Tema 4: Regresión con series de tiempo

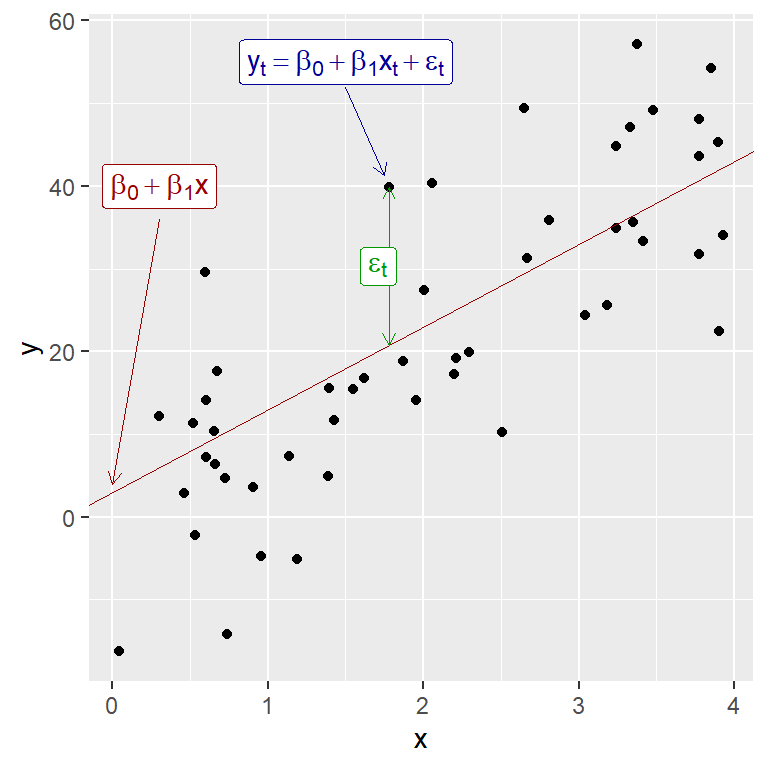
Ejemplo simulado de un modelo de regresión lineal simple (Fig 5.1 de Hyndman)
Ejemplo
- La serie de cambios porcentuales trimestrales (tasas de crecimiento) del gasto de consumo personal real (\(Y_t\), variable dependiente), y el cambio porcentual de los ingresos disponibles(\(X_t\), covariable), para EE.UU. desde 1970 a 2016.
Consumption Income Production Savings Unemployment
1970 Q1 0.6159862 0.9722610 -2.4527003 4.8103115 0.9
1970 Q2 0.4603757 1.1690847 -0.5515251 7.2879923 0.5
1970 Q3 0.8767914 1.5532705 -0.3587079 7.2890131 0.5
1970 Q4 -0.2742451 -0.2552724 -2.1854549 0.9852296 0.7
1971 Q1 1.8973708 1.9871536 1.9097341 3.6577706 -0.1
1971 Q2 0.9119929 1.4473342 0.9015358 6.0513418 -0.1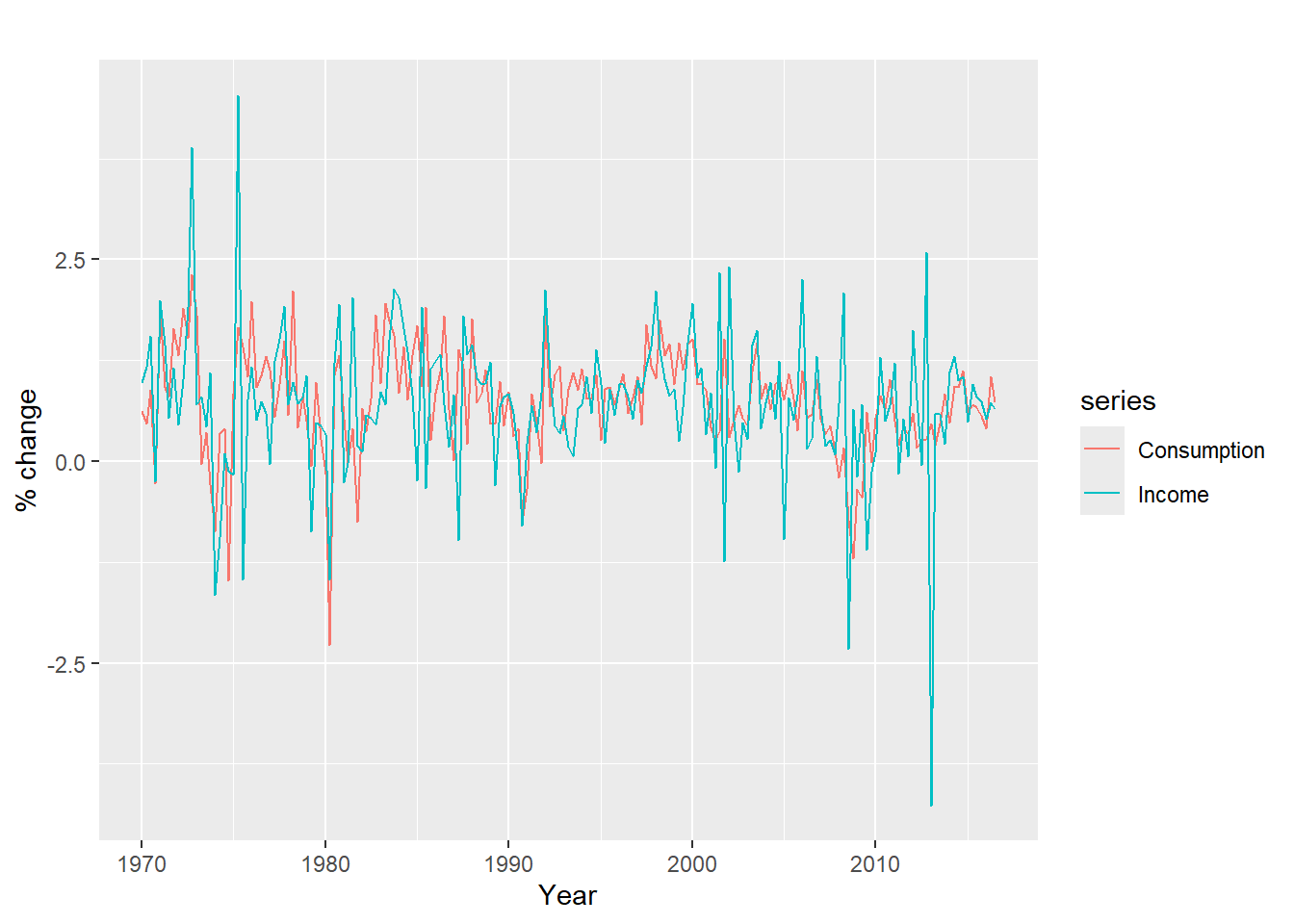
uschange %>%
as.data.frame() %>%
ggplot(aes(x=Income, y=Consumption)) +
ylab("Consumption (quarterly % change)") +
xlab("Income (quarterly % change)") +
geom_point() +
geom_smooth(method="lm", se=FALSE)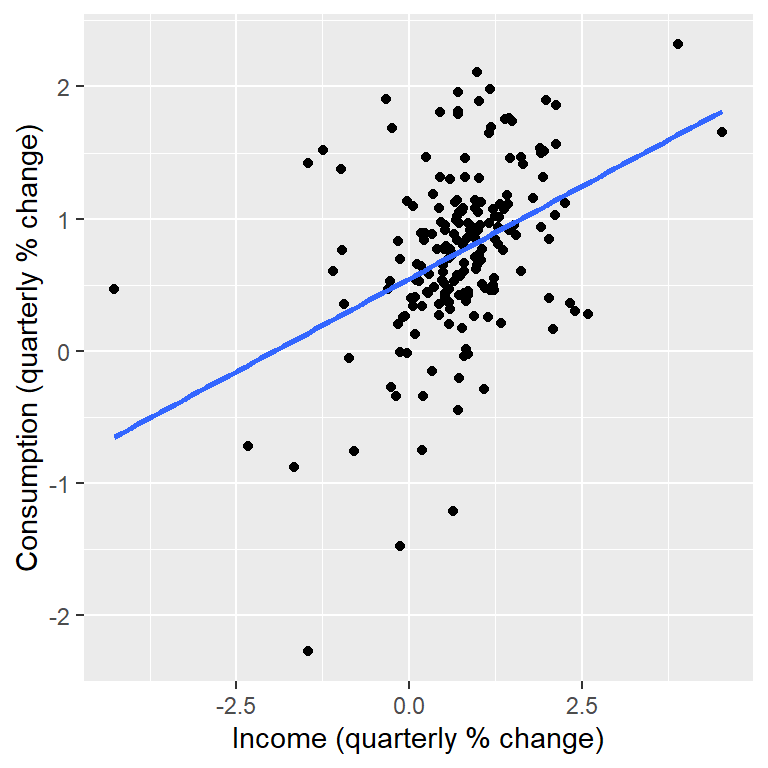
- Más adelante vemos que
tslmes programado para series temporales, pero el cálculo es lo mismo.
Call:
lm(formula = Consumption ~ Income, data = uschange)
Coefficients:
(Intercept) Income
0.5451 0.2806
Call:
tslm(formula = Consumption ~ Income, data = uschange)
Coefficients:
(Intercept) Income
0.5451 0.2806 \[Y_t=0.55 + 0.28X_t + \epsilon_t\]
- El coeficiente de pendiente muestra que un aumento de una unidad en \(X\)(un aumento de 1 punto porcentual en el ingreso personal disponible) resulta en un promedio de 0.28 unidades de aumento en \(Y\).
Ejemplo
- El objetivo es generar pronósticos del consumo más precisos usando otros predictores, además del ingreso personal.
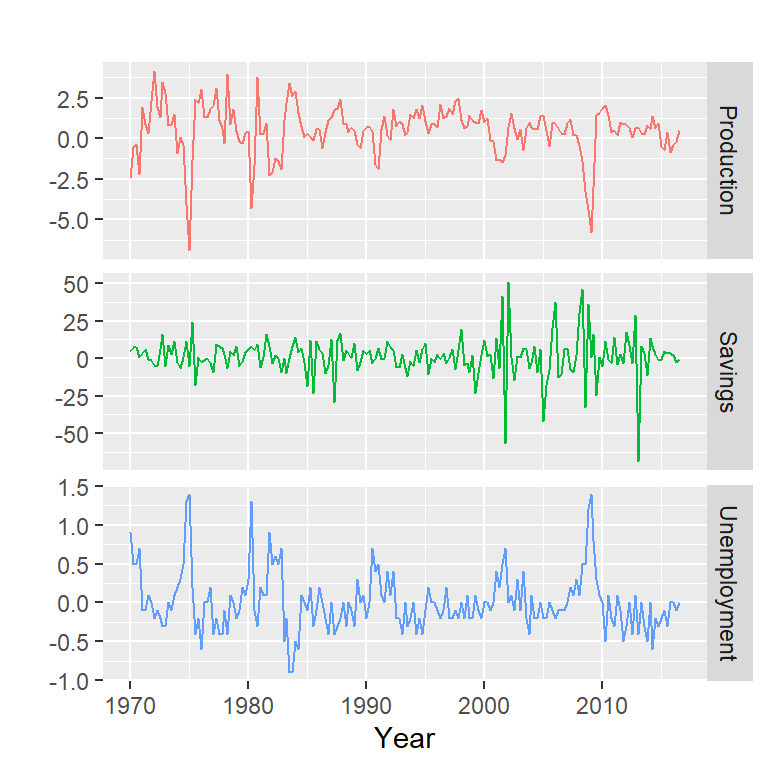
Variaciones porcentuales trimestrales en la producción industrial y ahorros personales y variaciones trimestrales en la tasa de desempleo de los EE. UU. Durante el período 1970T1-2016T3 (Hyndman)
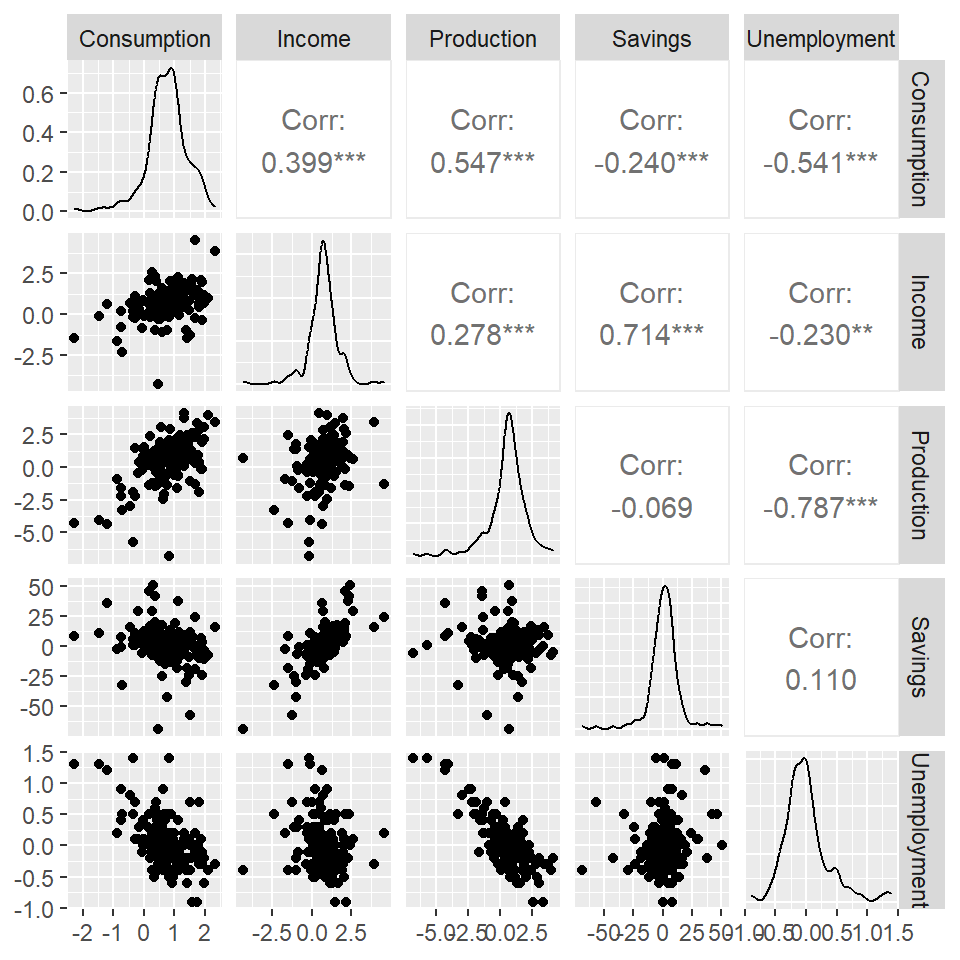
Matriz de diagrama de dispersión del gasto de consumo de EE. UU. y los cuatro predictores.
Breusch-Godfrey test for serial correlation of order up to 8
data: Residuals from Linear regression model
LM test = 14.874, df = 8, p-value = 0.06163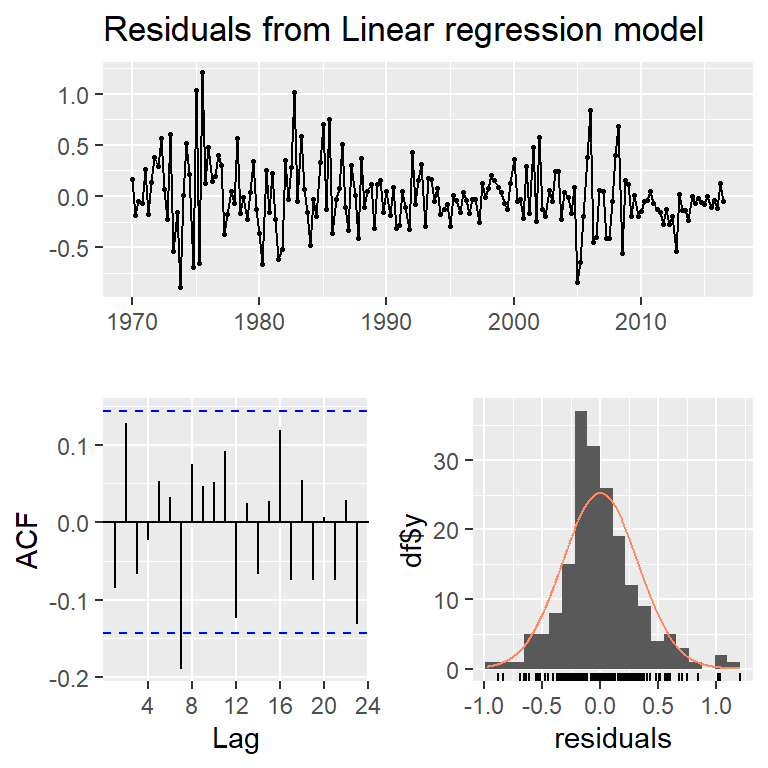
Regresión espuria
- Cuando las series no son estacionarias1, los resultados de regresión no son confiables y presenta lo que se llama correlación espuria.
Los datos de las series cronológicas de tendencias pueden parecer relacionados.
Por ejemplo, los pasajeros aéreos en Australia tienen una correlación positiva con la producción de arroz en Guinea.
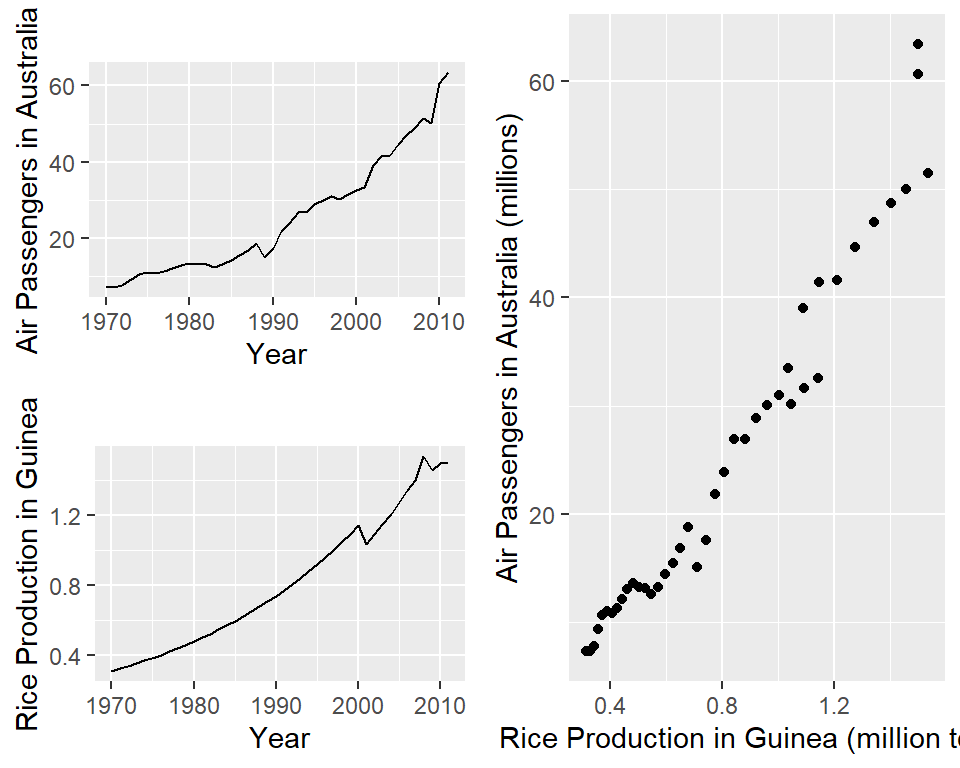
Call:
tslm(formula = aussies ~ guinearice)
Residuals:
Min 1Q Median 3Q Max
-5.9448 -1.8917 -0.3272 1.8620 10.4210
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -7.493 1.203 -6.229 2.25e-07 ***
guinearice 40.288 1.337 30.135 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.239 on 40 degrees of freedom
Multiple R-squared: 0.9578, Adjusted R-squared: 0.9568
F-statistic: 908.1 on 1 and 40 DF, p-value: < 2.2e-16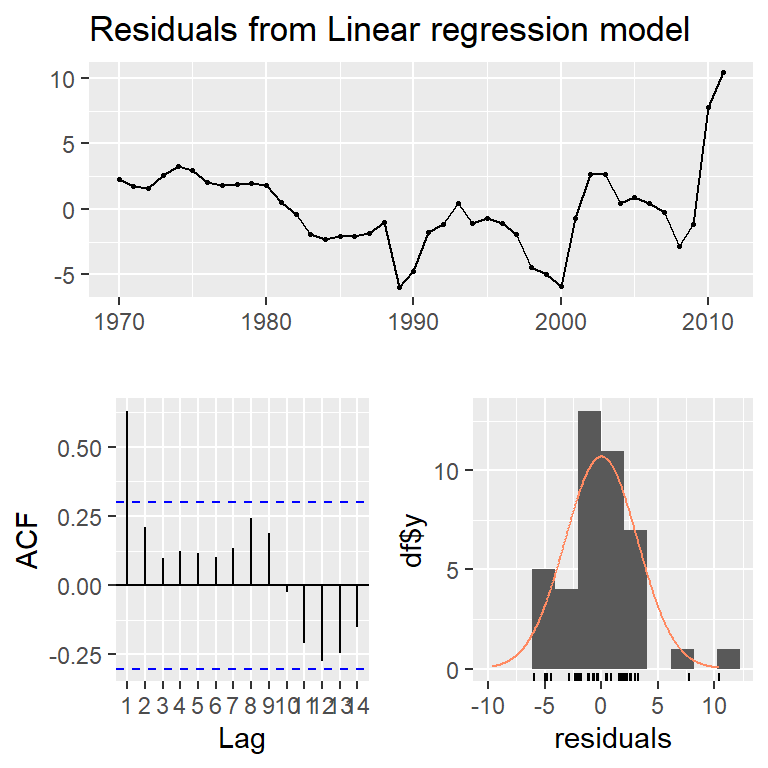
Vamos a ajustar un modelo de tendencia cuadrática a la serie de graduados de ITCR de 1975 a 2002: \[Y_t=\beta_0+\beta_1 t +\beta_2 t^2 + \epsilon_t, t=1,...,T\]
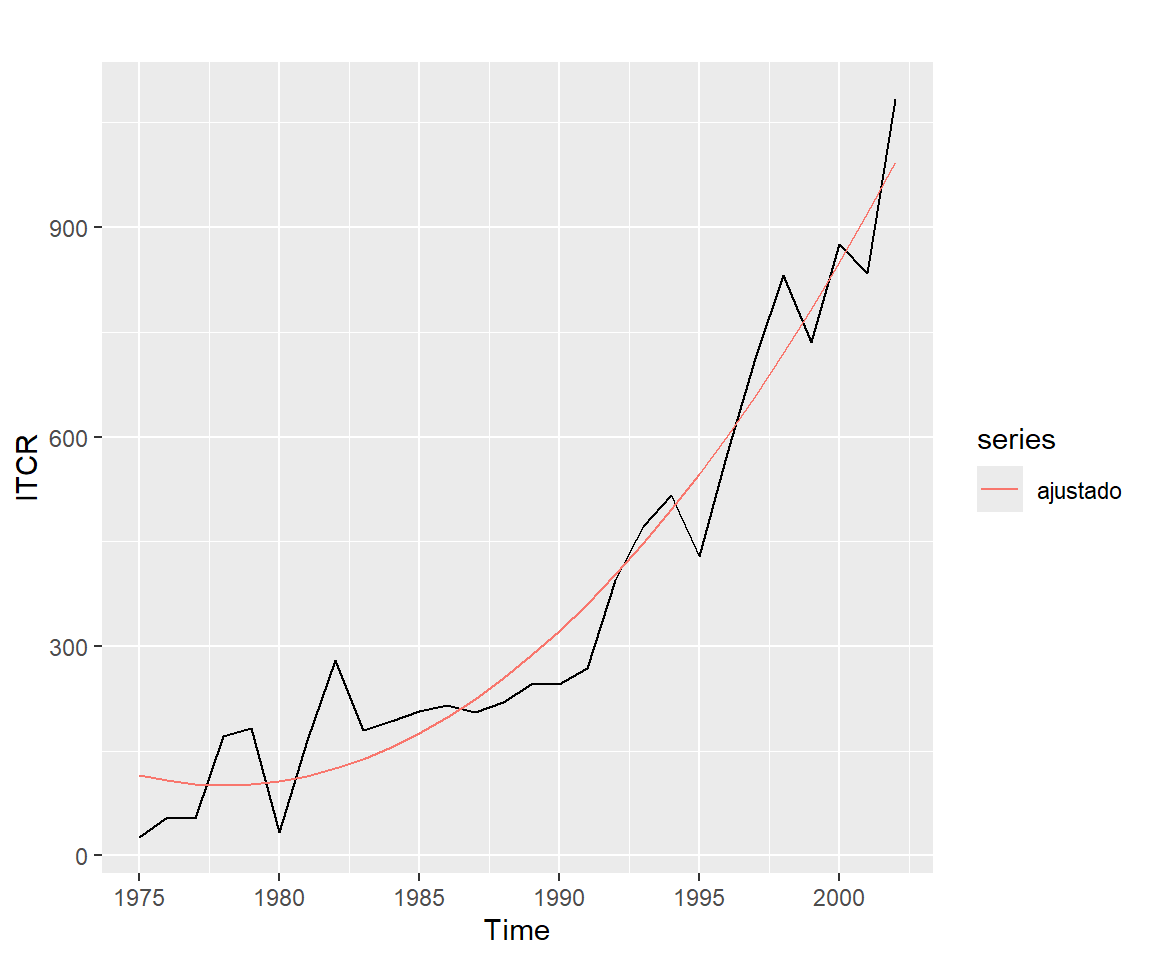
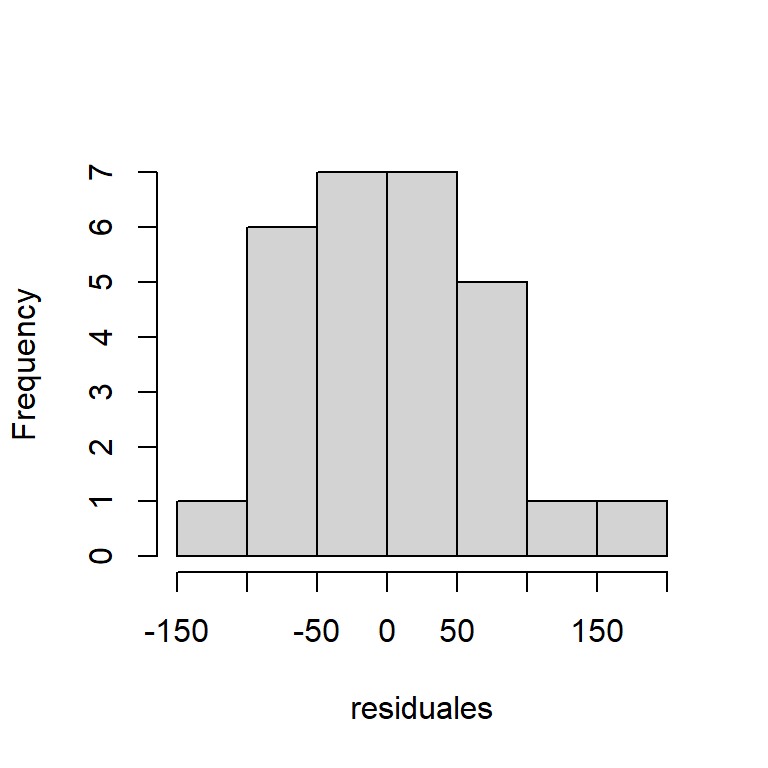
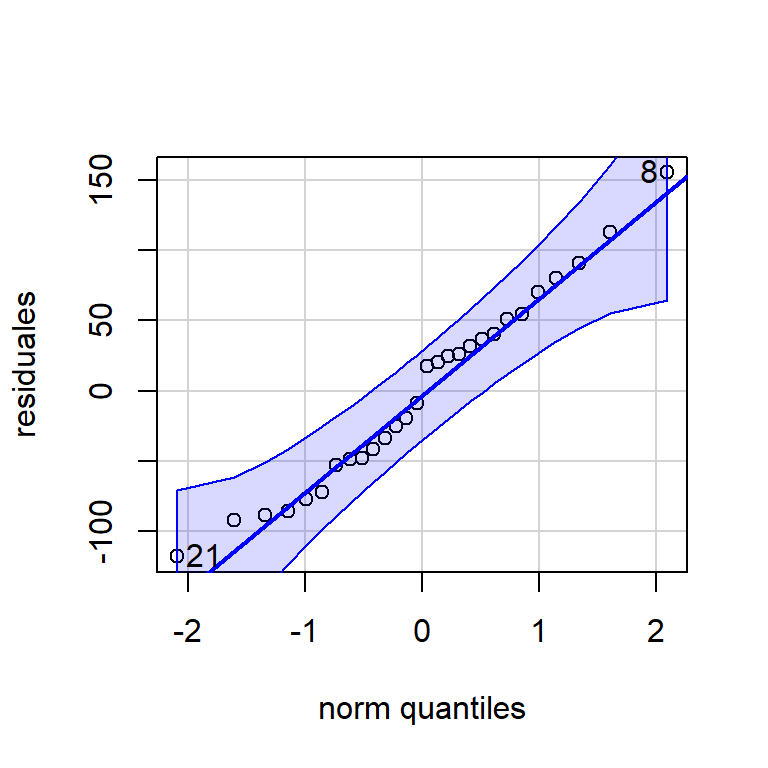
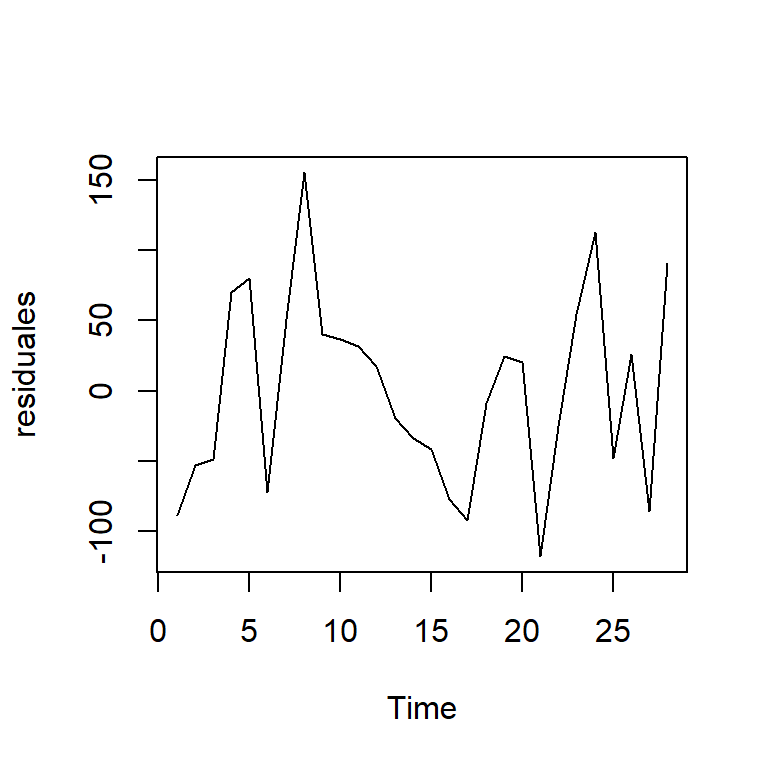
- Los residuales en el tiempo:
Breusch-Godfrey test for serial correlation of order up to 6
data: Residuals
LM test = 3.9215, df = 6, p-value = 0.6873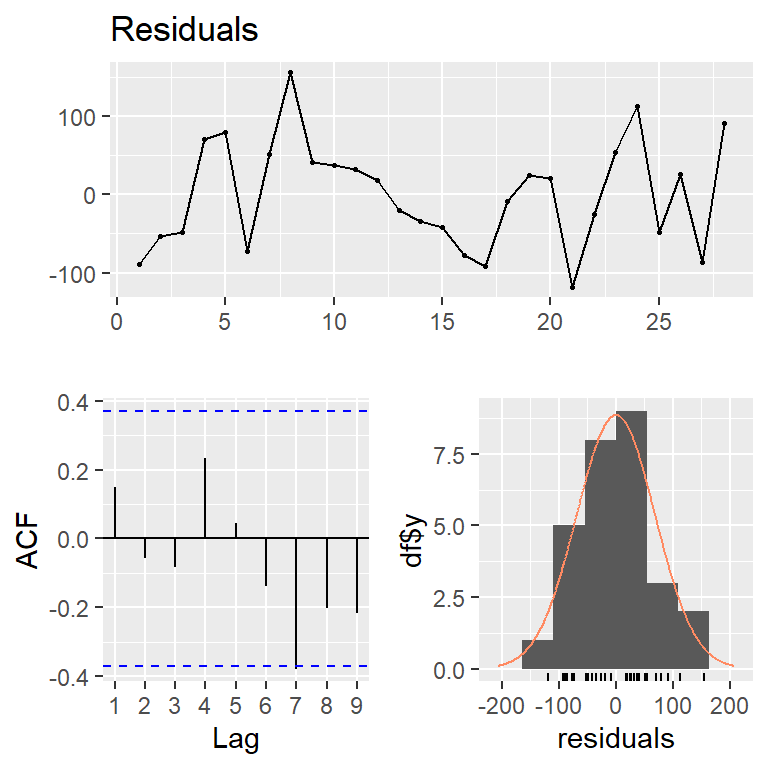
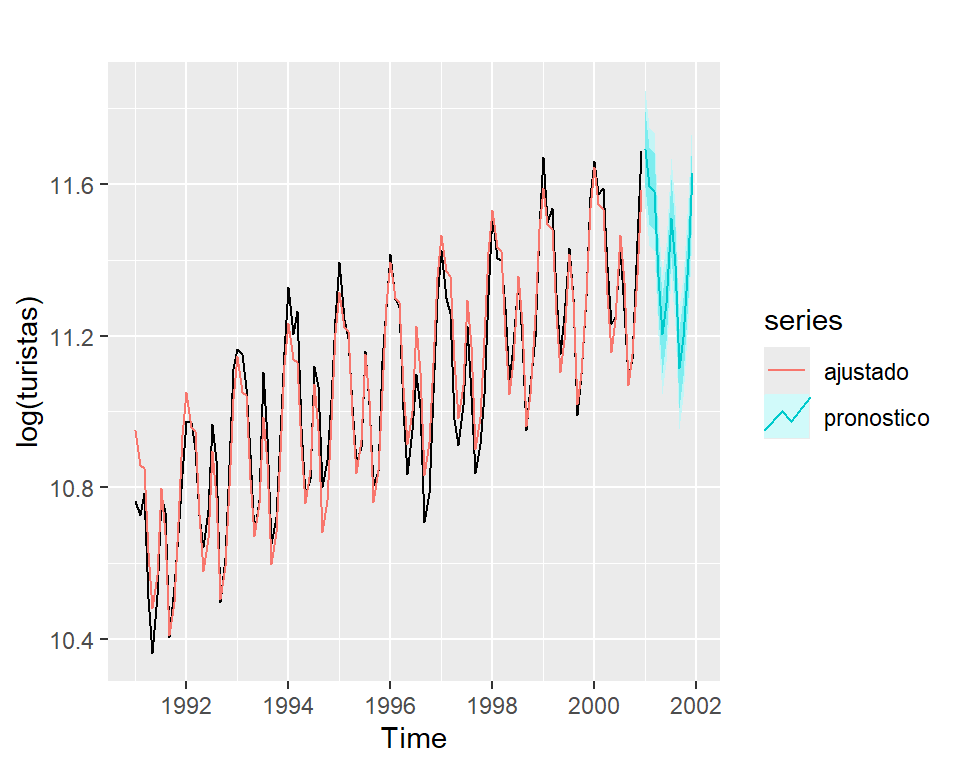
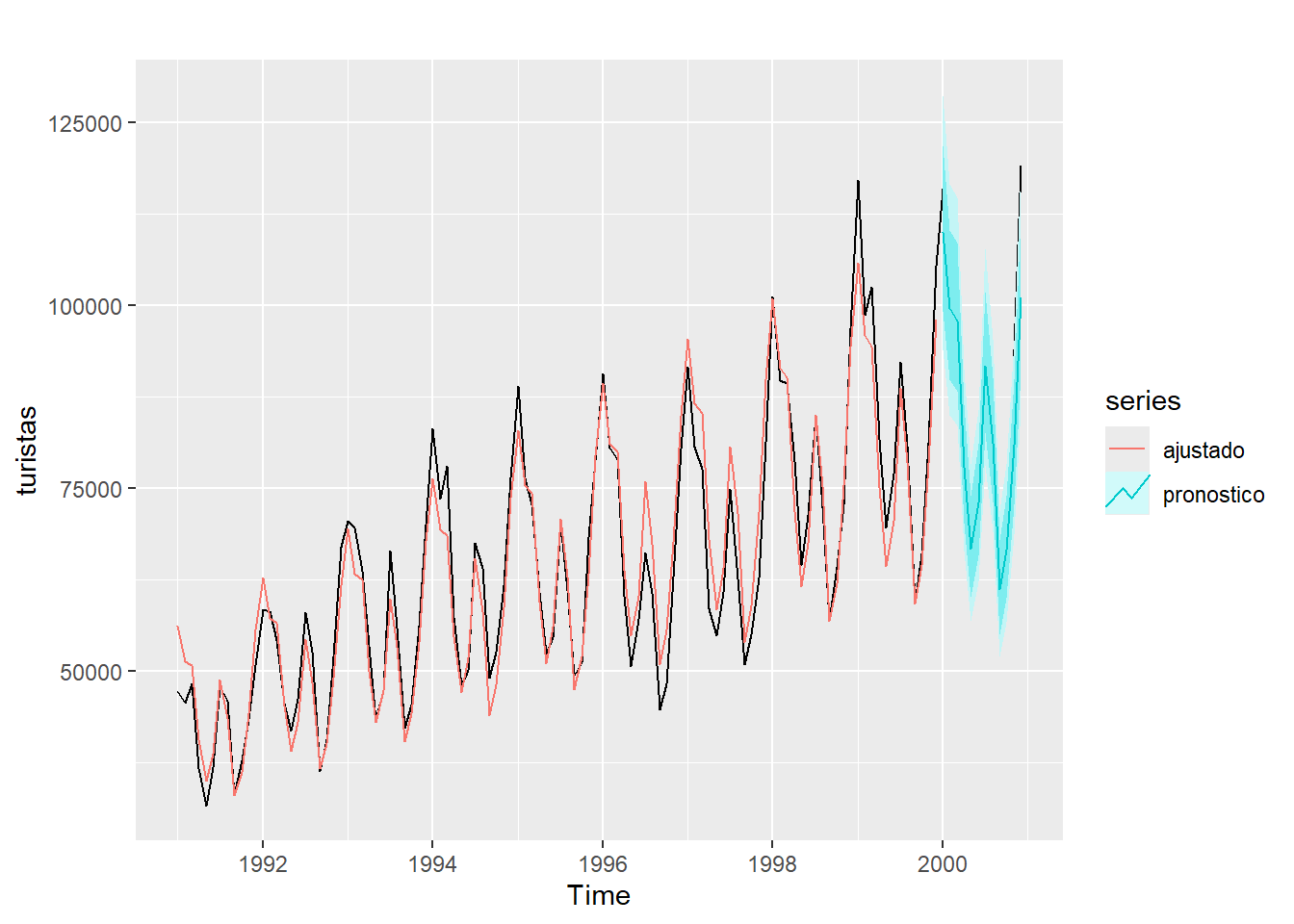
Ejemplo de turistas
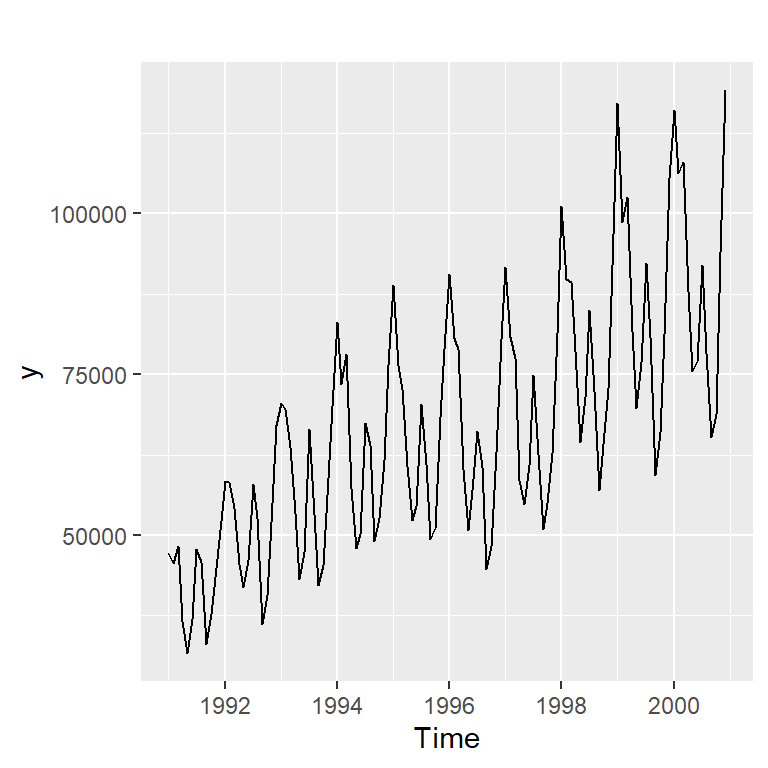
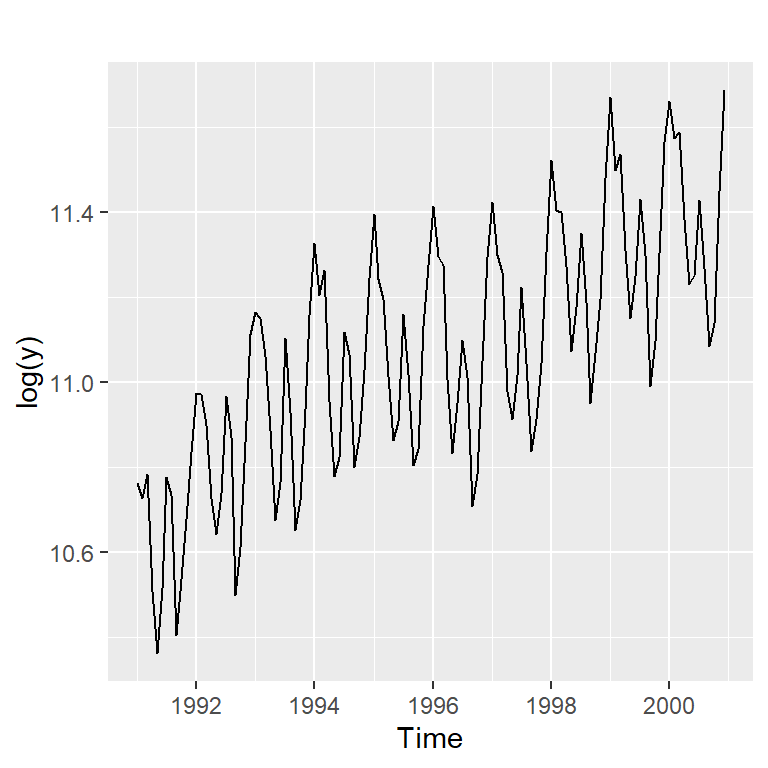
- Pronóstico de \(W_t = log (Y_t)\).
Ejemplo
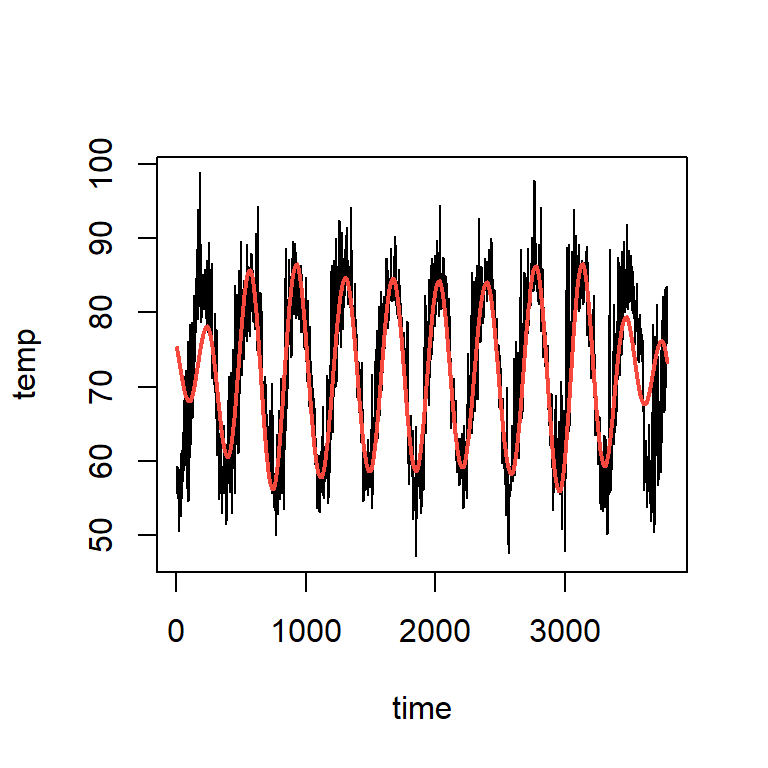
Temperatura diaria (F) en Cairo de 01-01-1995 hasta 21-05-2005
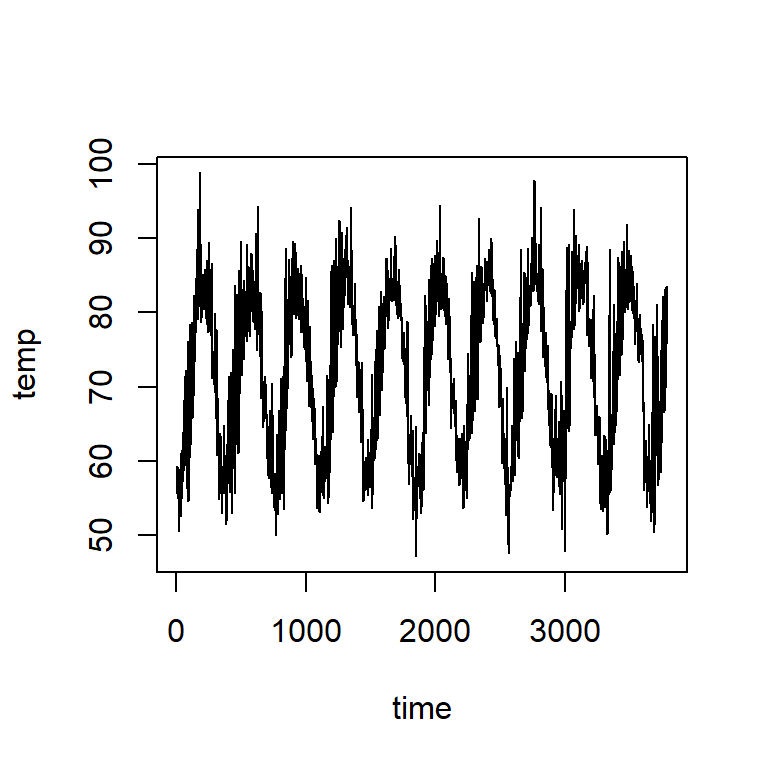
- Ajuste de un GAM
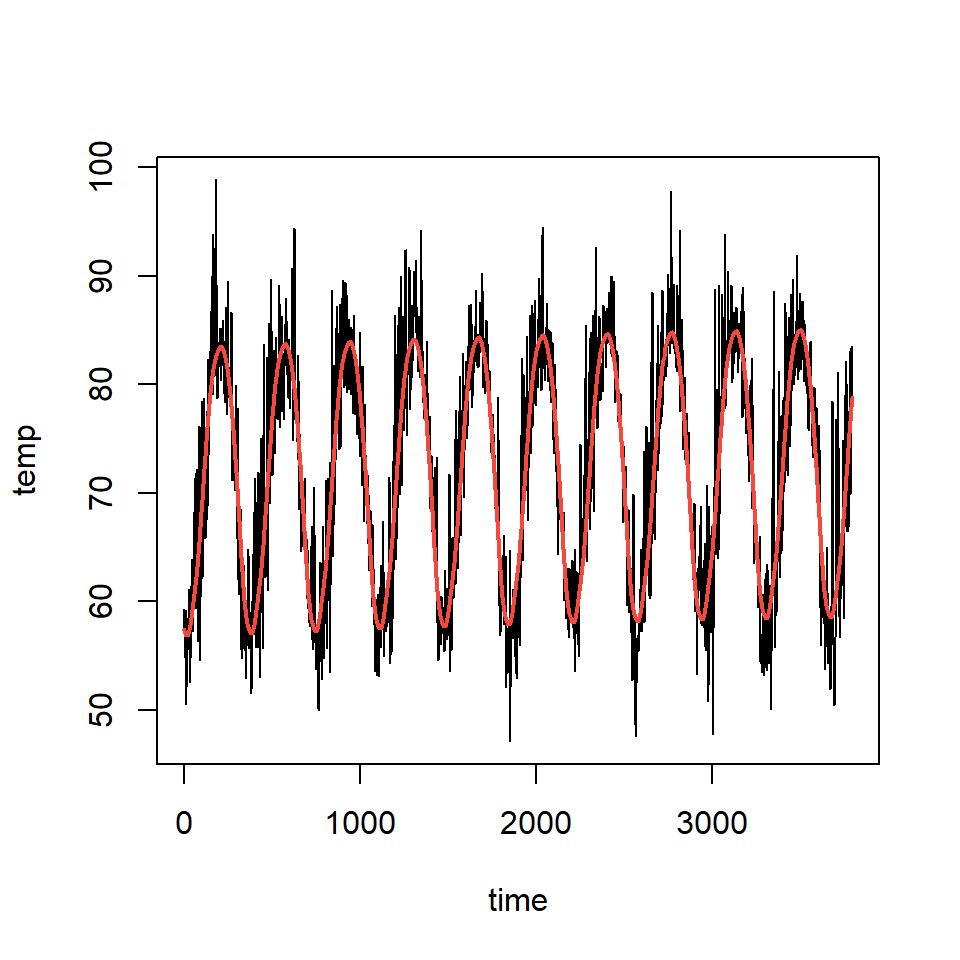
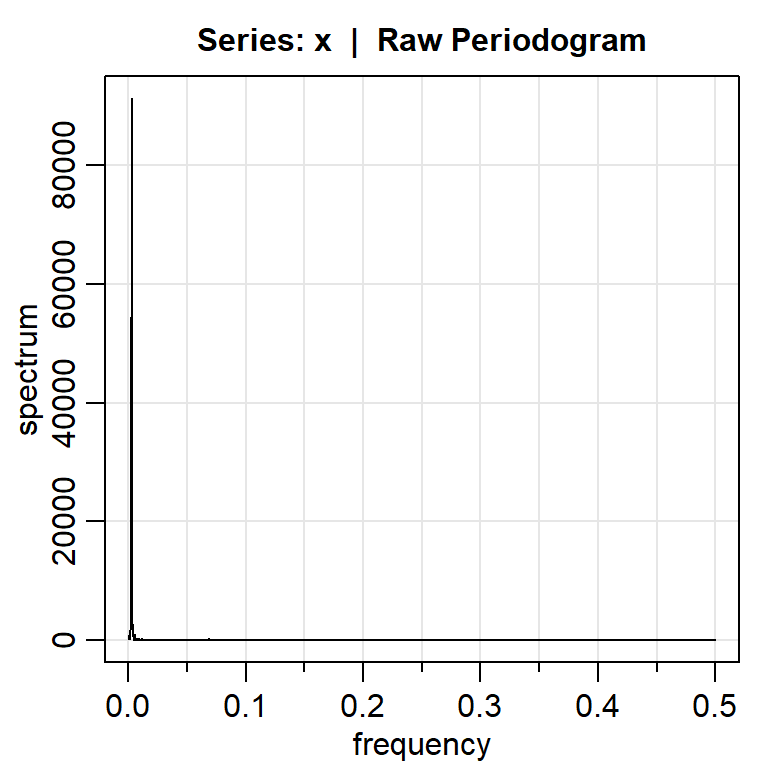
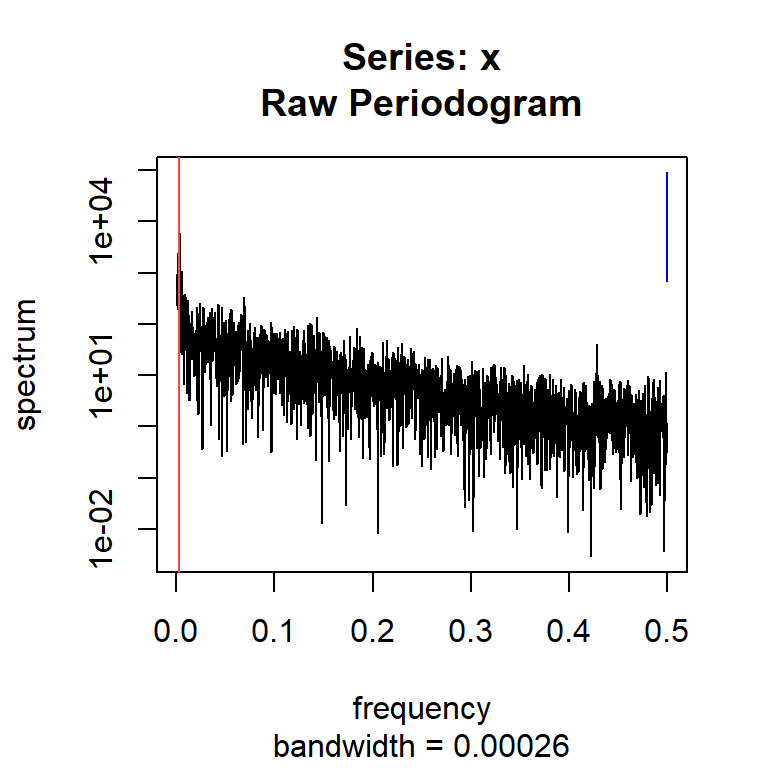
La frecuencia dominante \(\omega\) es 0.002864583, es decir, se completa un ciclo aproximadamente cada 349.09 días.
- Modelo de regresión lineal con covariables senos y cosenos \[y_t=\alpha+\beta_1 cos(2 \pi \omega t)+\beta_2 sen(2 \pi \omega t)+\varepsilon_t\]
frecuencia1 <- spectro_orden$frequency[1]
frecuencia2 <- spectro_orden$frequency[2]
frecuencia3 <- spectro_orden$frequency[3]
frecuencia4 <- spectro_orden$frequency[4]
frecuencia5 <- spectro_orden$frequency[5]
cos1<-cos(2*pi*frecuencia1*cairo$time)
sin1<-sin(2*pi*frecuencia1*cairo$time)
cos2<-cos(2*pi*frecuencia2*cairo$time)
sin2<-sin(2*pi*frecuencia2*cairo$time)
cos3<-cos(2*pi*frecuencia3*cairo$time)
sin3<-sin(2*pi*frecuencia3*cairo$time)
cos4<-cos(2*pi*frecuencia4*cairo$time)
sin4<-sin(2*pi*frecuencia4*cairo$time)
cos5<-cos(2*pi*frecuencia5*cairo$time)
sin5<-sin(2*pi*frecuencia5*cairo$time)
data=data.frame(x=x,
cos1=cos1,sen1=sin1,
cos2=cos2,sen2=sin2,
cos3=cos3,sen3=sin3,
cos4=cos4,sen4=sin4,
cos5=cos5,sen5=sin5)
mod2<-lm(x~.,data=data)
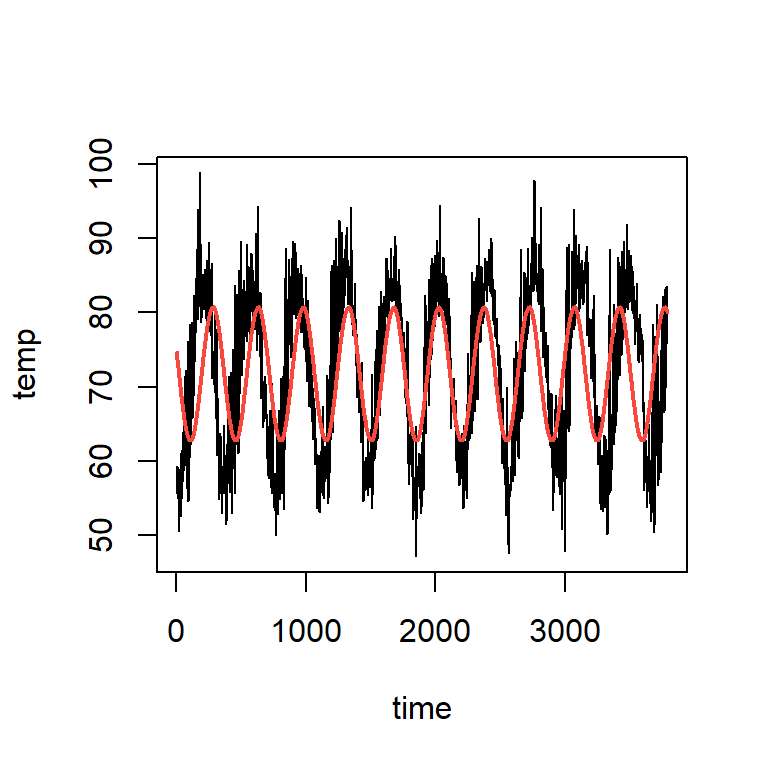
plot(cairo$temp~cairo$time,type="l", ylab="temp",xlab="time")
points(cairo$time,fitted(mod2),type="l",col=2,lwd=2)