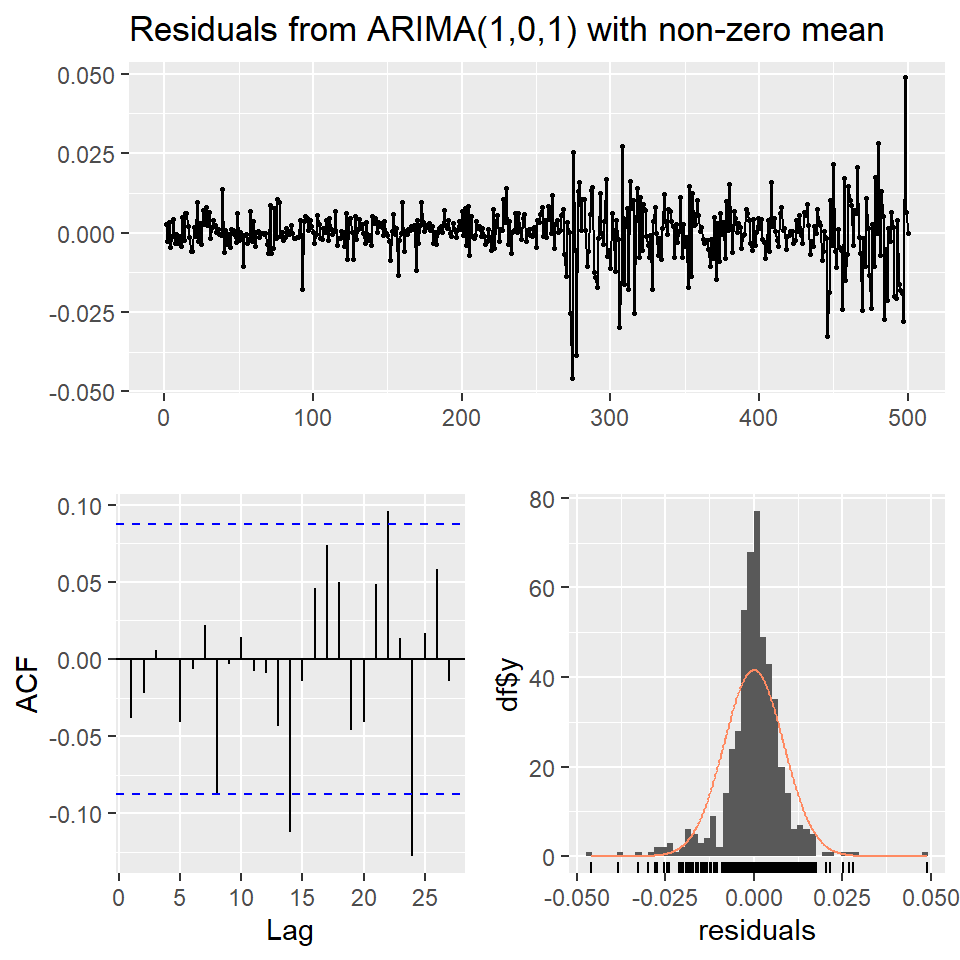
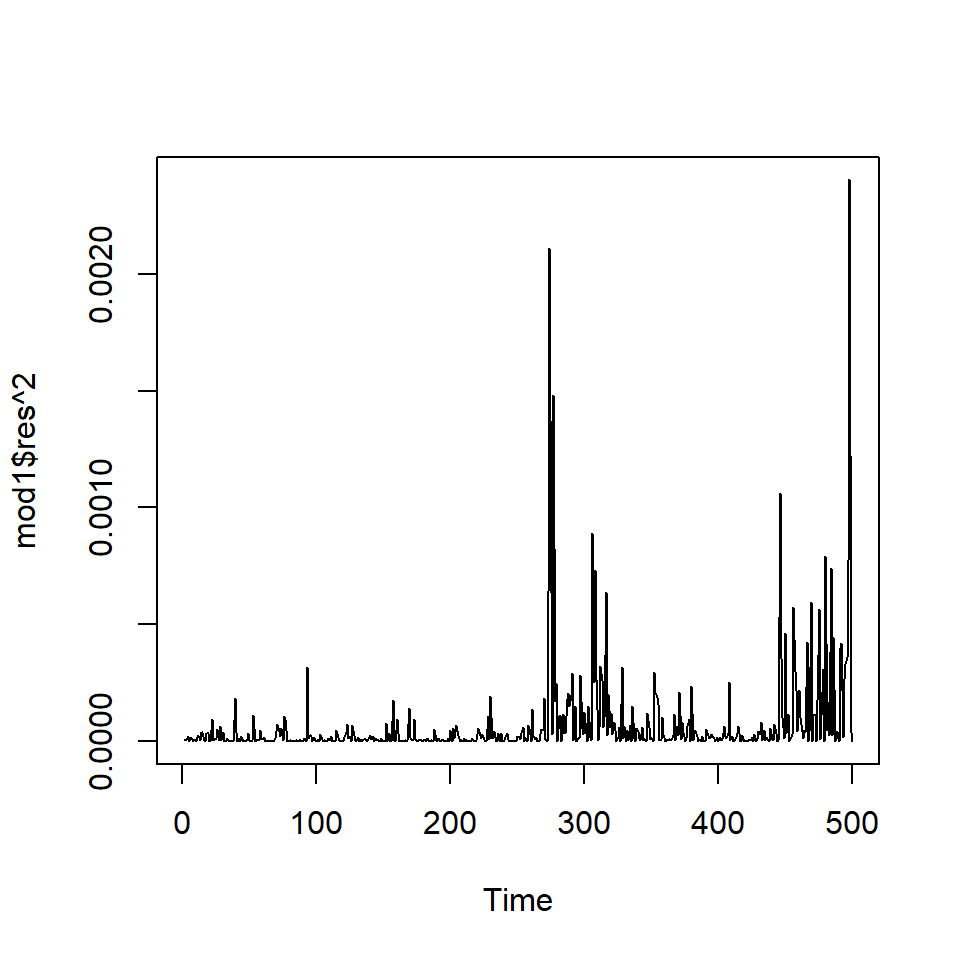
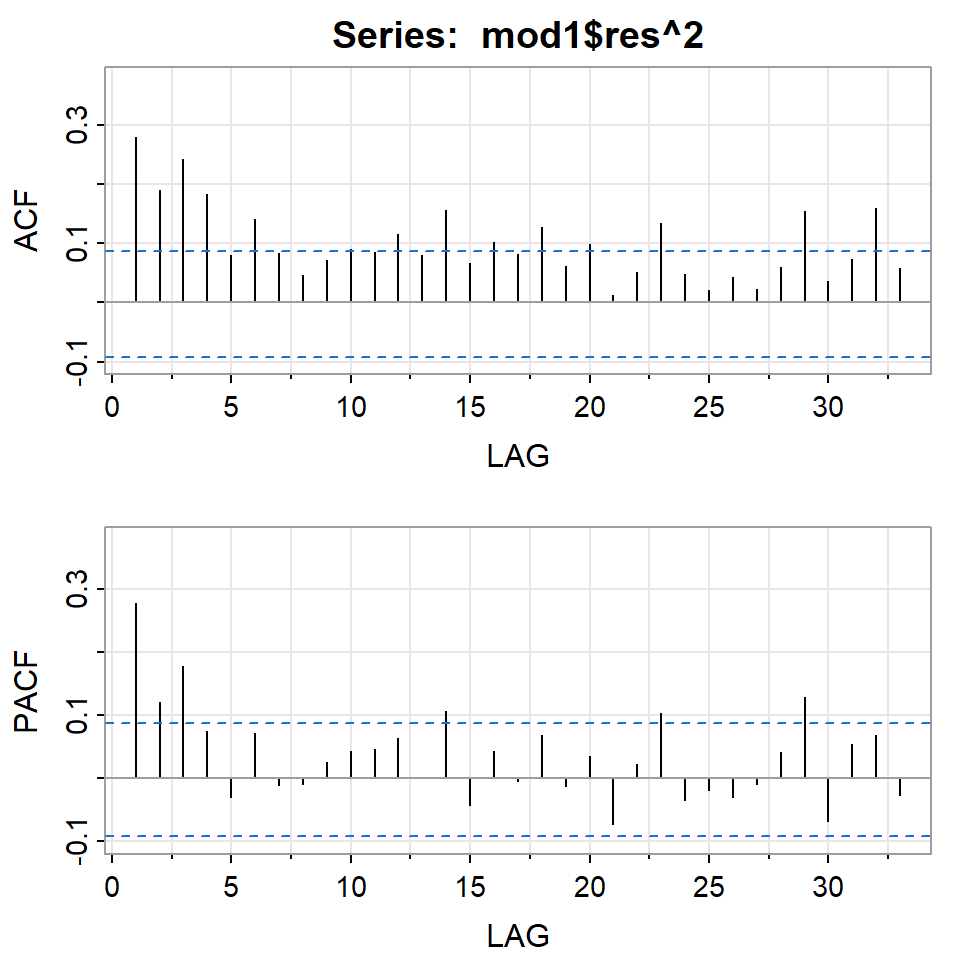
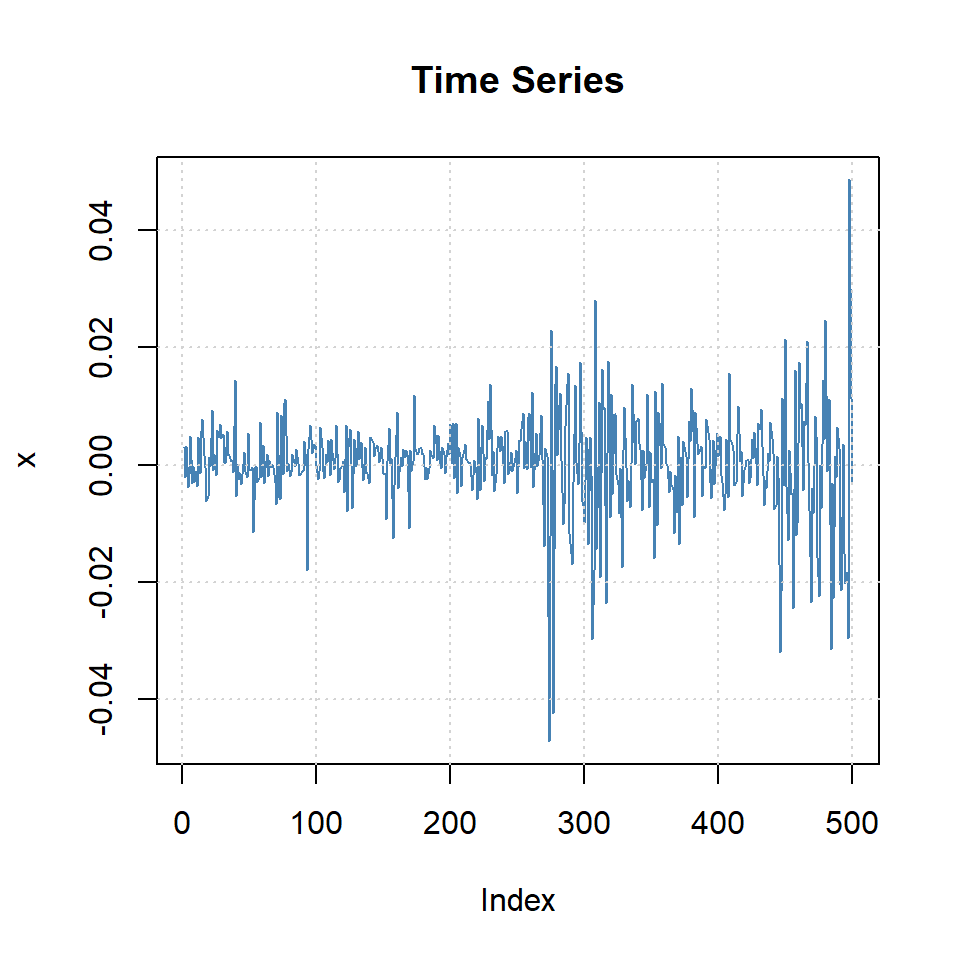
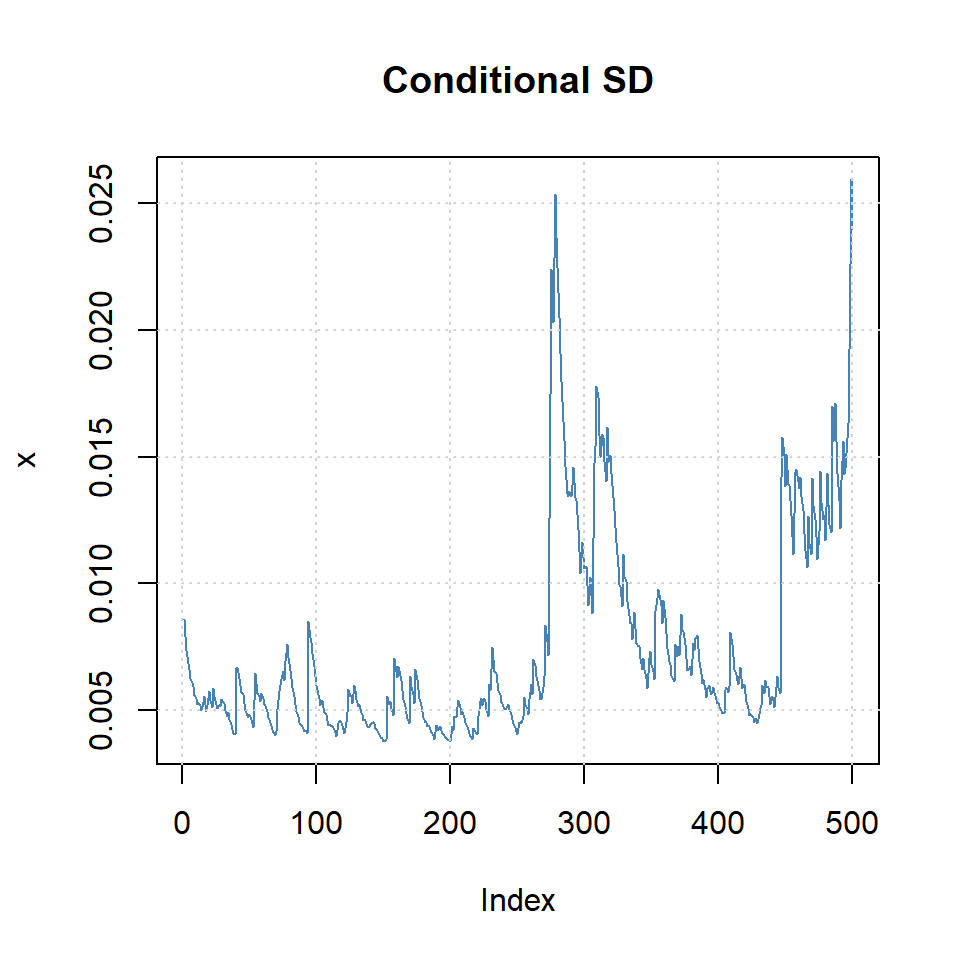
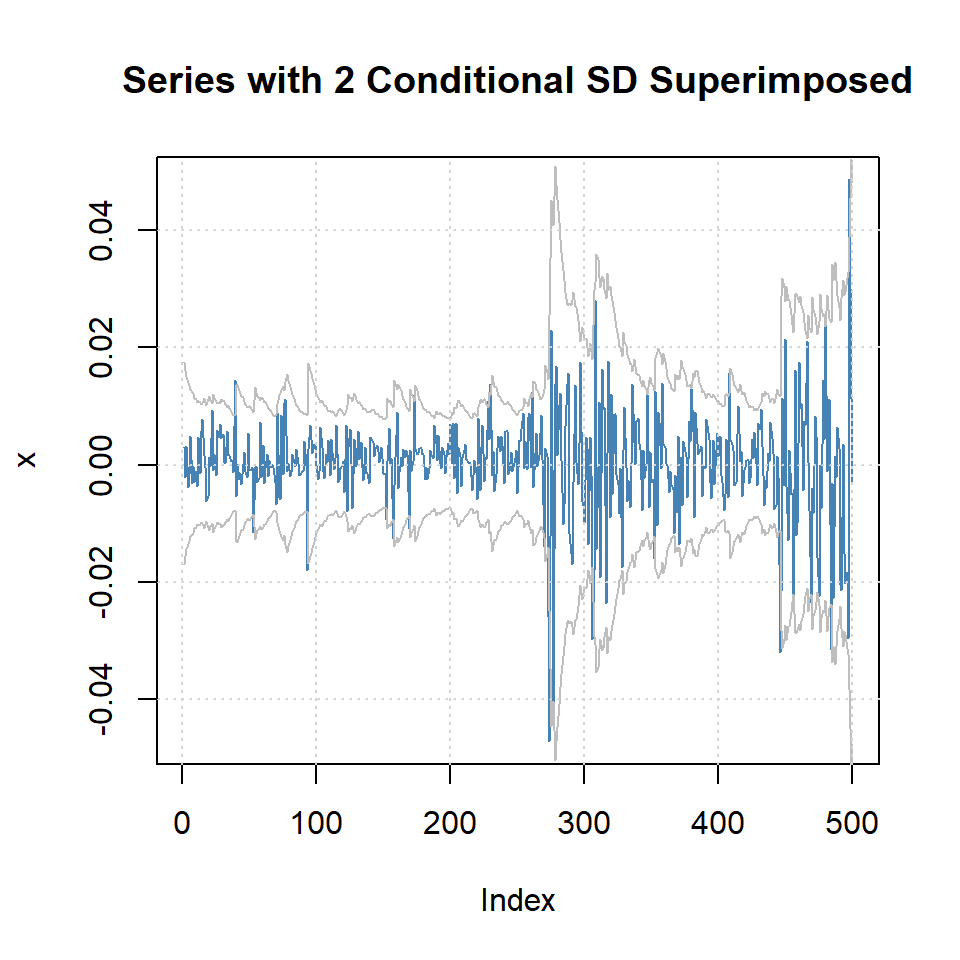
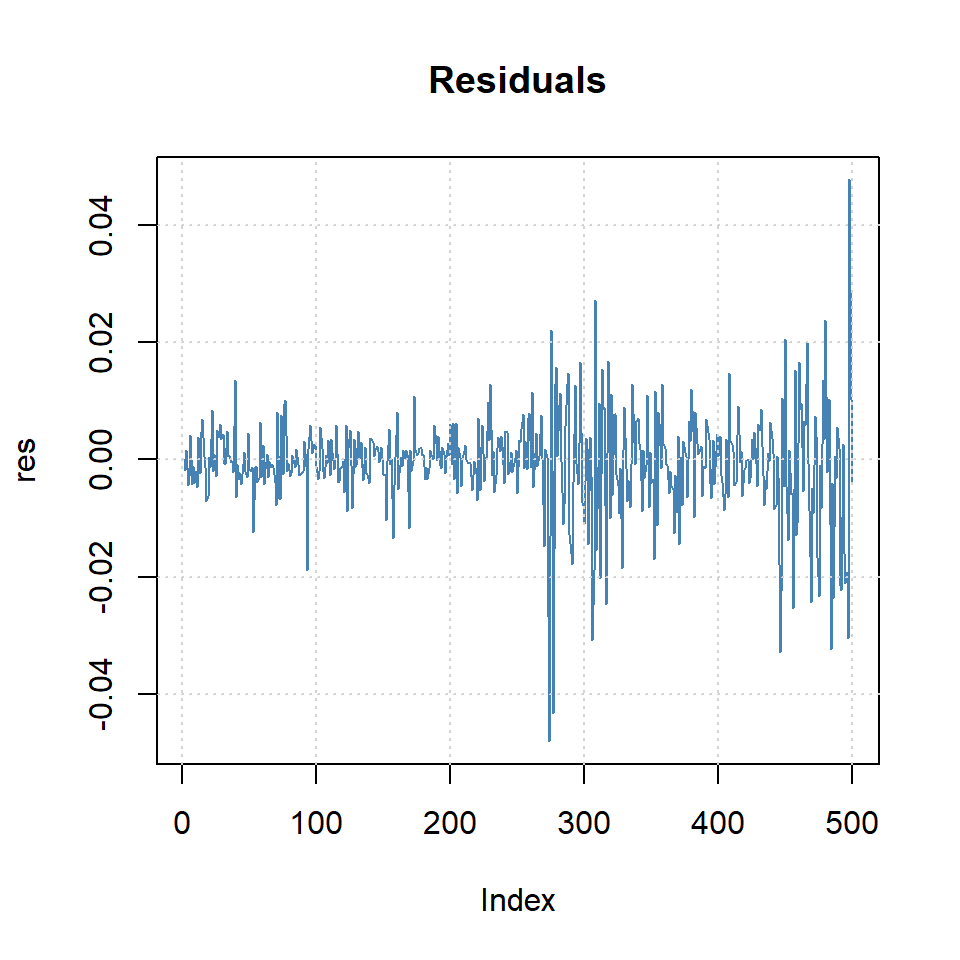
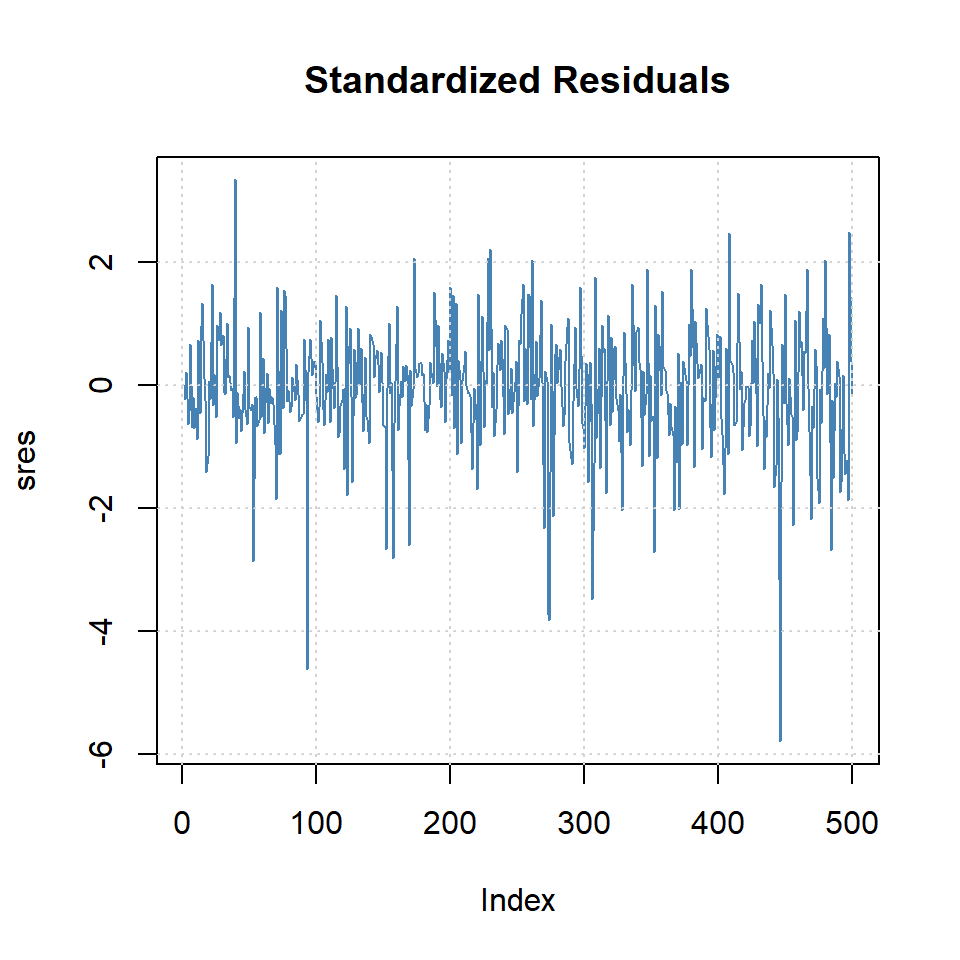
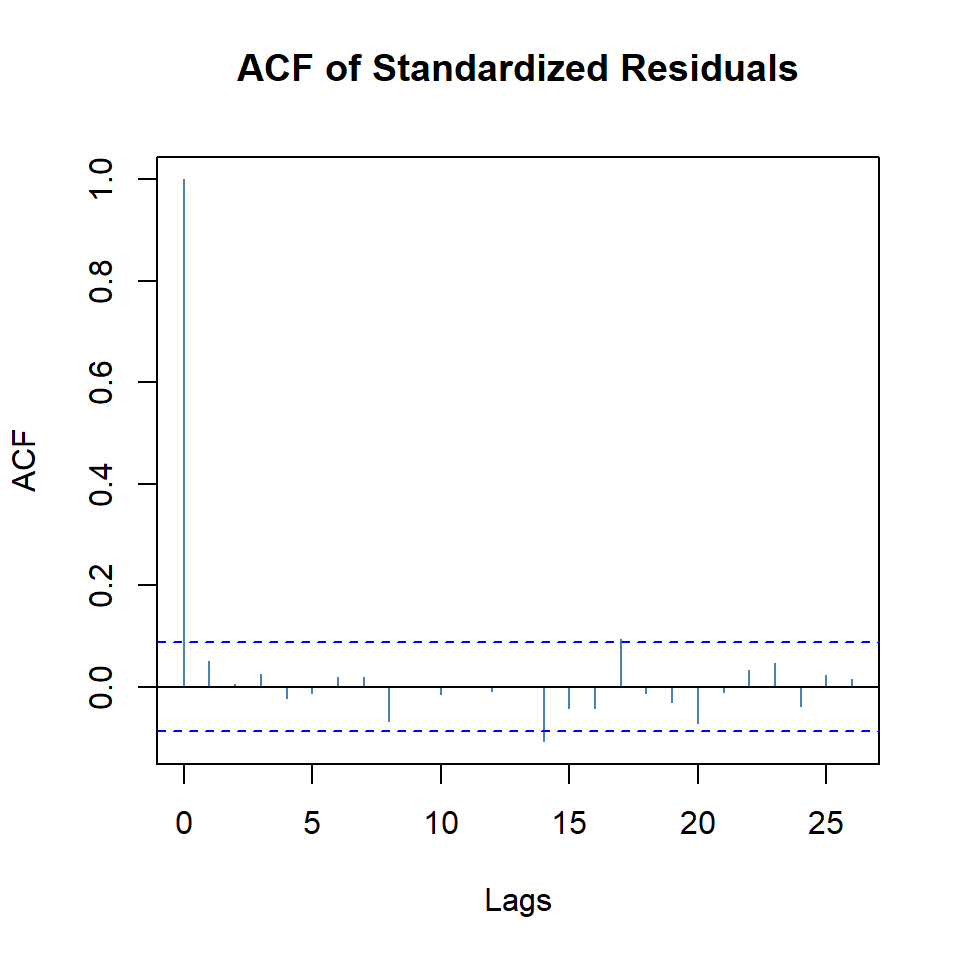
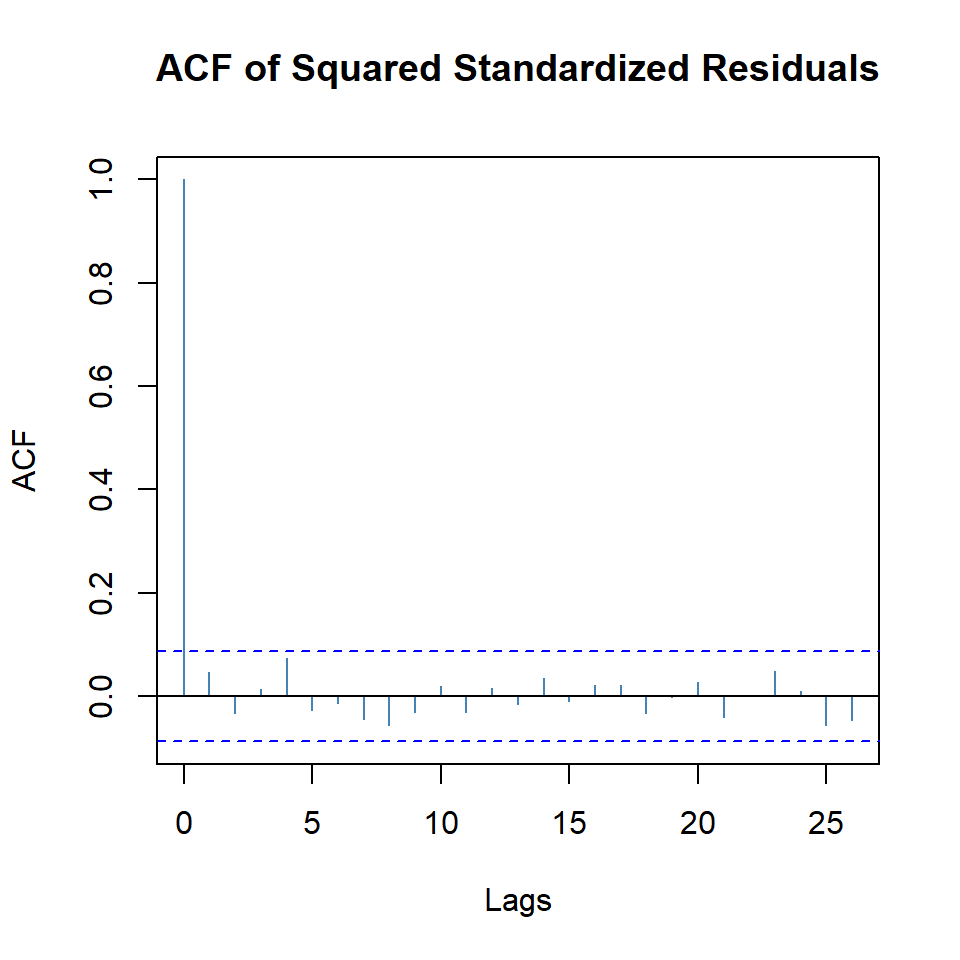
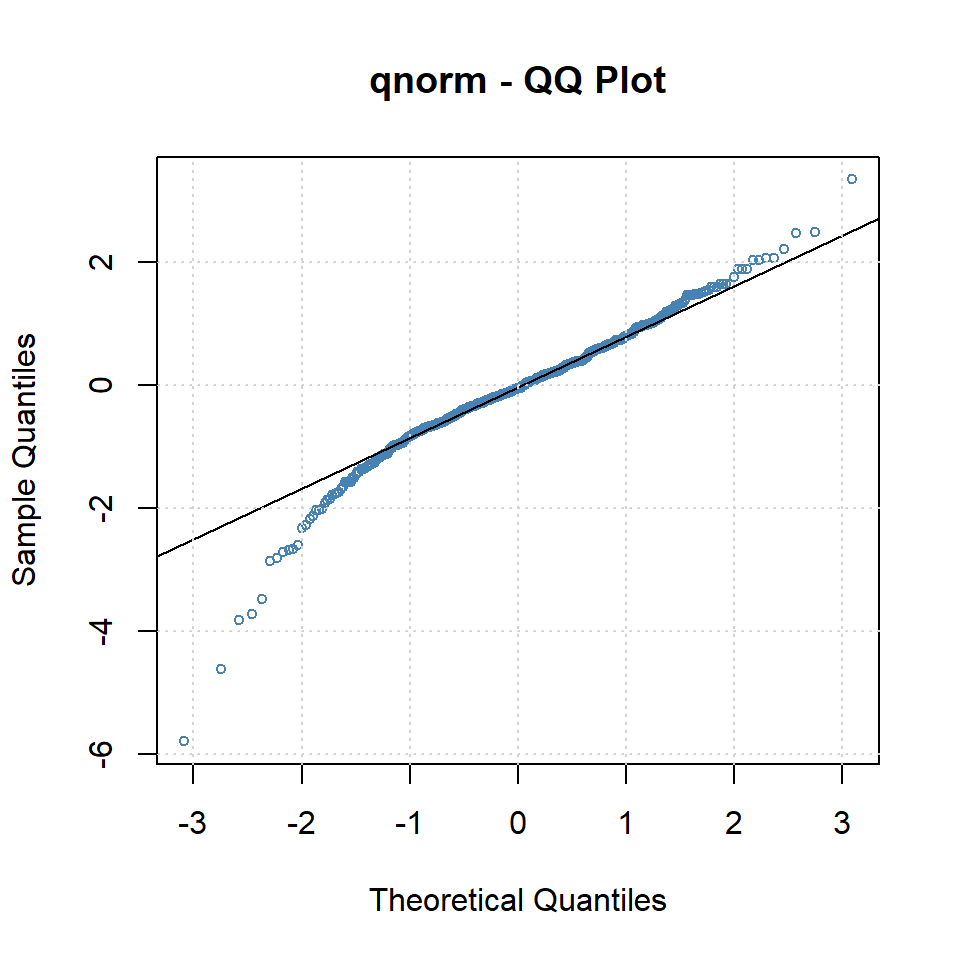
Estimate Std. Error t value Pr(>|t|)
mu 0.0010 0.0003 3.6563 0.0003
omega 0.0000 0.0000 2.2971 0.0216
alpha1 0.1594 0.0397 4.0151 0.0001
beta1 0.8285 0.0426 19.4699 0.0000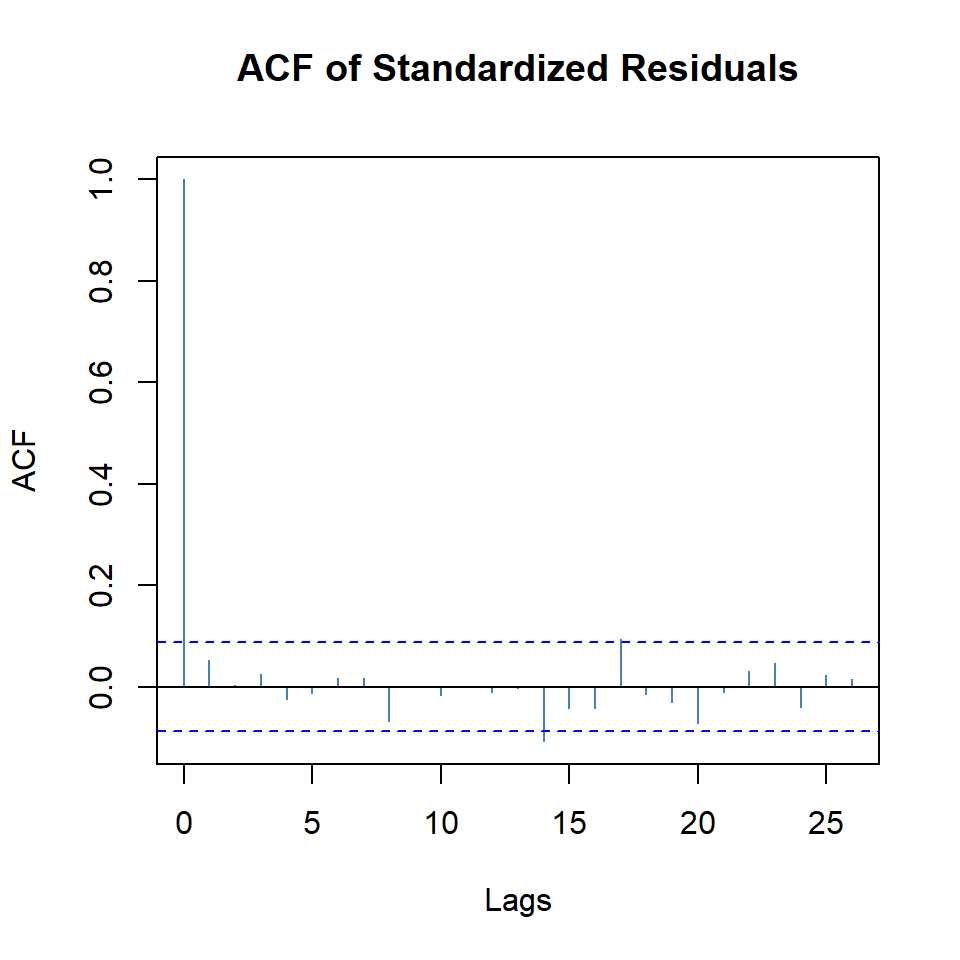
Ejemplo: promedio diario industrial Dow Jone
Distribución normal asimétrica
- La función de densidad de una normal estandarizada:
\[f(x)=\frac{1}{\sqrt{2 \pi}}e^{\frac{-1}{2}x^2},~~x \in \mathbb{R}\]
x <- seq(-3,3,0.01)
norm <- dnorm(x, mean = 0, sd = 1, log = FALSE)
snorm.p <- dsnorm(x, mean = 0, sd = 1, xi = 1.5, log = FALSE)
snorm.n <- dsnorm(x, mean = 0, sd = 1, xi = 0.5, log = FALSE)
plot(x,norm,type="l",col=1,ylim=c(0,0.8))
points(x,snorm.p,type="l",col=2)
points(x,snorm.n,type="l",col=3)
legenda=c("norm",TeX(r'(snorm $\gamma = 1.5$)'),TeX(r'(snorm $\gamma = 0.5$)'))
legend("topright",legenda ,col=c(1,2,3),lty=c(1))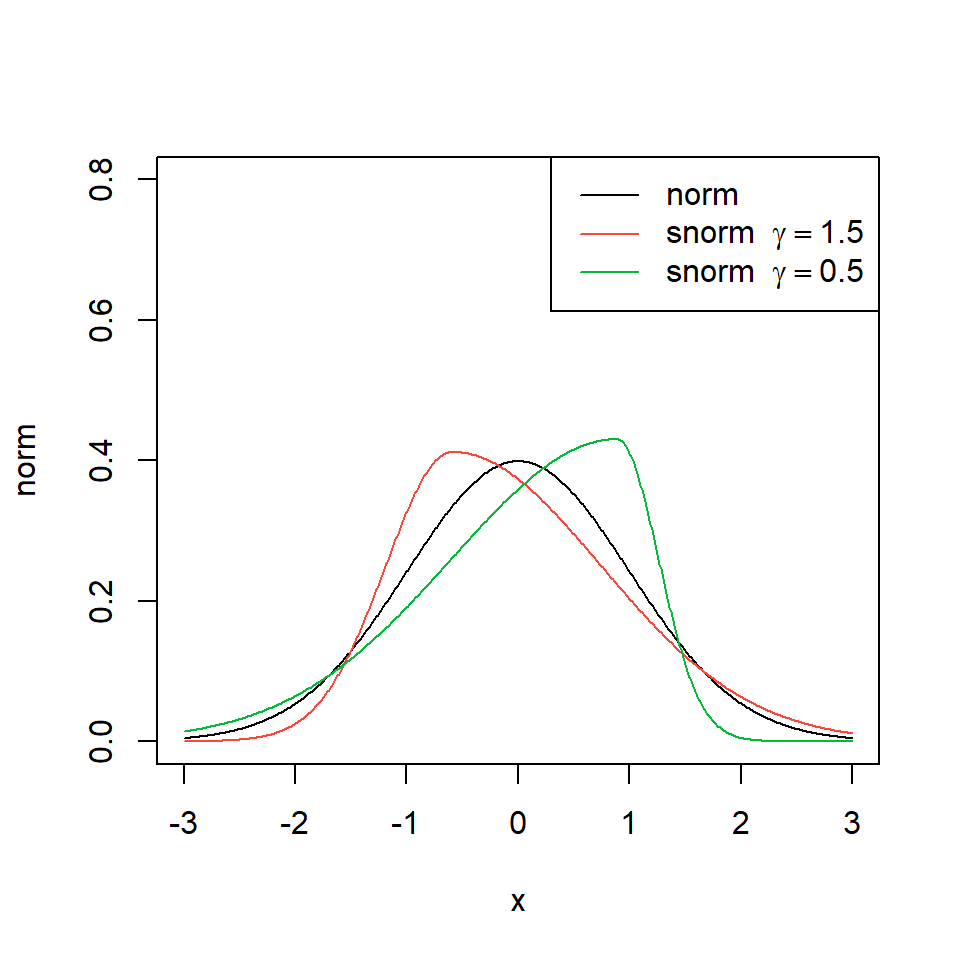
Distribución t-student asimétrica
- La función de densidad de una t-student estandarizada:
\[f(t)=\frac{\Gamma(\frac{\nu+1}{2})}{\Gamma(\sqrt{\nu \pi}\frac{\nu}{2})}\left( 1+\frac{t^2}{\nu}\right)^{-(\nu+1)/2},\]
y \(t \in \mathbb{R}\)
x <- seq(-3,3,0.01)
norm <- dnorm(x, mean = 0, sd = 1, log = FALSE)
std <- dsstd(x, mean = 0, sd = 1, nu = 4, xi = 1, log = FALSE)
sstd.p <- dsstd(x, mean = 0, sd = 1, nu = 4, xi = 1.5, log = FALSE)
sstd.n <- dsstd(x, mean = 0, sd = 1, nu = 4, xi = 0.5, log = FALSE)
plot(x,norm,type="l",col=1,ylim=c(0,1))
points(x,std,type="l",col=2)
points(x,sstd.p,type="l",col=3)
points(x,sstd.n,type="l",col=4)
legenda=c("norm",TeX(r'(st $\gamma = 1$)'),TeX(r'(st $\gamma = 1.5$)'),TeX(r'(st $\gamma = 0.5$)'))
legend("topright",legenda ,col=c(1,2,3,4),lty=c(1))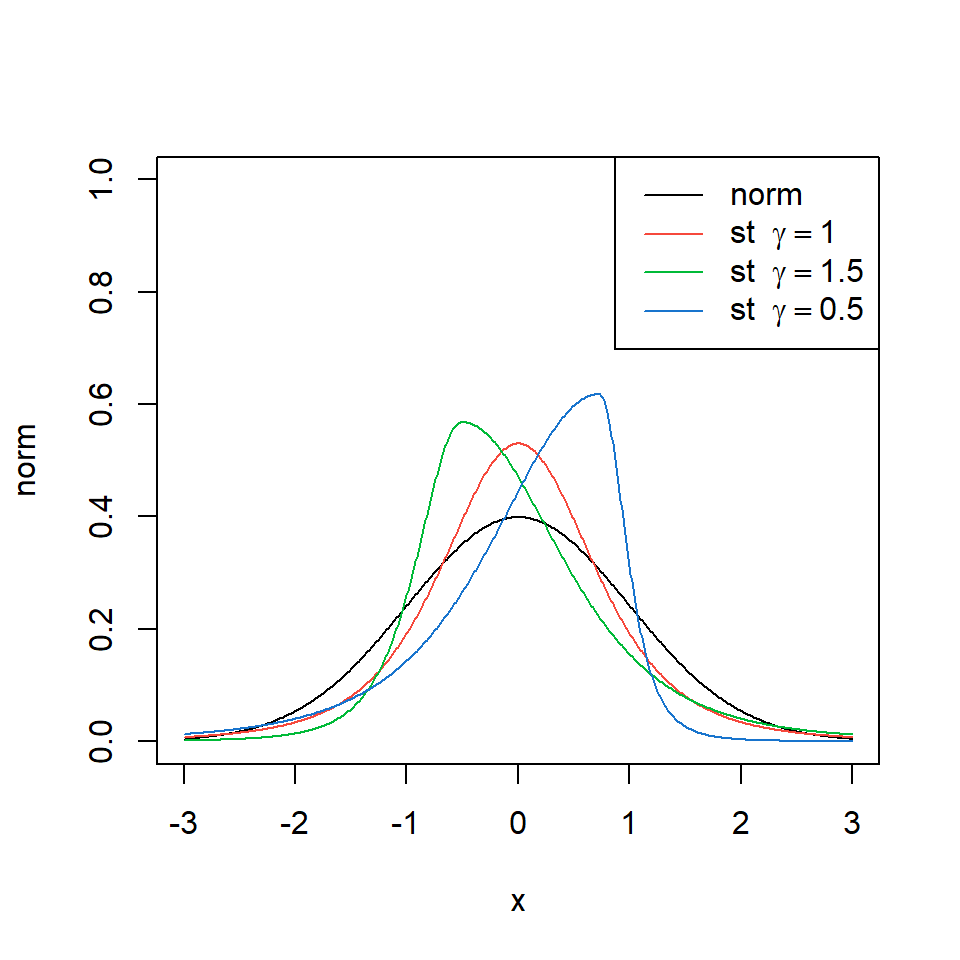
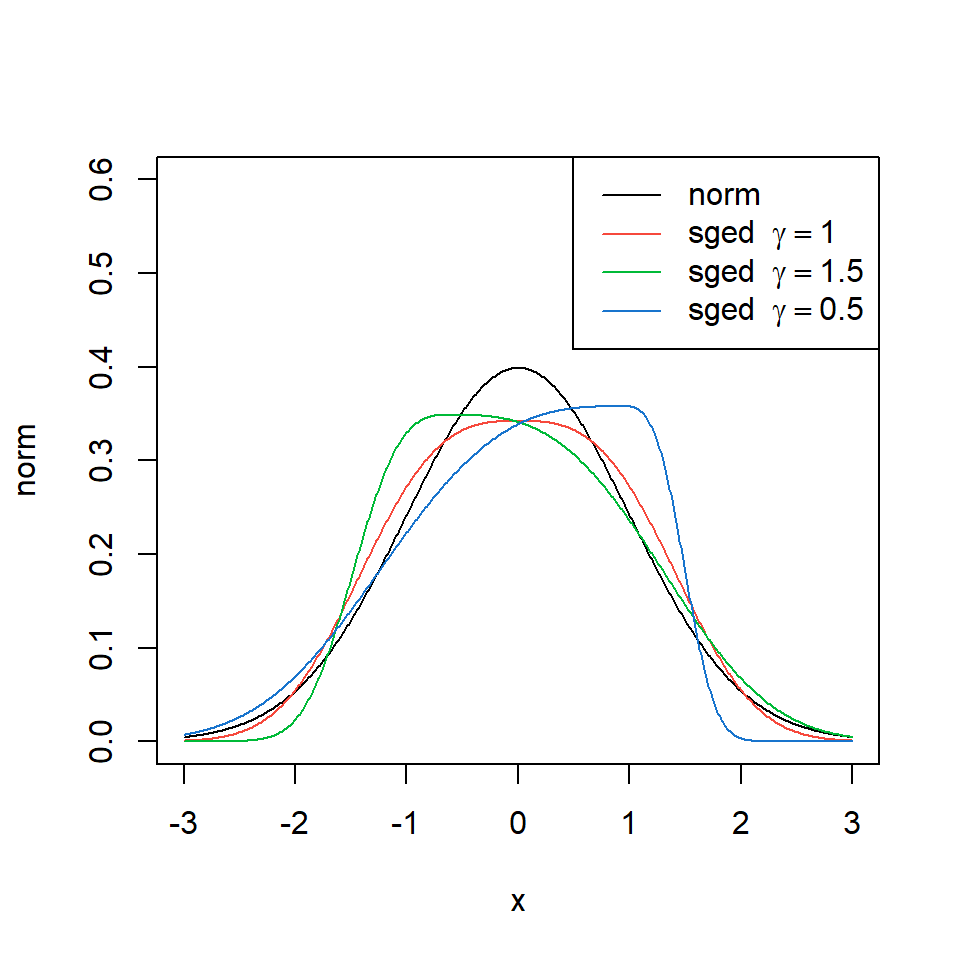
Distribución de error generalizada
- Considere una distribución de error generalizada con \(\mu=0, \alpha=1, \beta=3\) y su versión asimétrica con \(\gamma\).
x <- seq(-3,3,0.01)
norm <- dnorm(x, mean = 0, sd = 1, log = FALSE)
sged <- dsged(x, mean = 0, sd = 1, nu = 3, xi = 1, log = FALSE)
sged.p <- dsged(x, mean = 0, sd = 1, nu = 3, xi = 1.5, log = FALSE)
sged.n <- dsged(x, mean = 0, sd = 1, nu = 3, xi = 0.5, log = FALSE)
plot(x,norm,type="l",col=1,ylim=c(0,0.6))
points(x,sged,type="l",col=2)
points(x,sged.p,type="l",col=3)
points(x,sged.n,type="l",col=4)
legenda=c("norm",TeX(r'(sged $\gamma = 1$)'),TeX(r'(sged $\gamma = 1.5$)'),TeX(r'(sged $\gamma = 0.5$)'))
legend("topright",legenda ,col=c(1,2,3,4),lty=c(1))