Tema 3: Técnicas de suavizamiento exponencial

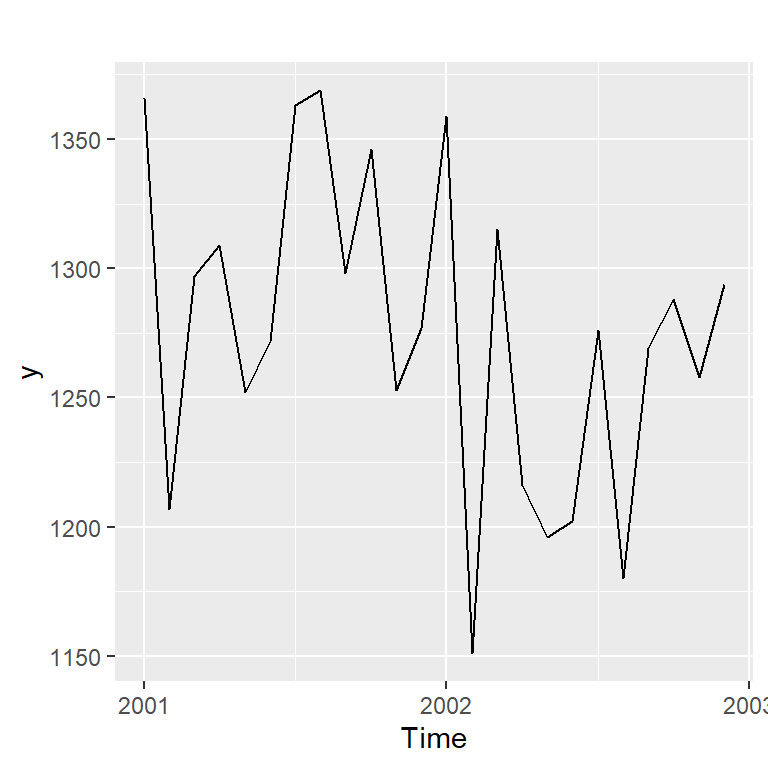
- Ejemplo 3.1 de Hernández (2011): Serie mensual de defunciones de Costa Rica de los años 2001 y 2002.
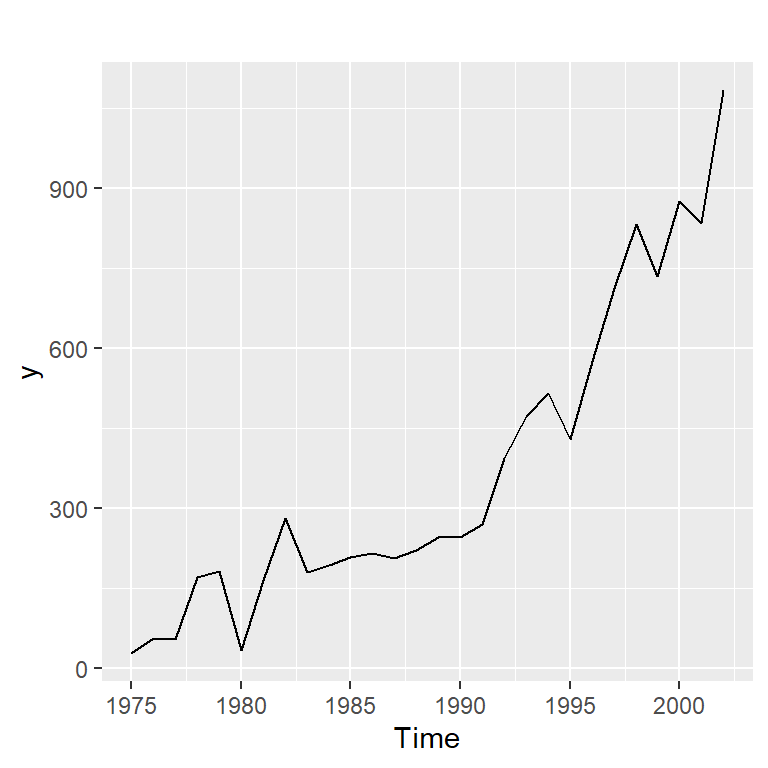
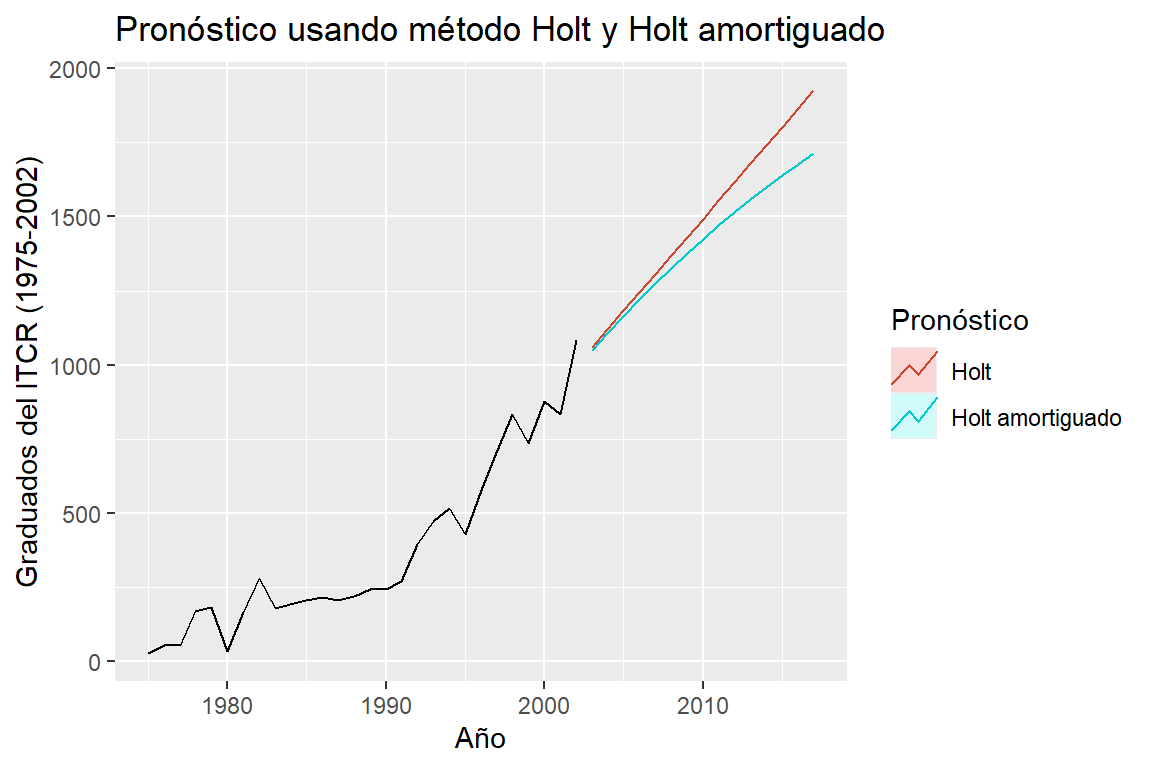
- Ejemplo 3.2 de Hernández (2011): Serie de graduados del ITCR de 1975-2002.
Los índices estacionales se inicializan como cociente de los primeros \(s\) valores al promedio de los primeros \(s\) datos. \[S_i=\frac{Z_i}{l_s}, \text{ para } i=1,...,s\]
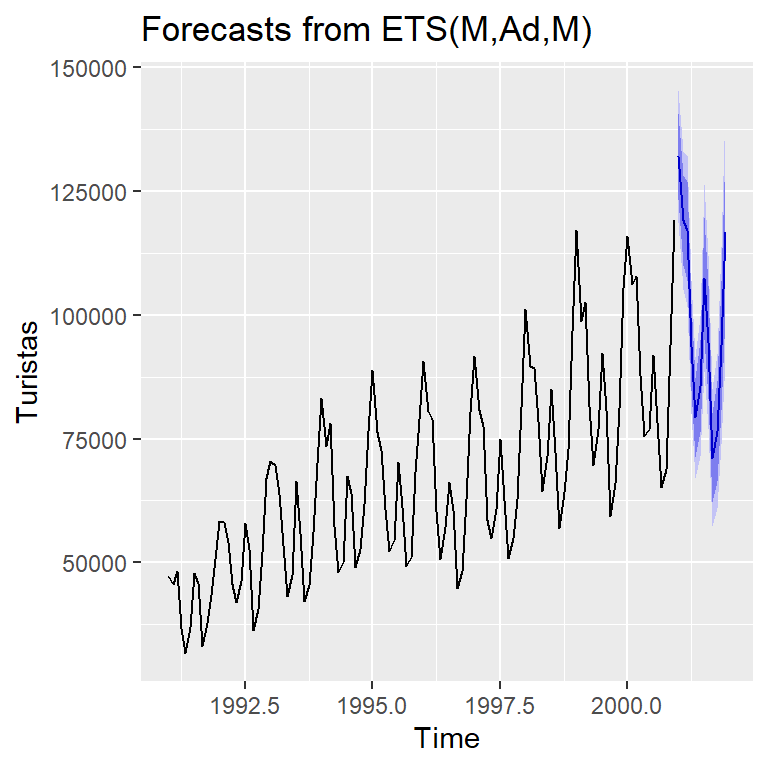
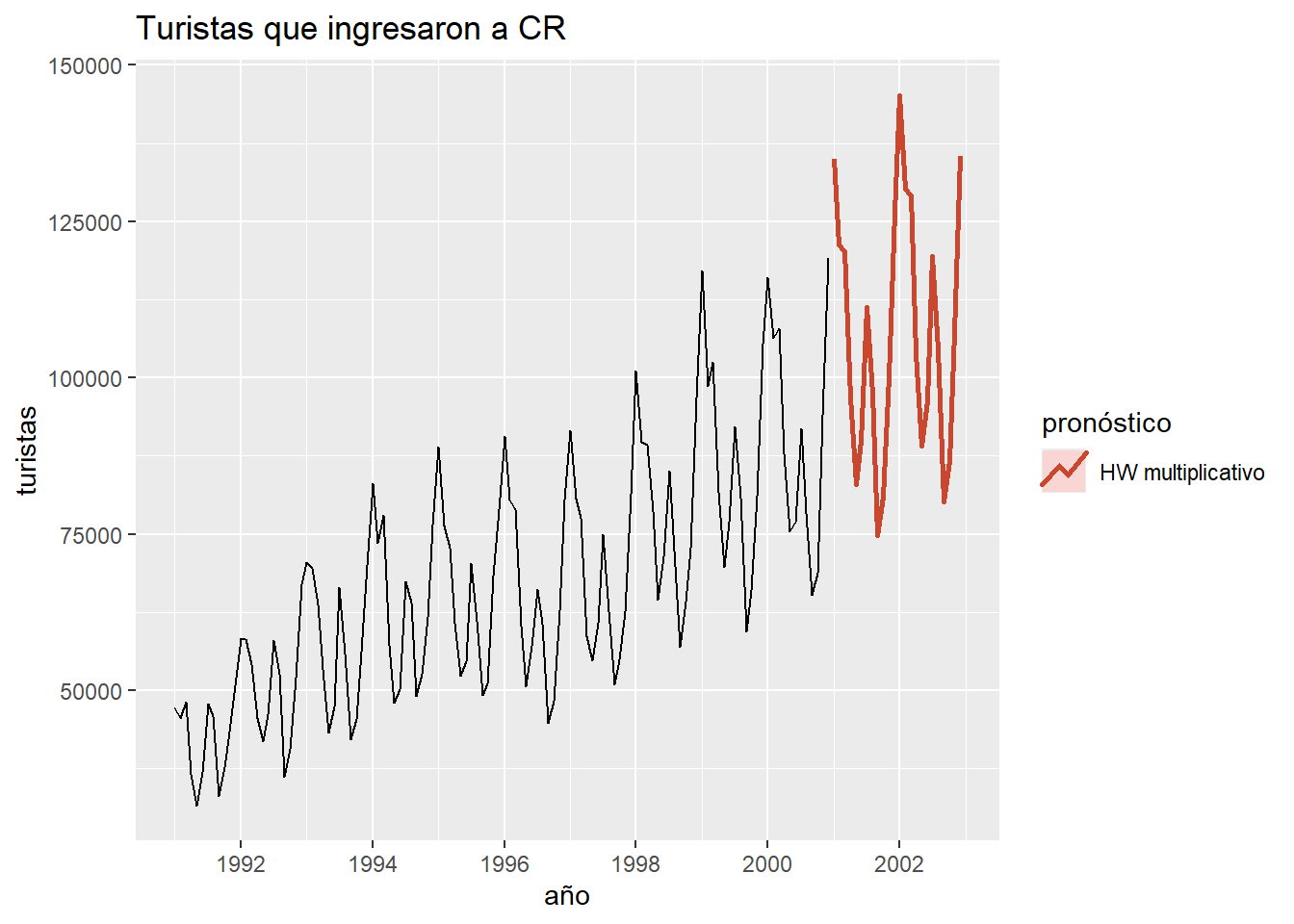
Ejemplo 3.3 de Hernández (2011): Serie mensual de turistas de 1991-2000.
Comparación entre el aditivo y multiplicativo de H-W
ht1 <- hw(y,seasonal="multiplicative")
ht2 <- hw(y,seasonal="additive")
autoplot(y) +
autolayer(ht1, series="HW multiplicativo", PI=FALSE, size = 1) +
autolayer(ht2, series="HW aditivo", PI=FALSE, size = 1) +
xlab("año") +
ylab("turistas") +
ggtitle("Turistas que ingresaron a CR") +
guides(colour=guide_legend(title="pronóstico"))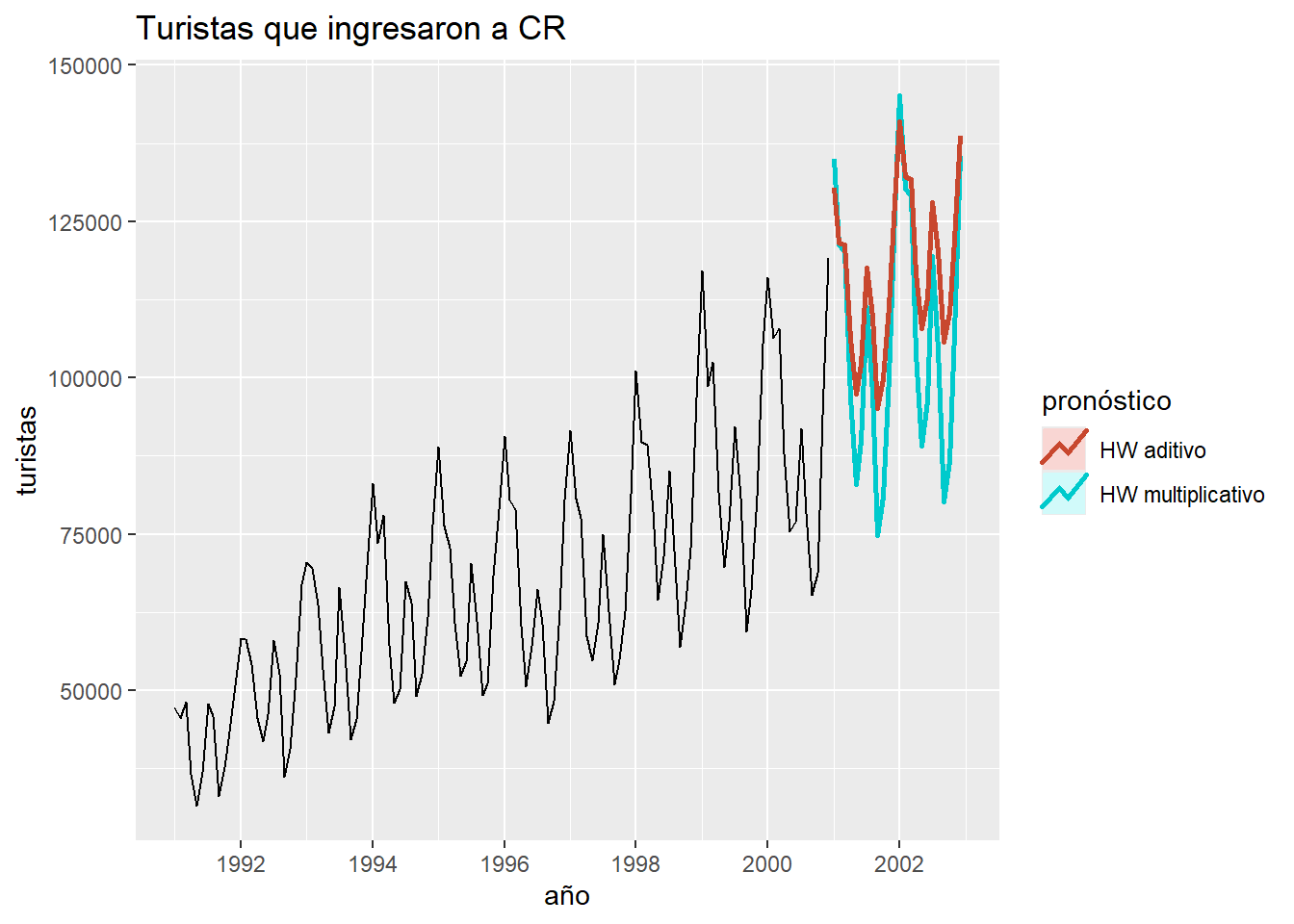
Comparación de las medidas de precisión.
ME RMSE MAE MPE MAPE MASE
Training set -114.3084 3239.923 2580.033 -0.3986991 3.995136 0.4245259
ACF1
Training set 0.008128625 ME RMSE MAE MPE MAPE MASE
Training set -394.643 4297.824 3312.546 -0.7003905 5.216058 0.5450557
ACF1
Training set -0.003603756 ME RMSE MAE MPE MAPE MASE
Training set 309.2038 3213.097 2587.598 0.2712205 3.958626 0.4257708
ACF1
Training set -0.01930739- Por ejemplo, si necesito estimar
turistas<-read.csv("turistas.csv",sep=";")
y<-ts(turistas$turistas,start=c(1991,1),frequency=12)
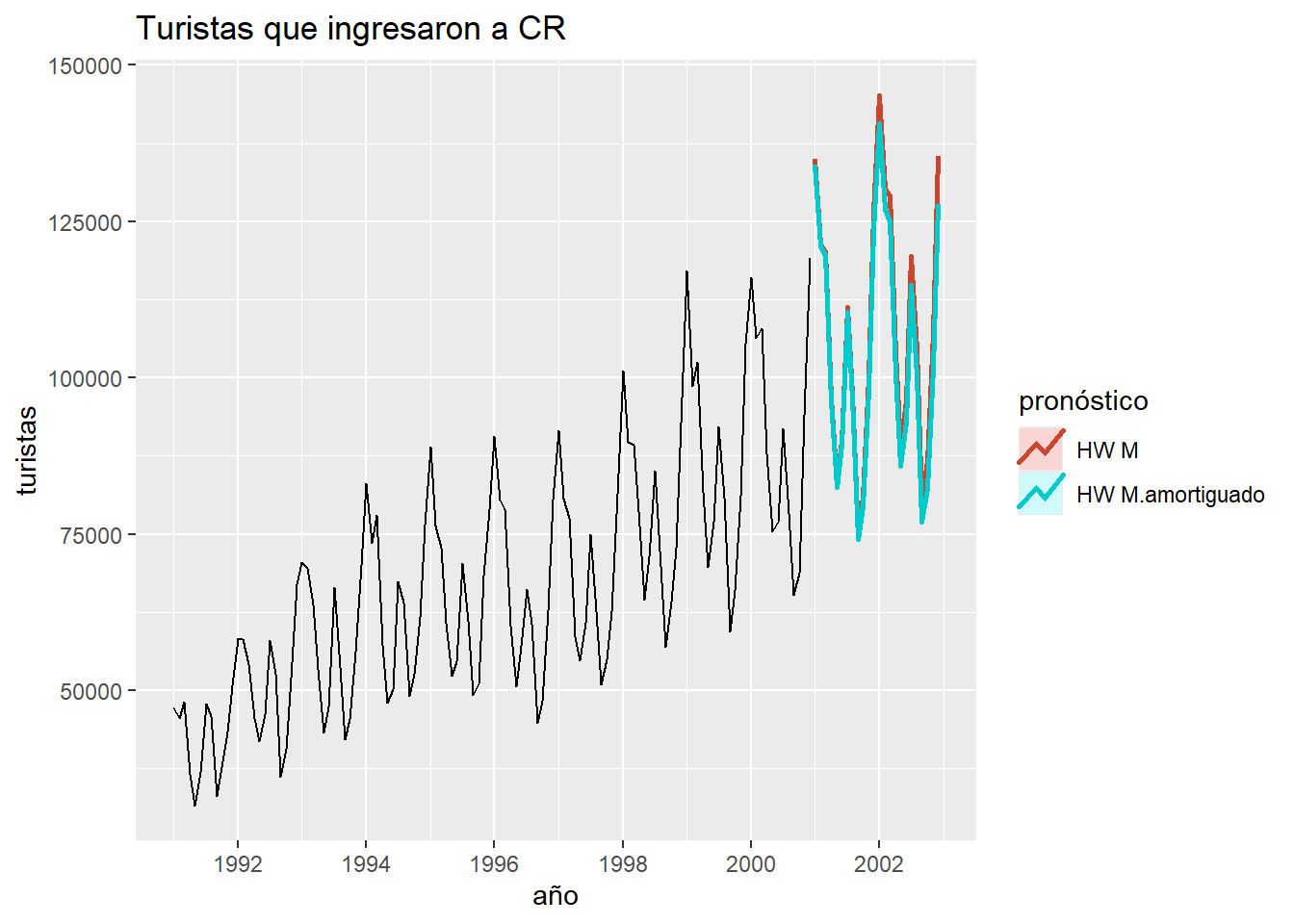
hw_ad<-ets(y,model="AAA",damped = FALSE)
hw_ad_a<-ets(y,model="AAA",damped = TRUE)
hw_mul<-ets(y,model="MAM",damped = FALSE)
hw_mul_a<-ets(y,model="MAM",damped = TRUE)
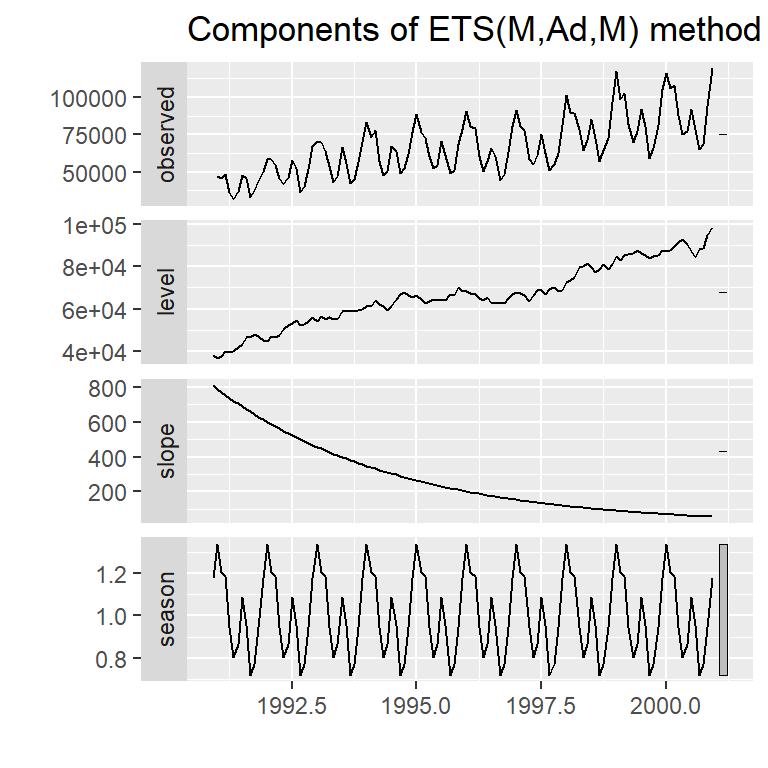
hw_auto<-ets(y,model="ZZZ") #selecciona el mejor modelo usando AIC.
plot(hw_auto)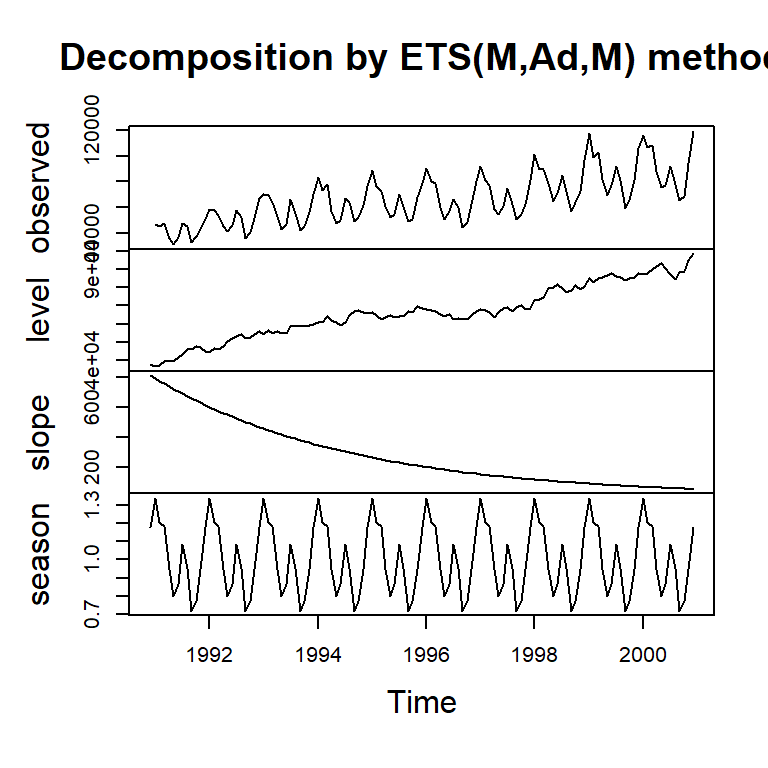
¿Qué es el término del error y cómo se define los criterios de información como el AIC?
Representación como modelos de Espacio de Estados
- El modelo de Espacio de Estados en general está caracterizado por dos procesos en el tiempo:
Un proceso latente (o oculto) \(x_t\): Se supone que es un proceso de Markov, i.e. \[P(x_t|x_{t-1},x_{t-2},...)=P(x_t|x_{t-1})\]
Un proceso de observaciones \(y_t\): Se supone que son independientes dado los estados \(x_t\).
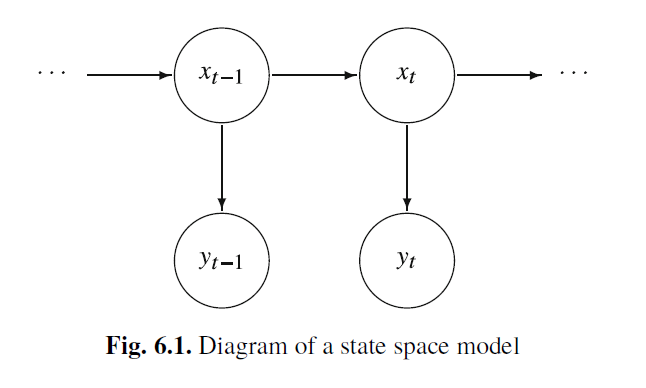
Fuente: Shumway & Stoffer (2017)