set.seed(100000)
n <- 45
x <- rexp(n,rate=1/0.5) #Importante notar que R usa el argumento de "rate" como el inverso de beta.
hist(x)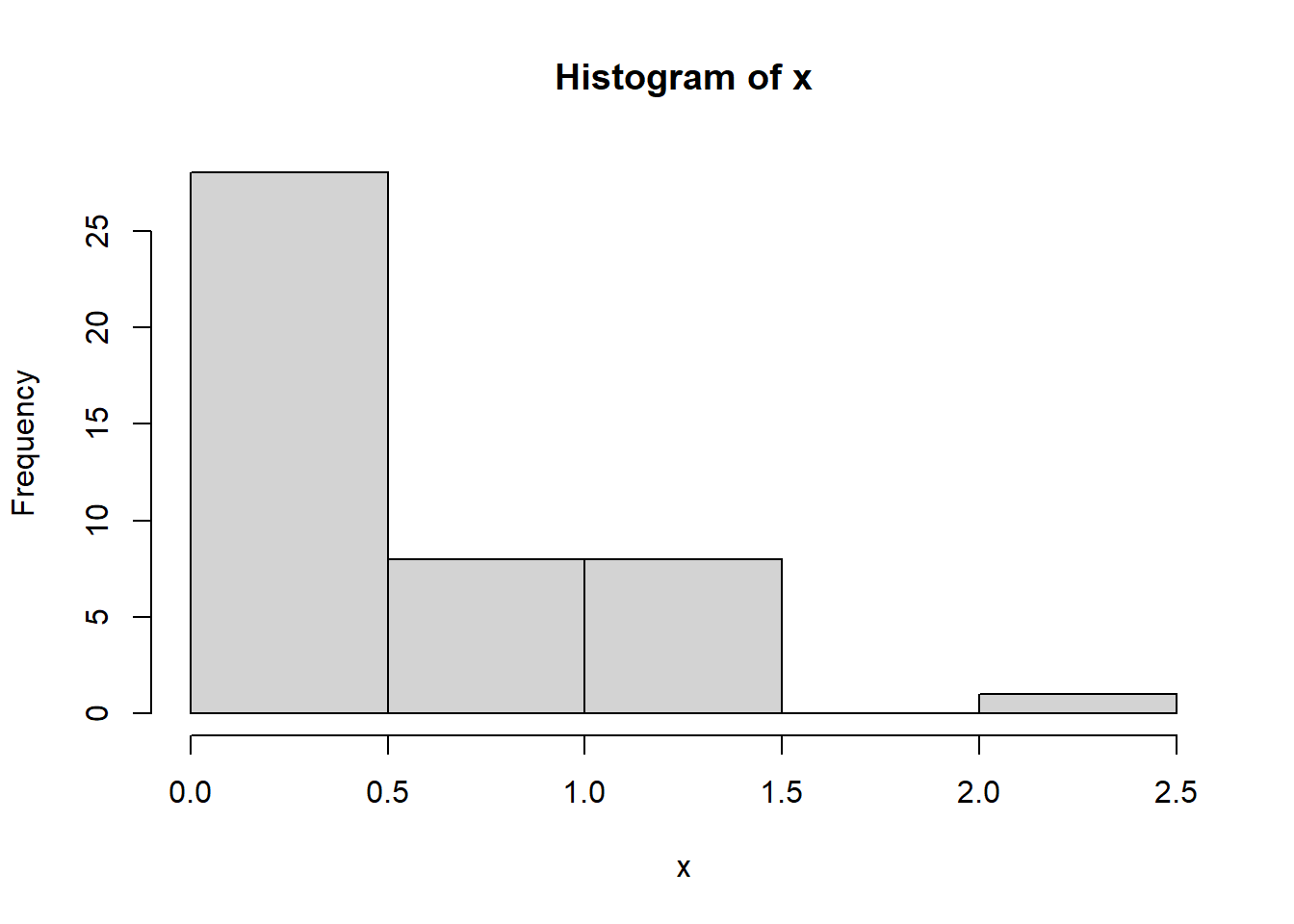
mean(x)[1] 0.4859945var(x)[1] 0.2492303XS3310 Teoría Estadística
Este documento ilustra de manera intuitiva, por medio de simulaciones, las propiedades de la media y variancia muestral, así como el Teorema de Límite Central.
Sea \(X_1,...,X_n\) una muestra aleatoria tal que \(X_i \sim Exp(\beta=0.5)\), para \(i=1,...,n\).
Una muestra aleatoria simulada con \(n=45\) se observa como sigue:
set.seed(100000)
n <- 45
x <- rexp(n,rate=1/0.5) #Importante notar que R usa el argumento de "rate" como el inverso de beta.
hist(x)
mean(x)[1] 0.4859945var(x)[1] 0.2492303Observe que teóricamente \(E(X)=0.5\) y \(Var(X)=0.5^2=0.25\). A partir de una única una muestra, el estimador \(\bar{X}\) se aproxima “razonablemente” cerca sobre el parámetro de interés \(\beta\).
Ahora, tomo \(K=1000\) muestras aleatorias a partir de una población y las guardo en una lista X.
K <- 1000
n <- 45
X <- list()
for(i in 1:K){
X[[i]] <- rexp(n,2) #X es una lista de las K muestras de tamaño 45.
}Calculo la media muestral para \(k=1,...,K\) y obtengo la media y variancia (empírica) de las \(K=1000\) medias muestrales.
media_X <- sapply(X,mean)
head(media_X)[1] 0.5168613 0.5043218 0.4169245 0.5126319 0.3547623 0.3538606Muestran las primeras 5 medias muestrales.
Nota: Como la media muestral es un estadístico y es una v.a. cada una de las \(K=1000\) repeticiones corresponde a una observación aleatoria del estimador.
El histograma (la distribución empírica) del estimador se ve como sigue:
hist(media_X)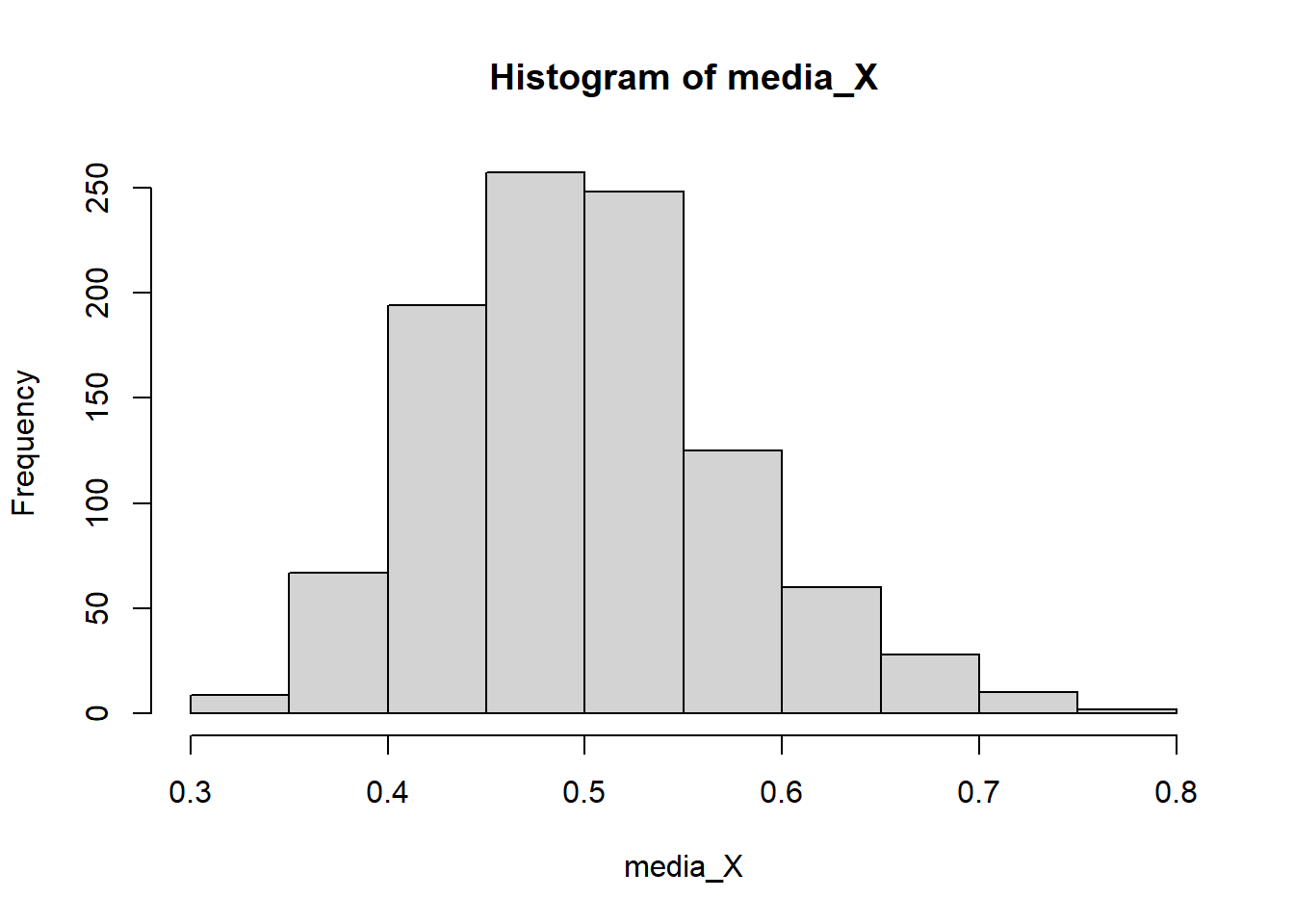
mean(media_X)[1] 0.5011449var(media_X)[1] 0.005764824Observe que teóricamente \(E(\bar{X})=0.5\) y \(Var(\bar{X})=0.5^2/n=0.5^2/45=0.00556\). Además, el histograma muestra que con la distribución muestral de \(\bar{X}\) es asimétrica positiva y no parece ser normal.
K <- 1000
n <- 10
X <- list()
for(i in 1:K){
X[[i]] <- rexp(n,2) #X es una lista de las K muestras de tamaño 10.
}media_X <- sapply(X,mean)
hist(media_X)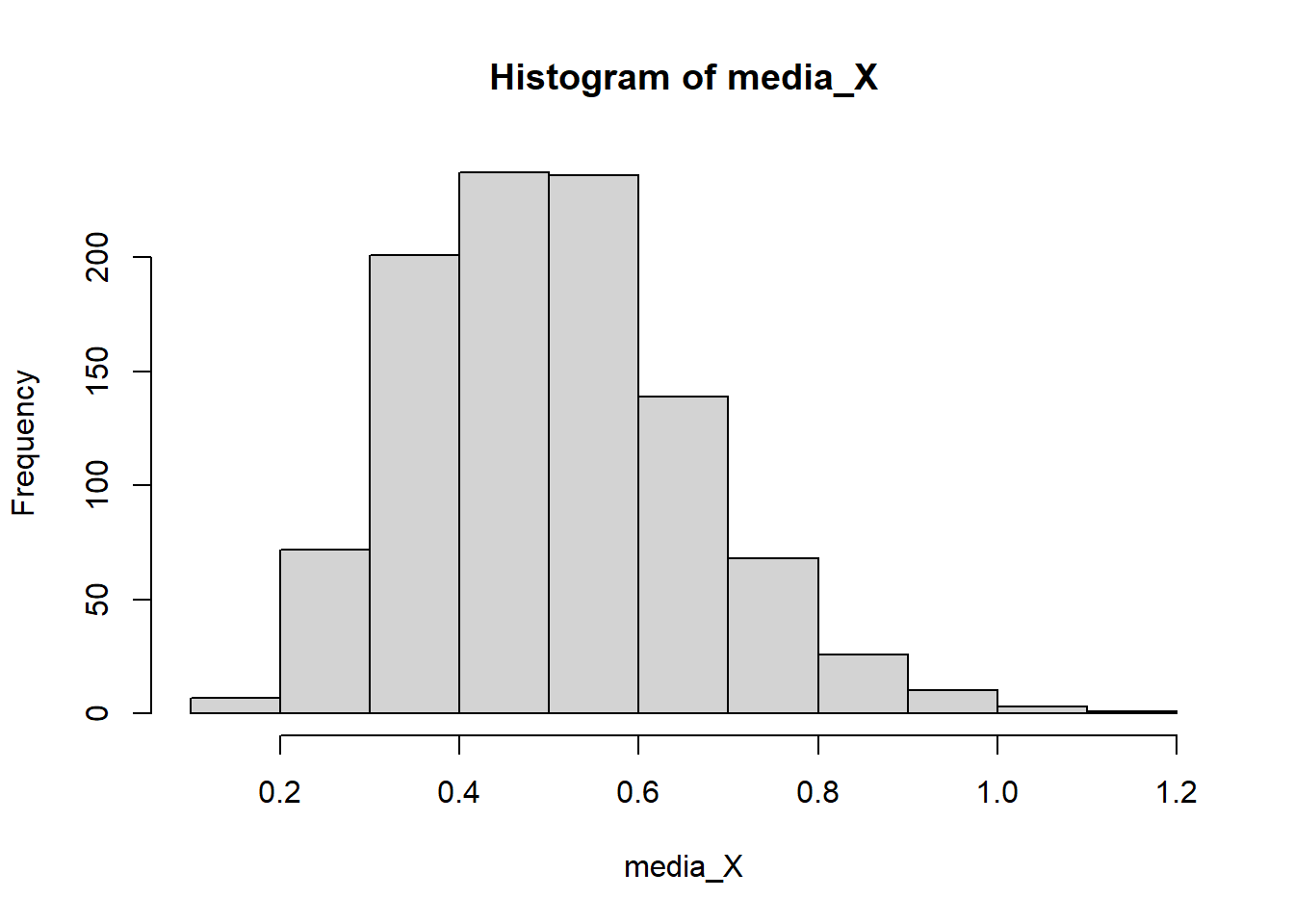
mean(media_X)[1] 0.5016877var(media_X)[1] 0.02423551Observe que teóricamente \(E(\bar{X})=0.5\) y \(Var(\bar{X})=0.5^2/n=0.5^2/10=0.025\). Además, el histograma muestra que con la distribución muestral de \(\bar{X}\) es asimétrica, al igual que el caso anterior con \(n=45\). Es decir, que no se parece a una distribución normal.
K <- 1000
n <- 1000
X <- list()
for(i in 1:K){
X[[i]] <- rexp(n,2) #X es una lista de las K muestras de tamaño 100.
}media_X <- sapply(X,mean)
hist(media_X)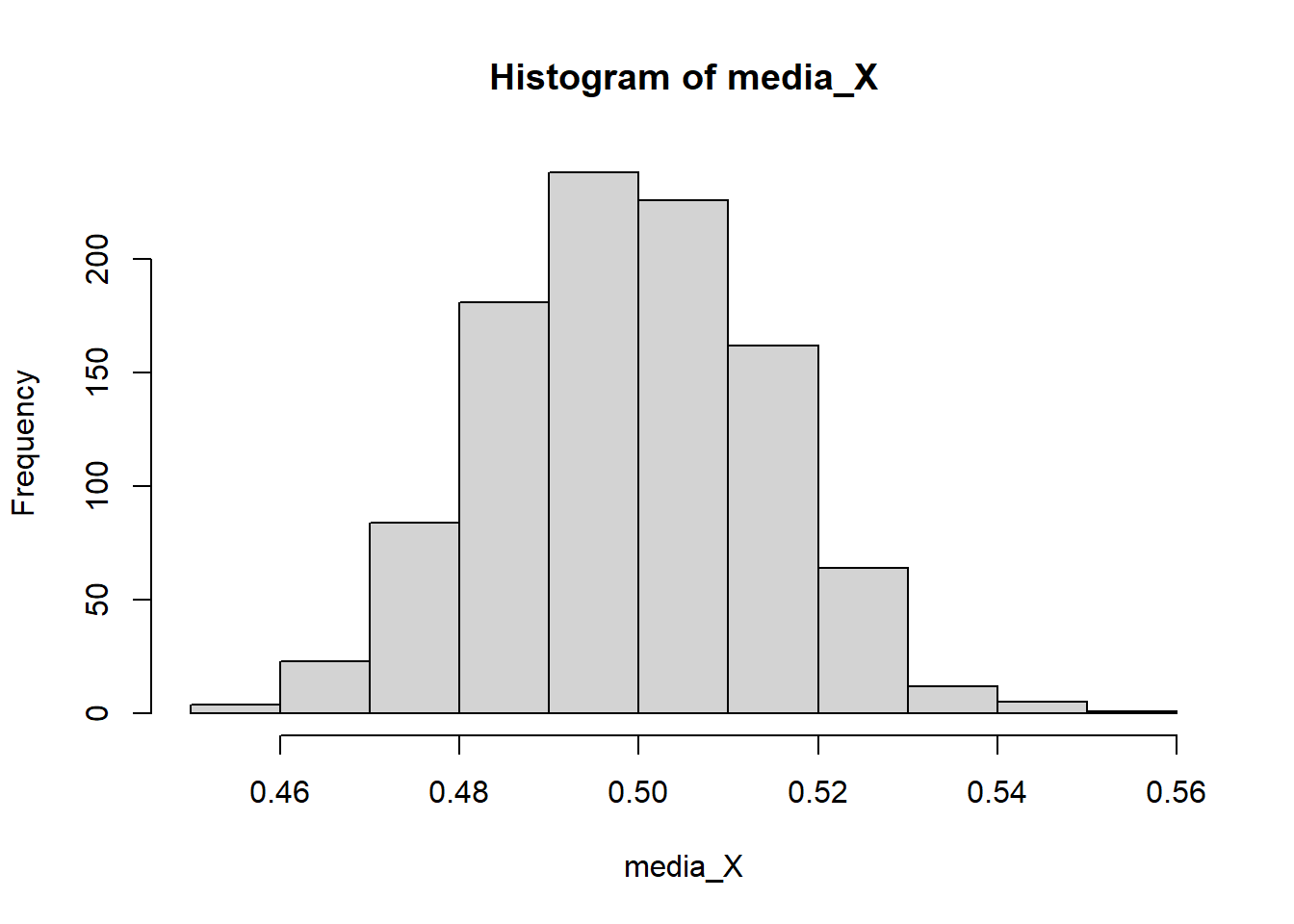
mean(media_X)[1] 0.4989865var(media_X)[1] 0.0002412724Observe que teóricamente \(E(\bar{X})=0.5\) y \(Var(\bar{X})=0.5^2/n=0.5^2/1000=0.00025\). Además, el histograma muestra que la distribución muestral de \(\bar{X}\) es más simétrica que los dos casos anteriores. Es decir, que se aproxima más a una distribución normal.
El TLC nos garantiza que \[ Z=\frac{\bar{X}-\mu}{\sigma/\sqrt{n}} \overset{d}{\rightarrow} N(0,1) \] Es decir, \(Z\) se aproxima cada vez a la normal estándar cuando \(n\rightarrow \infty\). Por ejemplo, con solo \(n=1000\), tenemos
Z=(media_X-0.5)/(sqrt(0.5^2/n))
hist(Z,prob=TRUE,ylim=c(0,0.5))
Z2 <- seq(min(Z), max(Z), length = 40)
lines(Z2, dnorm(Z2, mean = 0, sd = 1), col = 2, lwd = 2)
abline()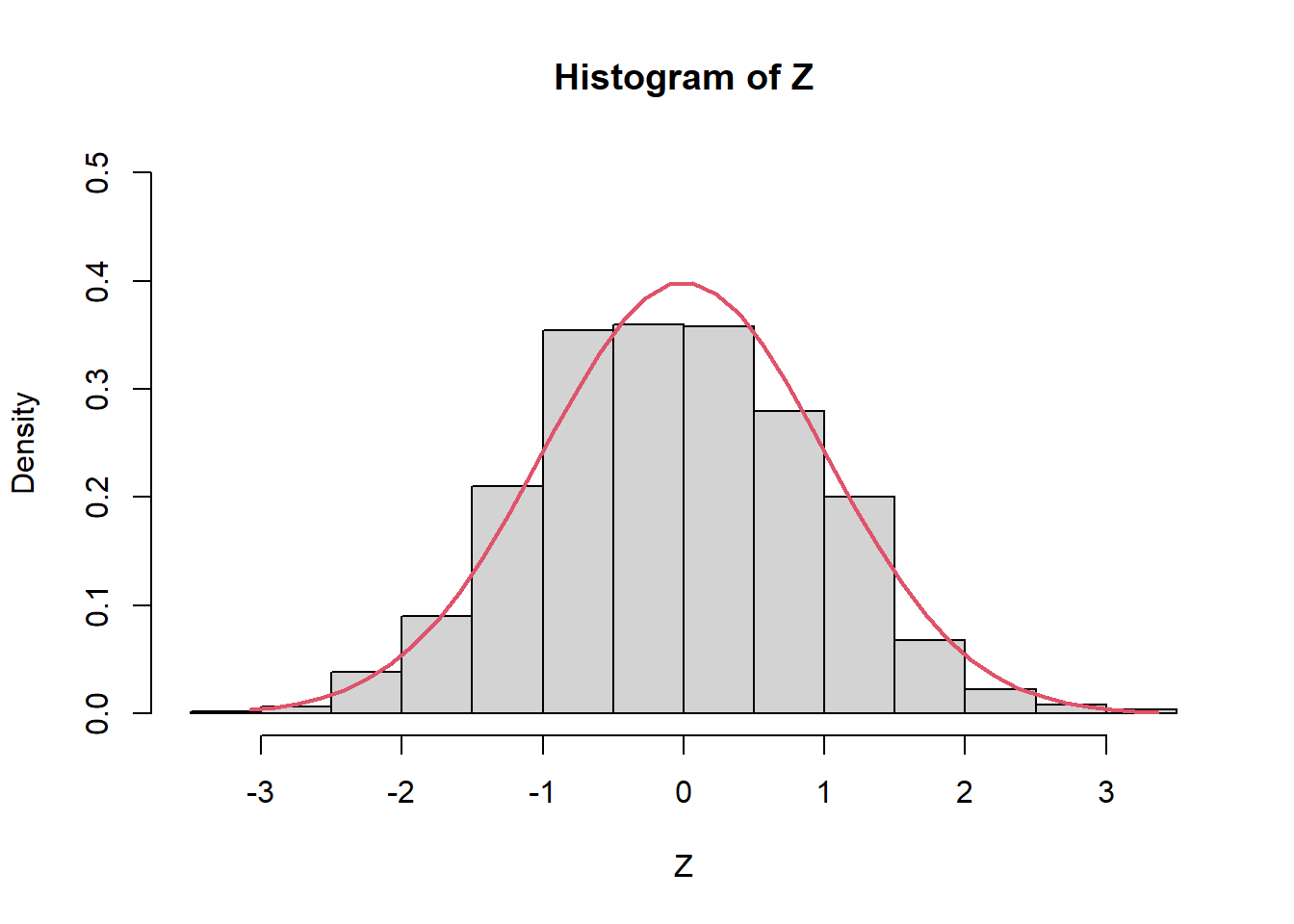
mean(Z)[1] -0.06410029var(Z)[1] 0.9650898Ejercicios: copiar estos códigos y hagan ustedes el ejercicio aumentando el valor de \(n\) gradualmente.
Suponga que se tiene una muestra aleatoria \(X_1,...,X_n\) tal que \(X_i \sim Bern(p=0.3), i =1,...,n\).
Una muestra aleatoria simulada con \(n=10\) se observa como sigue:
set.seed(123456789)
n <- 10
x <- rbinom(n=n,size=1,prob=0.3)
hist(x)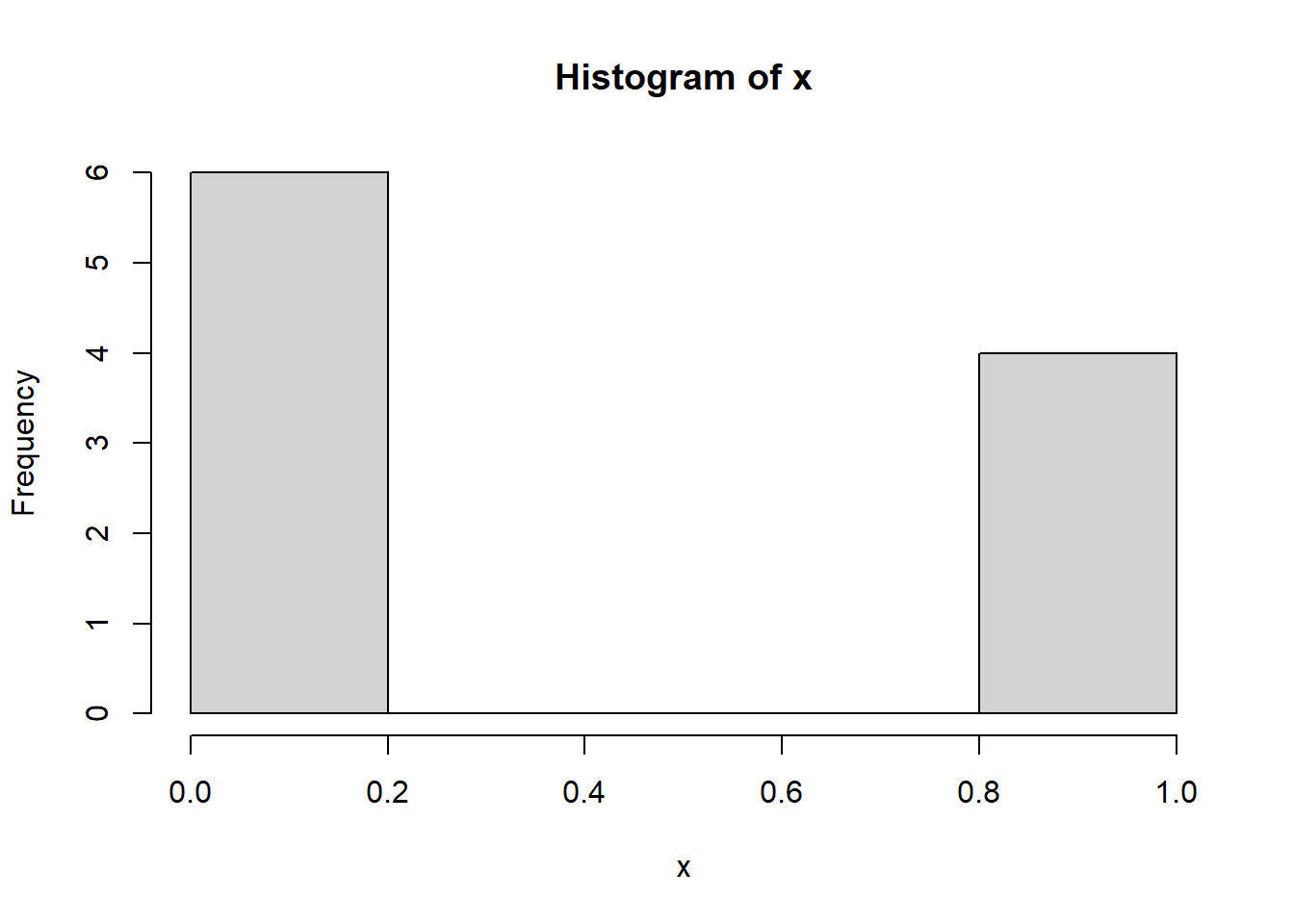
x [1] 0 0 0 1 1 1 0 1 0 0mean(x)[1] 0.4var(x)[1] 0.2666667Observe que teóricamente \(E(X)=0.3\) y \(Var(X)=pq=0.3 \cdot 0.7=0.21\).
Ahora, tomo \(K=1000\) muestras aleatorias y las guardo en una lista X.
K <- 1000
n <- 10
X <- list()
for(i in 1:K){
X[[i]] <- rbinom(n=n,size=1,prob=0.3) #¿Cuáles son las otras formas de hacer?
}Calculo la media para \(k=1,...,K\) y obtengo la media y variancia (empírica) de la media muestral de las \(K=1000\) medias muestrales.
media_X <- sapply(X,mean)
hist(media_X)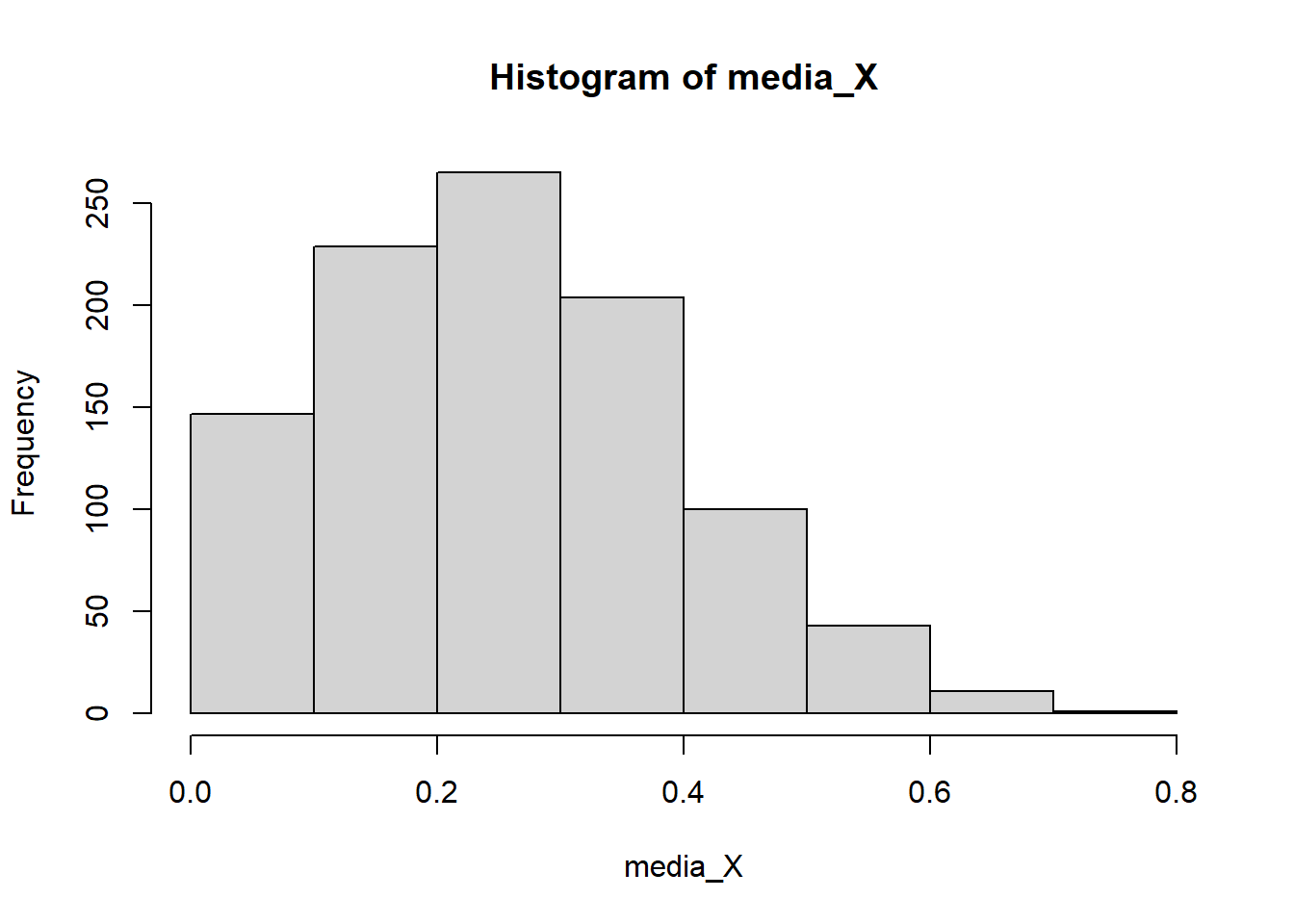
mean(media_X)[1] 0.3024var(media_X)[1] 0.0218561Observe que teóricamente \(E(\bar{X})=0.3\) y \(Var(\bar{X})=\frac{pq}{n}=\frac{0.3 \cdot 0.7}{10}=0.021\). ¿Qué distribución muestral tiene \(\bar{X}\)?
El TLC nos garantiza que \[ Z=\frac{\bar{X}-\mu}{\sigma/\sqrt{n}} \overset{d}{\rightarrow} N(0,1) \] Es decir, \(Z\) se aproxima cada vez a la normal estándar cuando \(n\rightarrow \infty\). Por ejemplo, con solo \(n=10\), tenemos
Z=(media_X-0.3)/(sqrt(0.3*0.7/n))
hist(Z,prob=TRUE,ylim=c(0,0.7))
Z2 <- seq(min(Z), max(Z), length = 40)
lines(Z2, dnorm(Z2, mean = 0, sd = 1), col = 2, lwd = 2)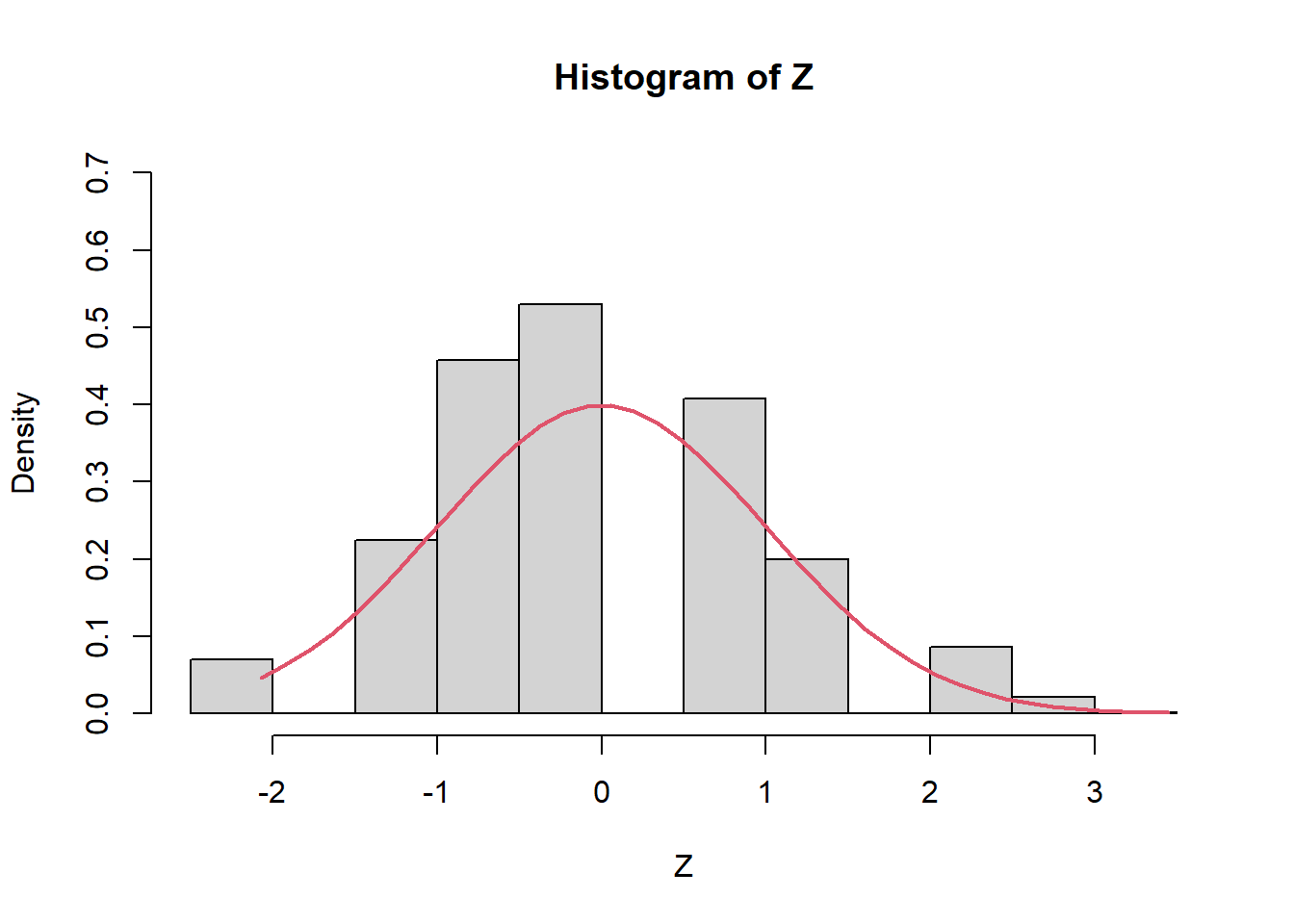
mean(Z)[1] 0.01656157var(Z)[1] 1.040766Pero con \(n=100\), tenemos
K <- 1000
n <- 100
X <- list()
for(i in 1:K){
X[[i]] <- rbinom(n=n,size=1,prob=0.3)
}
media_X <- sapply(X,mean)
Z=(media_X-0.3)/(sqrt(0.3*0.7/n))
hist(Z,prob=TRUE,ylim=c(0,0.6))
Z2 <- seq(min(Z), max(Z), length = 40)
lines(Z2, dnorm(Z2, mean = 0, sd = 1), col = 2, lwd = 2)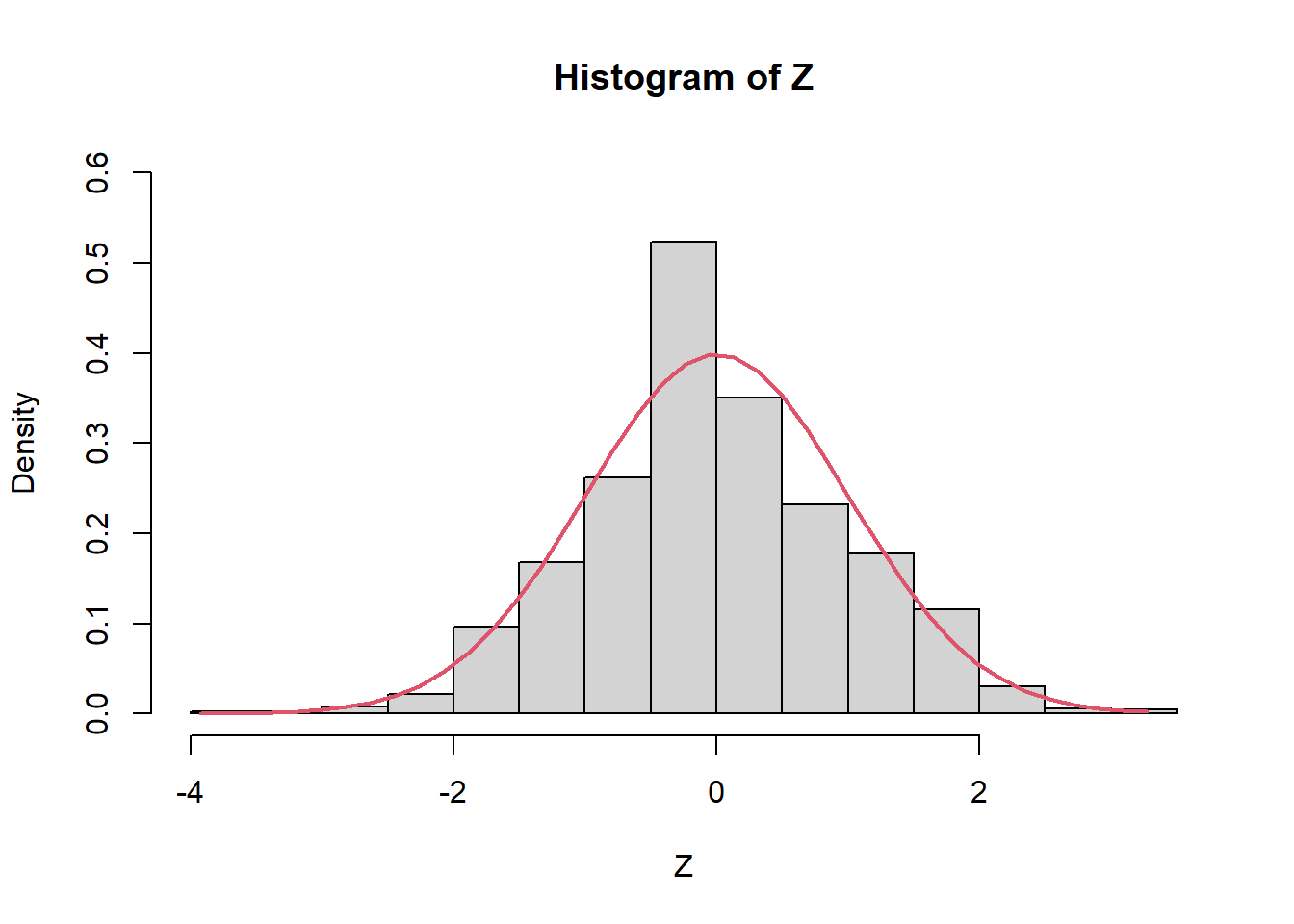
mean(Z)[1] 0.01745743var(Z)[1] 0.9635159Volvemos al caso anterior con \(n=10\). Calculo la varviancia muestral para \(k=1,...,K\) y obtengo la media y variancia (empírica) de la media muestral de las \(K=1000\) medias muestrales.
K <- 1000
n <- 10
X <- list()
for(i in 1:K){
X[[i]] <- rbinom(n=n,size=1,prob=0.3) #¿Cuáles son las otras formas de hacer?
}
var_X <- sapply(X,var)
hist(var_X)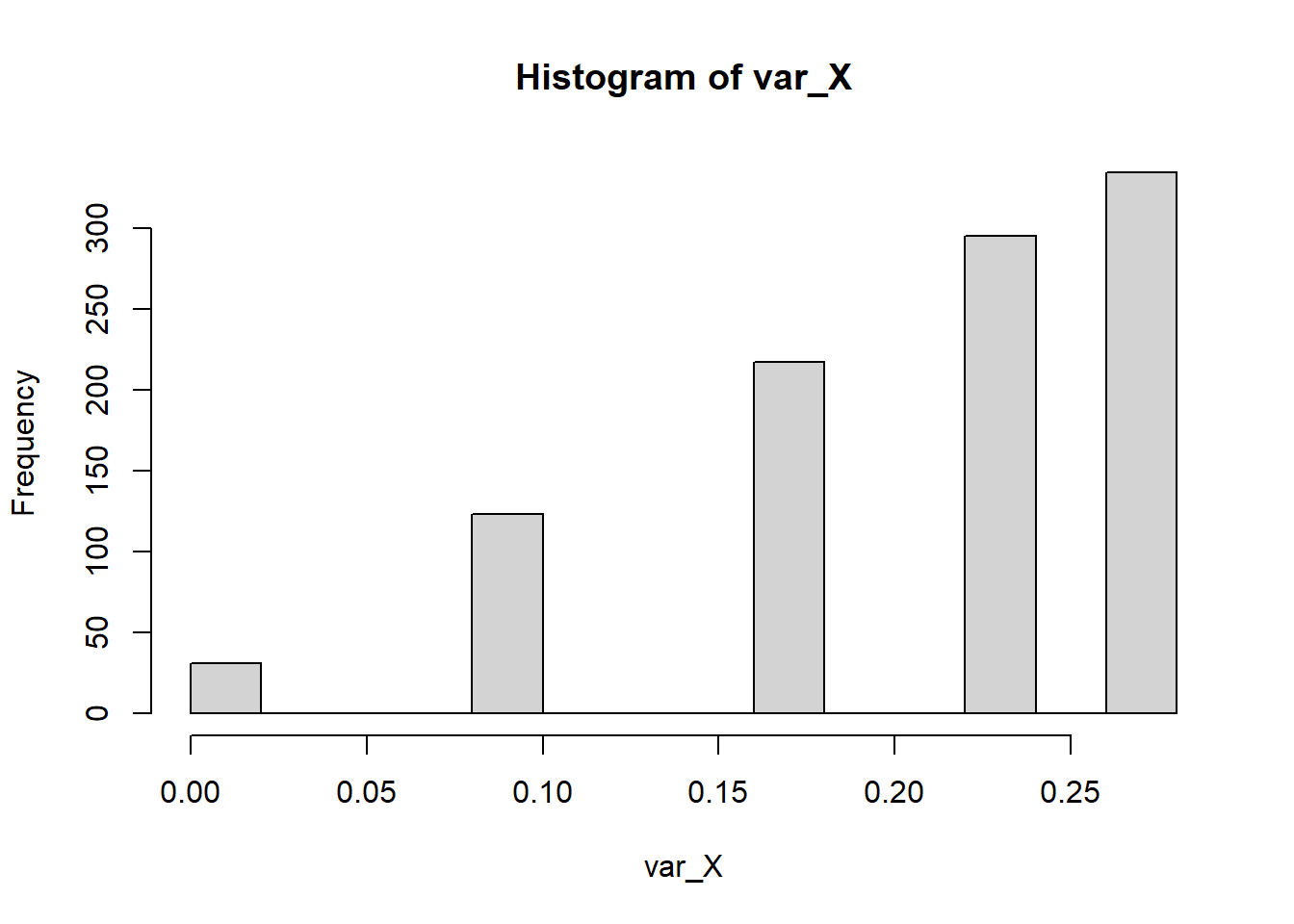
mean(var_X)[1] 0.2099var(var_X)[1] 0.004457929Observe que teóricamente \(E(S^2)=\sigma^2=pq=0.3\cdot 0.7=0.21\). Sin embargo, no tenemos información del valor teórico de \(Var(S^2)\).
Suponga que \(X_1,...,X_n \sim N(10,2)\).
K <- 1000
n <- 100
X <- list()
for(i in 1:K){
X[[i]] <- rnorm(n=n,mean=10,sd=sqrt(2))
}media_X <- sapply(X,mean)
hist(media_X)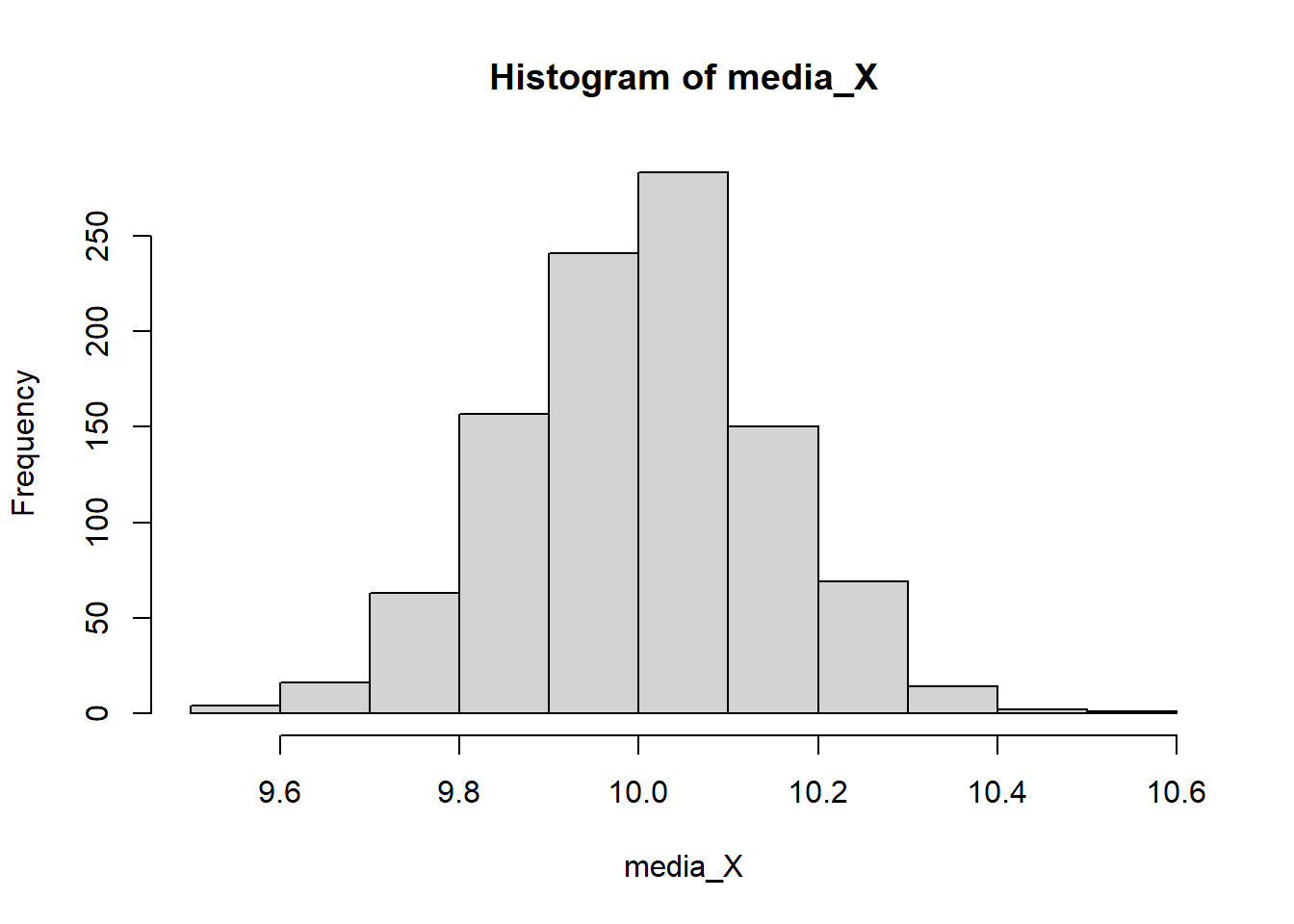
mean(media_X)[1] 10.00102var(media_X)[1] 0.02053045Observe que teóricamente \(E(\bar{X})=10\) y \(Var(\bar{X})=\frac{\sigma^2}{n}=\frac{2}{100}=0.02\). ¿Qué distribución muestral tiene \(\bar{X}\)?
Por otro lado,el TLC nos garantiza que \[ Z=\frac{\bar{X}-\mu}{\sigma/\sqrt{n}} \overset{d}{\rightarrow} N(0,1) \] Es decir, \(Z\) se aproxima cada vez a la normal estándar cuando \(n\rightarrow \infty\). Por ejemplo, con solo \(n=10\), tenemos
Z=(media_X-10)/(sqrt(2/n))
hist(Z,prob=TRUE,ylim=c(0,0.5))
Z2 <- seq(min(Z), max(Z), length = 40)
lines(Z2, dnorm(Z2, mean = 0, sd = 1), col = 2, lwd = 2)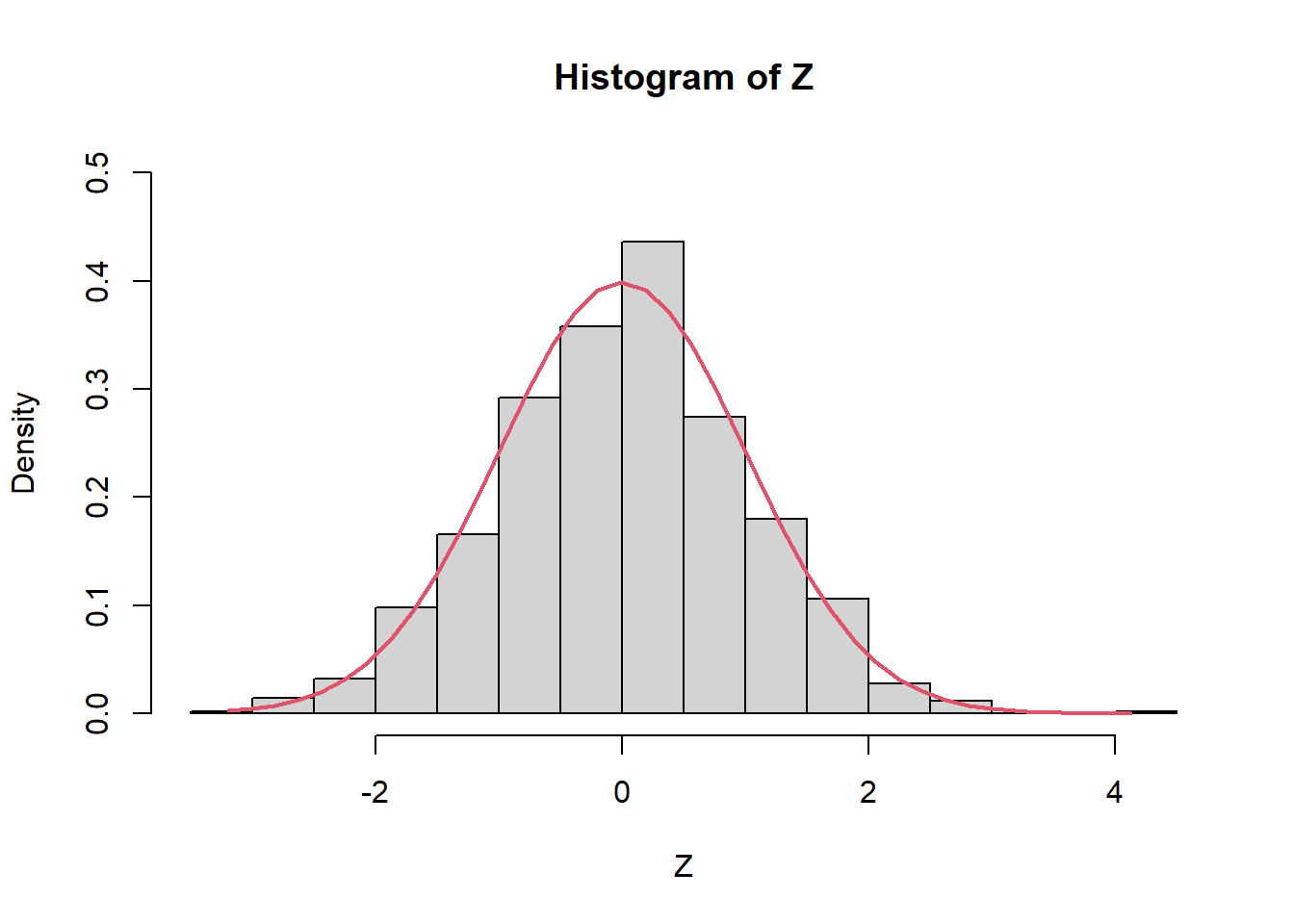
mean(Z)[1] 0.007184607var(Z)[1] 1.026523var_X <- sapply(X,var)
hist(var_X)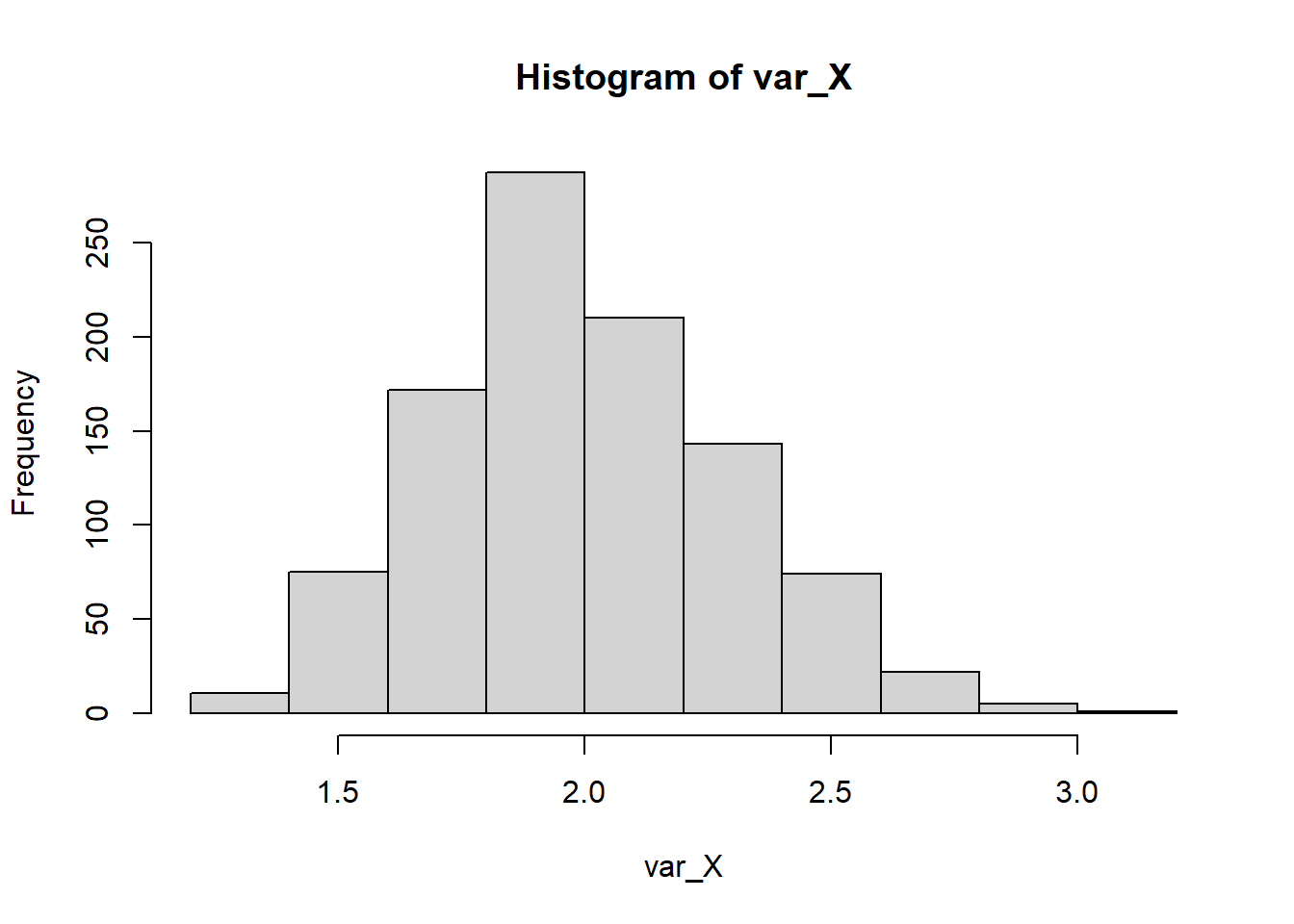
mean(var_X)[1] 1.996659var(var_X)[1] 0.08836783En el caso de que la población es normal, recuerde que \[E(S^2)=\sigma^2=2,~~ \text{y}~~ Var(S^2)=\frac{2\sigma^4}{n-1}=\frac{2\cdot 2^2}{100-1}=0.08081\]