XS3310 Teoría Estadística
I Semestre 2023
Escuela de Estadística
06-06-2023
¿Qué hemos visto hasta ahora?
Introducción a la Estadística Bayesiana: filosofía, historia y un poco de cálculo.
¿Qué vamos a discutir hoy?
Distribuciones previas
Aclaración de parametrización
Para facilitar algunos cálculos en este tema estaremos usando una parametrización alterna de la Gamma (y por ende de la ji-cuadrado y la Exponencial). Anteriormente si teníamos una Gamma(α,β) su función de densidad venía dada por
fX(x)=xα−1e−xββαΓ(α)six>0
Con la nueva parametrización que vamos a estar utilizando, la función de densidad vendría dada de la siguiente manera
fX(x)=βαxα−1e−βxΓ(α)six>0
Noten que la única diferencia es que el β de la nueva parametrización, llamémoslo β′ por un momento, es el inverso multiplicativo del beta de la parametrización vieja. Es decir, β′=1β. Por lo tanto, para la nueva parametrización de la Gamma tenemos que E(X)=αβ y Var(X)=αβ2.
Densidades previas conjugadas y estimadores de Bayes
Distribución previa (distribución a priori)
Suponga que tenemos un modelo estadístico con parámetro θ. Su θ es aleatorio entonces su densidad (antes de observar cualquier muestra) se llama densidad previa: π.
Ejemplo: X1,…,Xn∼Exp(θ) y θ es aleatorio tal que θ∼Γ(α1,β2) entonces
π(θ)=1Γ(α)βαθα−1eβθ=2e−2θ,θ>0
Ejemplo: Sea θ la probabilidad de obtener cara al tirar una moneda.
En este caso antes de modelar exactamente el θ, lo importante es modelar el tipo de moneda. Es decir, supongamos que tenemos dos opciones
Moneda justa: θ=12 con probabilidad previa 0.8 (π(12)=0.8).
Moneda con solo una cara: θ=1 con probabilidad previa 0.2 (π(1)=0.2).
En este ejemplo si tuviéramos 100 monedas con probabilidad previa π entonces 20 tendrían solo una cara y 80 serían monedas normales.
Notas:
π está definida en Ω (espacio paramétrico).
π es definida antes de obtener la muestra.
Ejemplo (Componentes eléctricos) Supoga que se quiere conocer el tiempo de vida de cierto componente eléctrico. Sabemos que este tiempo se puede modelar con una distribución exponencial con parámetro θ desconocido. Este parámetro asumimos que tiene una distribución previa Gamma.
Un experto en componentes eléctricos conoce mucho de su área y sabe que el parámetro θ tiene las siguientes características:
E[θ]=0.0002,√Var(θ)=0.0001.
Como sabemos que la previa π es Gamma, podemos deducir lo siguiente:
E[θ]=αβ,Var(θ)=αβ2
⟹{αβ=2×10−4√αβ2=1×10−4⟹β=20000,α=4
Notación:
X=(X1,…,Xn): vector que contiene la muestra aleatoria.
Densidad conjunta de X: fθ(x).
Densidad de X condicional en θ: fn(x|θ).
Supuesto: X viene de una muestra aleatoria si y solo si X es condicionalmente independiente dado θ.
Consecuencia: fn(X|θ)=f(X1|θ)⋅f(X2|θ)⋯f(Xn|θ)
Ejemplo
Si X=(X1,…,Xn) es una muestra tal que Xi∼Exp(θ),
fn(X|θ)={∏ni=1θe−θXisi Xi>00si no={θne−θ∑ni=1XiXi>00si no
Densidad posterior
Definición. Considere un modelo estadístico con parámetro θ y muestra aleatoria X1,…,Xn. La densidad condicional de θ dado X1,…,Xn se llama densidad posterior: π(θ|X)
Teorema. Bajo las condiciones anteriores:
π(θ|X)=f(X1|θ)⋯f(Xn|θ)π(θ)gn(X)
para θ∈Ω, donde gn es una constante de normalización.
Prueba:
π(θ|X)=π(θ,X)marginal de X=π(θ,X)∫π(θ,X)dθ=P(X|θ)⋅π(θ)∫π(θ,X)dθfn(X|θ)⋅π(θ)gn(X)=f(X1|θ)⋯f(Xn|θ)π(θ)gn(X)
Del ejemplo anterior,
fn(X|θ)=θne−θy,y=∑Xi (estadístico)
- Numerador:
fn(X|θ)π(θ)=θne−θy⏟fn(X|θ)⋅20000043!θ3e−20000⋅θ⏟π(θ)=2000043!θn+3e(20000+y)θ
- Denominador:
gn(x)=∫+∞0θn+3e−(20000+y)θdθ=Γ(n+4)(20000+y)n+4
Entonces la posterior corresponde a π(θ|X)=θn+3e−(20000+y)θΓ(n+4)(20000+y)n+4 que es una Γ(n+4,20000+y).
Con 5 observaciones (horas): 2911, 3403, 3237, 3509, 3118. y=5∑i=1Xi=16178,n=5 por lo que θ|X∼Γ(9,36178)
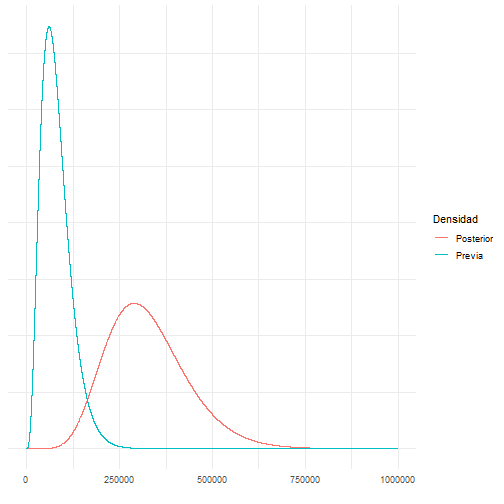
Es sensible al tamaño de la muestra (una muestra grande implica un efecto de la previa menor).
Hiperparámetros: parámetros de la previa o posterior.
Proceso de modelación de parámetros.
De ahora en adelante vamos a entender un modelo como el conjunto de los datos X1,…,Xn, la función de densidad f y el parámetro de la densidad θ. Estos dos últimos resumen el comportamiento de los datos.
Ahora para identificar este modelo se hace por partes,
- La información previa π(θ) es la información extra o basado en la experiencia que tengo del modelo.
- Los datos es la información observada. La función de densidad f filtra y mejora la información de la previa.
- La densidad posterior es la "mezcla" entre la información y los datos observados. Es una versión más informada de la distribución del parámetro.
Función de verosimilitud
Bajo el modelo estadístico anterior a fn(X|θ) se le llama verosimilitud o función de verosimilitud.
Observación. En el caso de una función de verosimilitud, el argumento es θ.
Ejemplo.
Sea θ la proporción de aparatos defectuosos, con θ∈[0,1]
Xi={0falló1no falló
{Xi}ni=1 es una muestra aleatoria y Xi∼Ber(θ).
- Verosimilitud
fn(X|θ)=n∏i=1f(Xi|θ)={θ∑Xi(1−θ)n−∑XiXi=0,1 ∀i0si no
Previa: π(θ)=1{0≤θ≤1}
Posterior:
Por el teorema de Bayes, π(θ|X)∝θy(1−θ)n−y⋅1=θα⏞y+1−1(1−θ)β⏞n−y+1−1⟹θ|X∼Beta(y+1,n−y+1)
- Predicción.
Supuesto: los datos son secuenciales. Calculamos la distribución posterior secuencialmente:
π(θ|X1)∝π(θ)f(X1|θ)π(θ|X1,X2)∝π(θ)f(X1,X2|θ)=π(θ)f(X1|θ)f(X2|θ) (por independencia condicional)=π(θ|X1)f(X2|θ)⋮π(θ|X1,…,Xn)∝f(Xn|θ)π(θ|X1,…,Xn−1)
Bajo independencia condicional no hay diferencia en la posterior si los datos son secuenciales.
Luego,
gn(X)=∫Ωf(Xn|θ)π(θ|X1,…,Xn−1) dθ=P(Xn|X1,…,Xn−1) (Predicción para Xn) Ejemplo.
Continuando con el ejemplo de los artefactos, P(X6>3000|X1,X2,X3,X4,X5). Se necesita calcular f(X6|X). Dado que π(θ|X)=2.6×1036θ8e−36178θ
se tiene
f(X6|X)=2.6×1036∫∞0θe−θX6⏟Densidad de X6θ8e−36178θ dθ=9.55×1041(X6+36178)10
Entonces,
P(X6>3000)=∫∞30009.55×1041(X6+36178)10dX6=0.4882
func<-function(x){9.55*10^41/(x+36178)^10}integrate(func,lower=3000,upper=Inf)## 0.4879558 with absolute error < 1.5e-05La vida mediana se calcula como 12=P(X6>u|X).
La vida media se calcula como E(X6|X)=∫∞0x6f(x6|X)dx6.
func<-function(x){x*9.55*10^41/(x+36178)^10}integrate(func,lower=0,upper=Inf)## 4519.75 with absolute error < 0.41¿Qué discutimos hoy?
Estadística Bayesiana, Distribuciones previas (a priori).
¿Qué nos falta para terminar el curso?
Tipos de distribuciones previas, estadística Bayesiana: inferencia (estimación puntual, intervalos de credibilidad y factor de Bayes).