Tema 7: Modelos de regresión dinámica

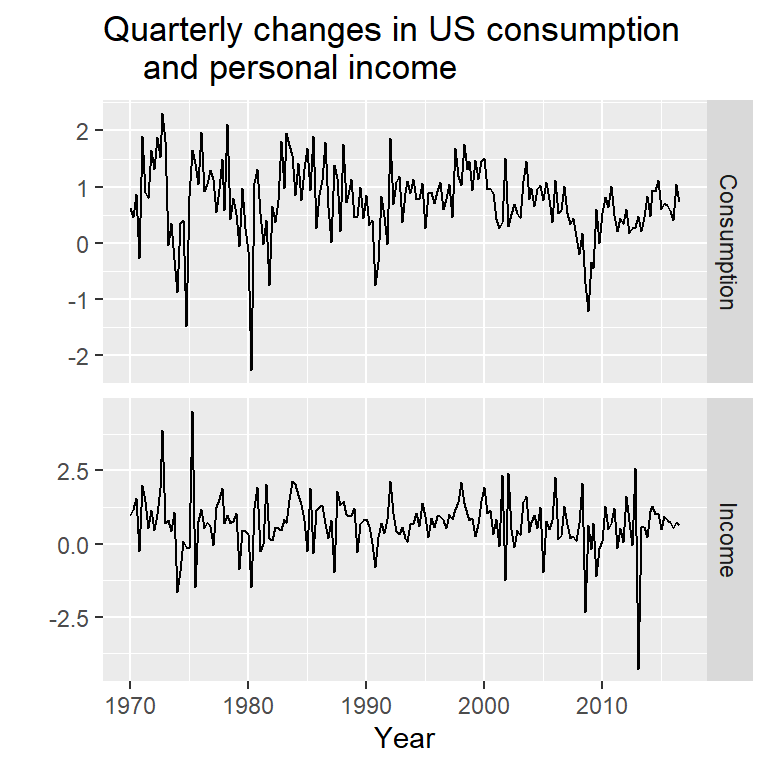
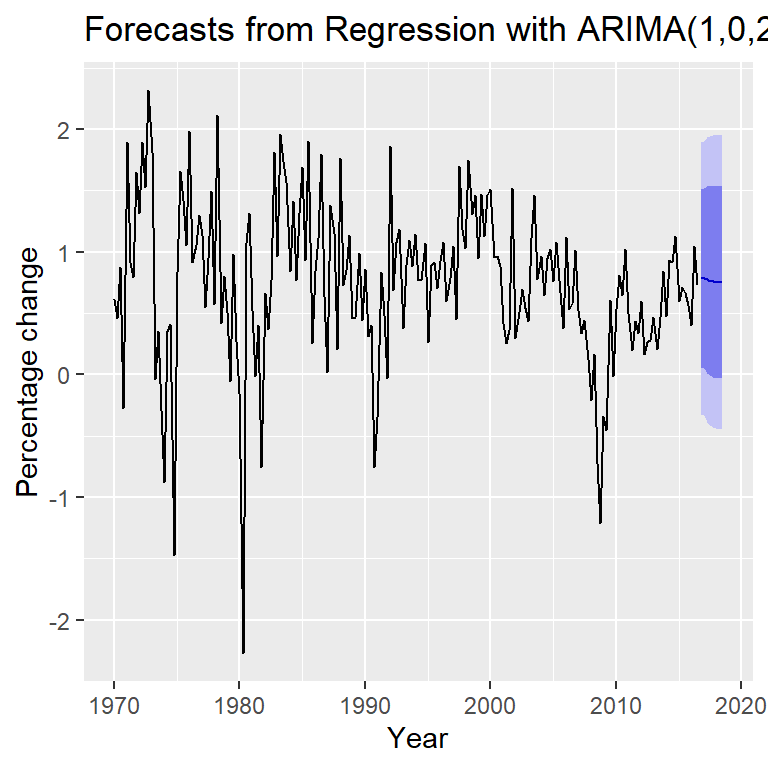
- Ejemplo tomado de Hyndman (2018): pronóstico del cambio de gasto basado en el ingreso personal (serie trimestral) de 01-1970 a 03-2016.
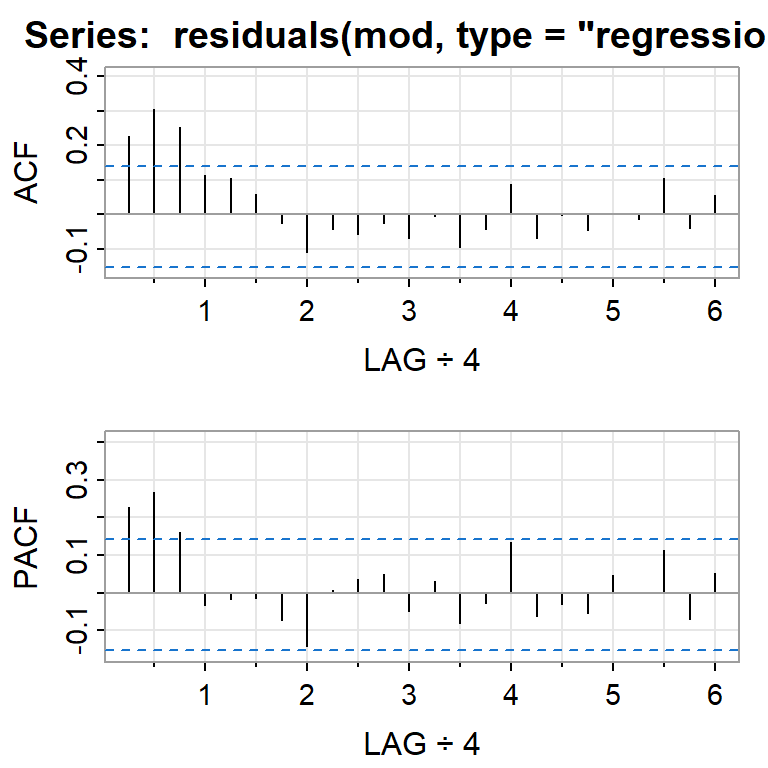
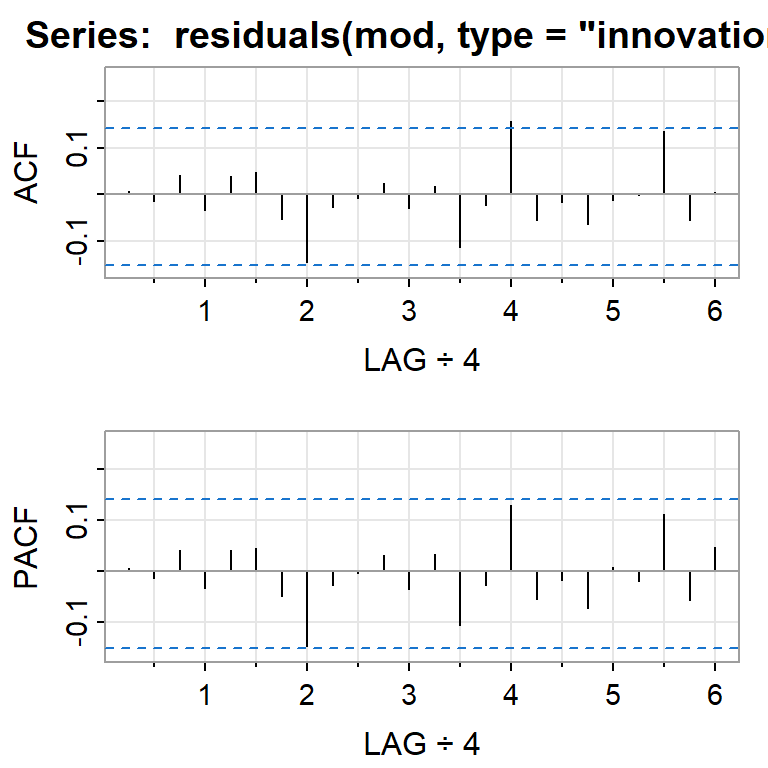
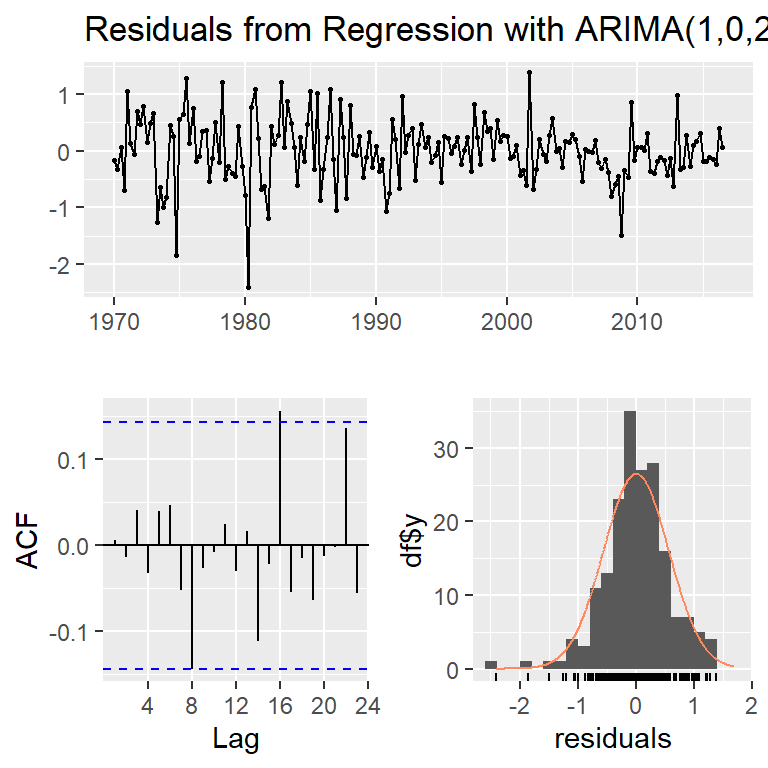
Pronóstico
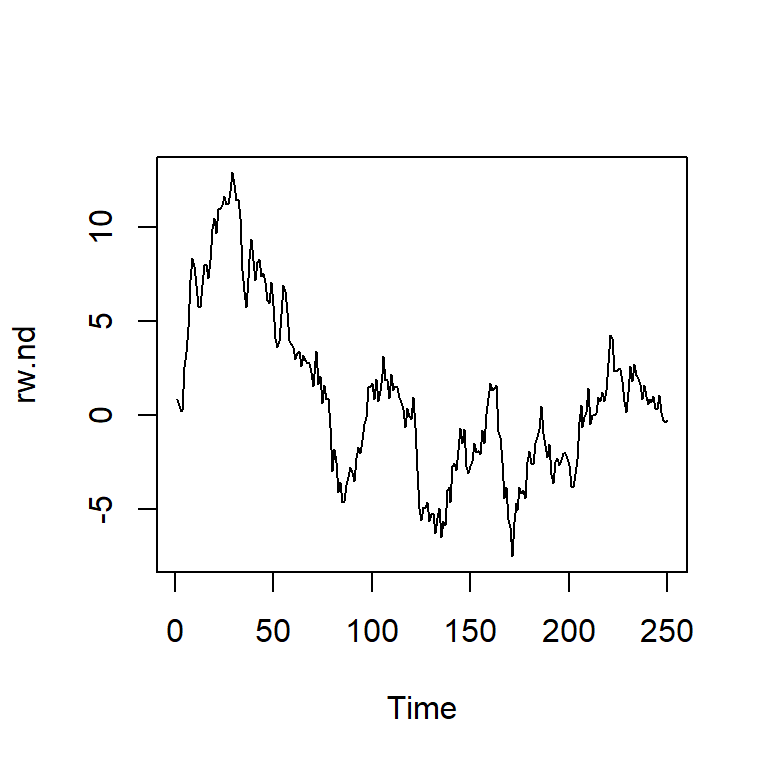
Ejemplo simulado
Tendencia determinística: \(Y_t= 0 + 0.5 t + \epsilon_t\)
Tendencia estocástica: \(Y_t = \sum_{s=1}^t \epsilon_s\)
- Tendencia determinística con tendencia estocástica: \(Y_t= 0 + 0.5 t + \sum_{s=1}^t \epsilon_s\)
tend <- 1:250 ## tendencia
dt <- e + 0.5*tend ## tendencia determinística con ruido
rw.wd <- 0.5*tend + cumsum(e) ## caminata aleatoria con desvío
plot.ts(dt, lty=1, col=1)
lines(rw.wd, lty=2, col= 2)
legend("topleft", legend=c('tend. det. + ruido',
'tend. det. + tend. est.'),
lty=c(1, 2),col=c(1,2)) 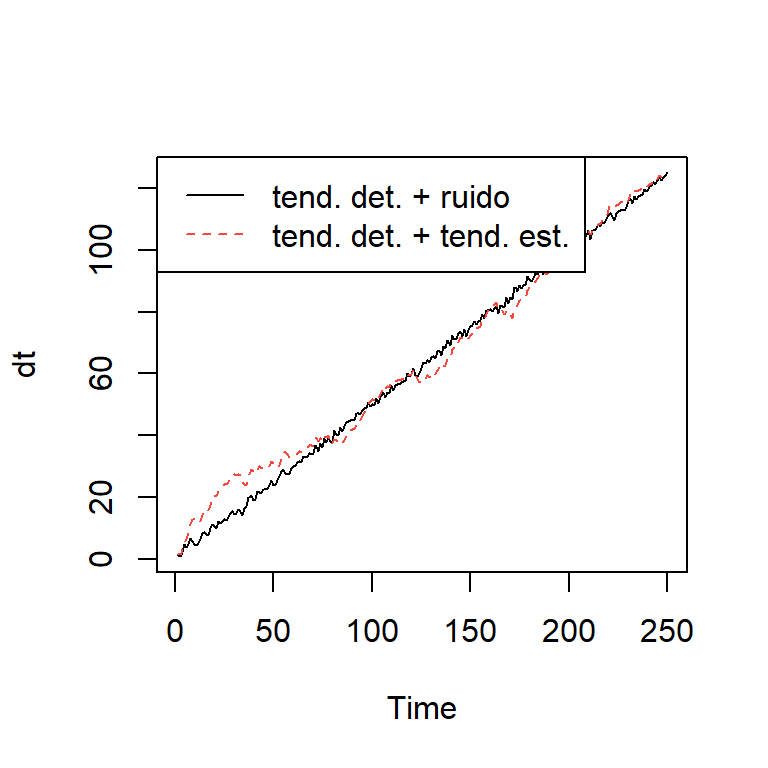
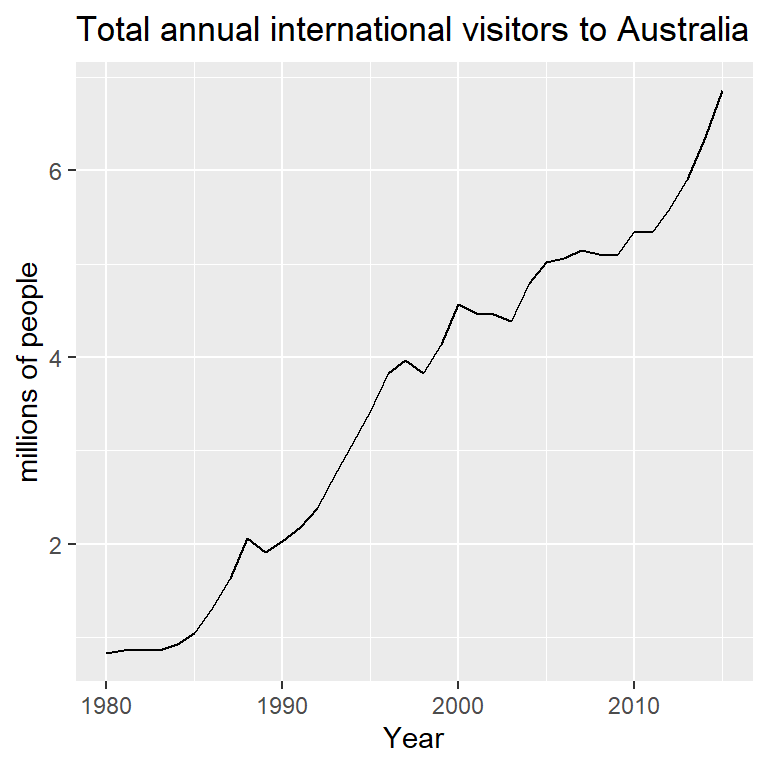
fc1 <- forecast(fit1,
xreg = length(austa) + 1:10)
fc2 <- forecast(fit2, h=10)
autoplot(austa) +
autolayer(fc2, series="Stochastic trend") +
autolayer(fc1, series="Deterministic trend") +
ggtitle("Forecasts from trend models") +
xlab("Year") + ylab("Visitors to Australia (millions)") +
guides(colour=guide_legend(title="Forecast"))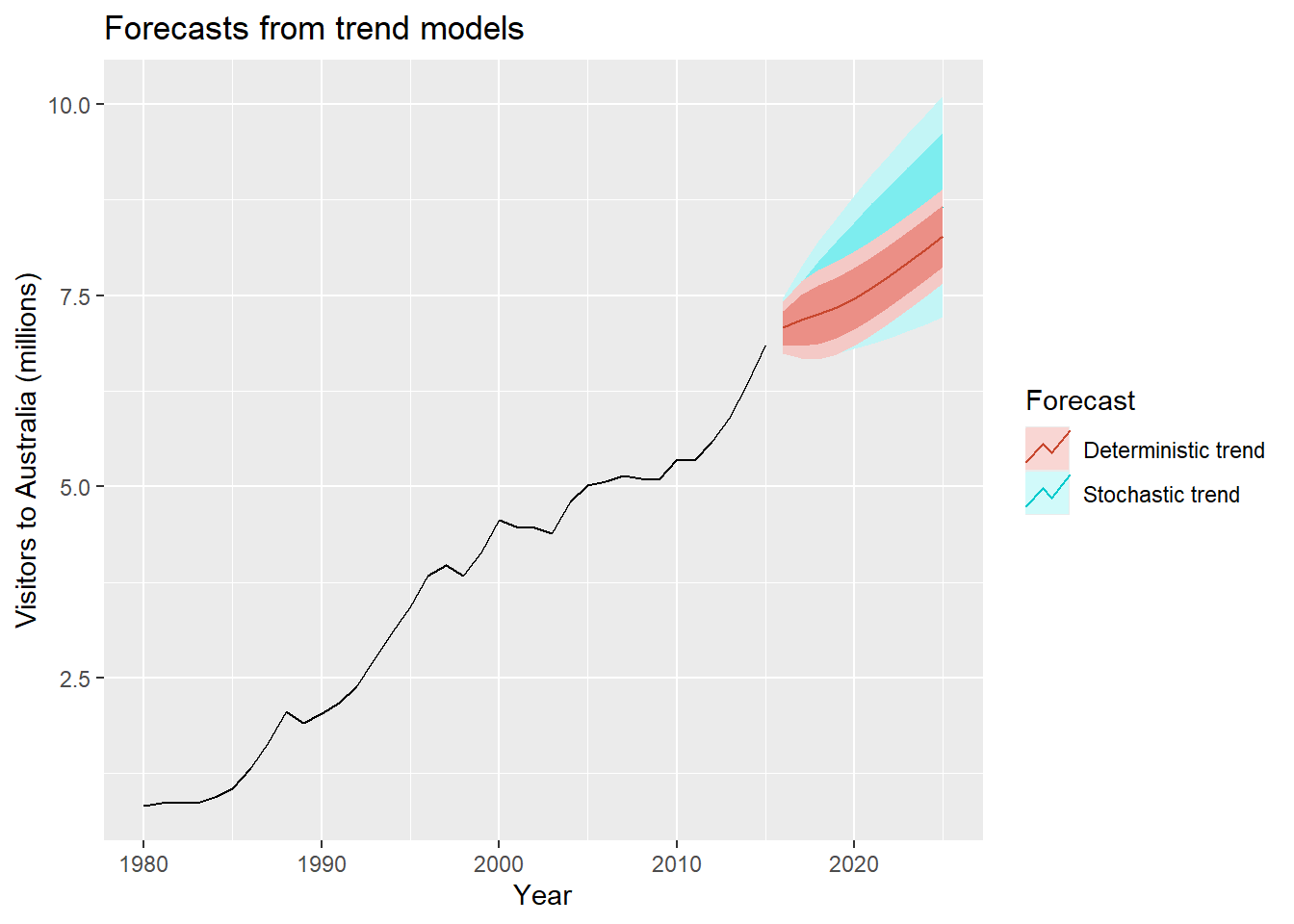
Regresión con covariables rezagadas
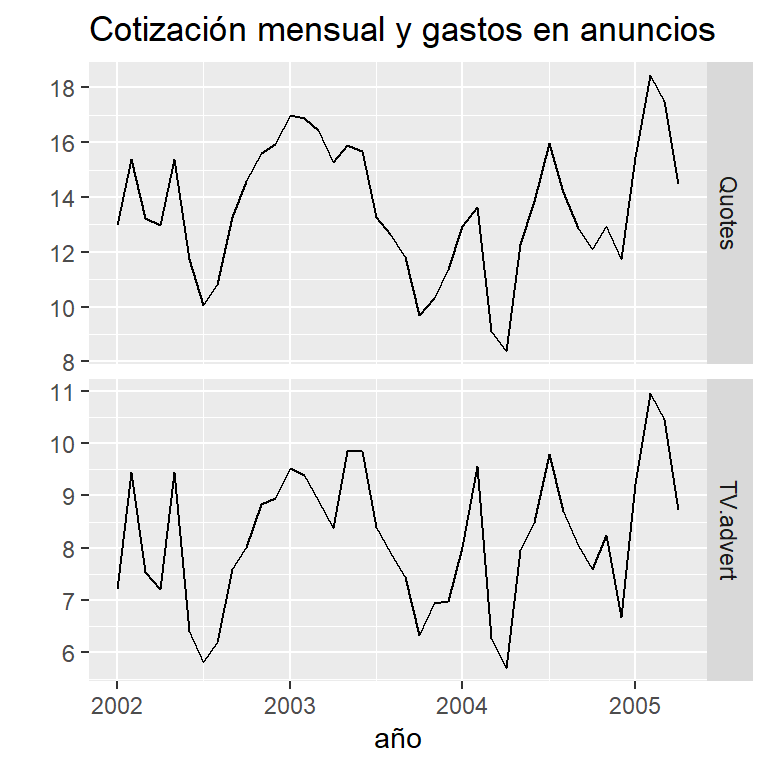
- Cotización mensual y gastos en publicidad de una compañía estadounidense (enero 2002- abril 2005)
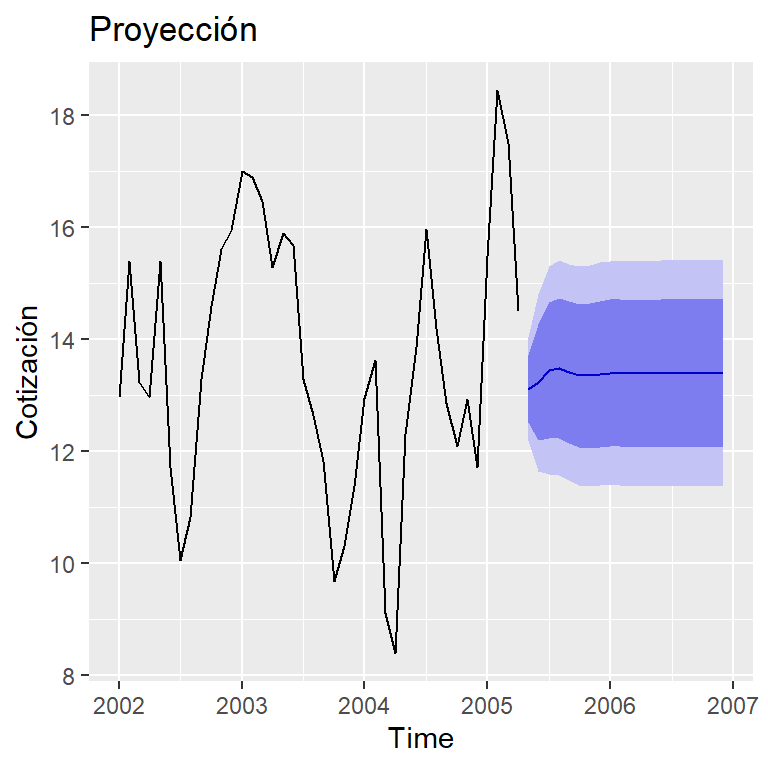
pronóstico
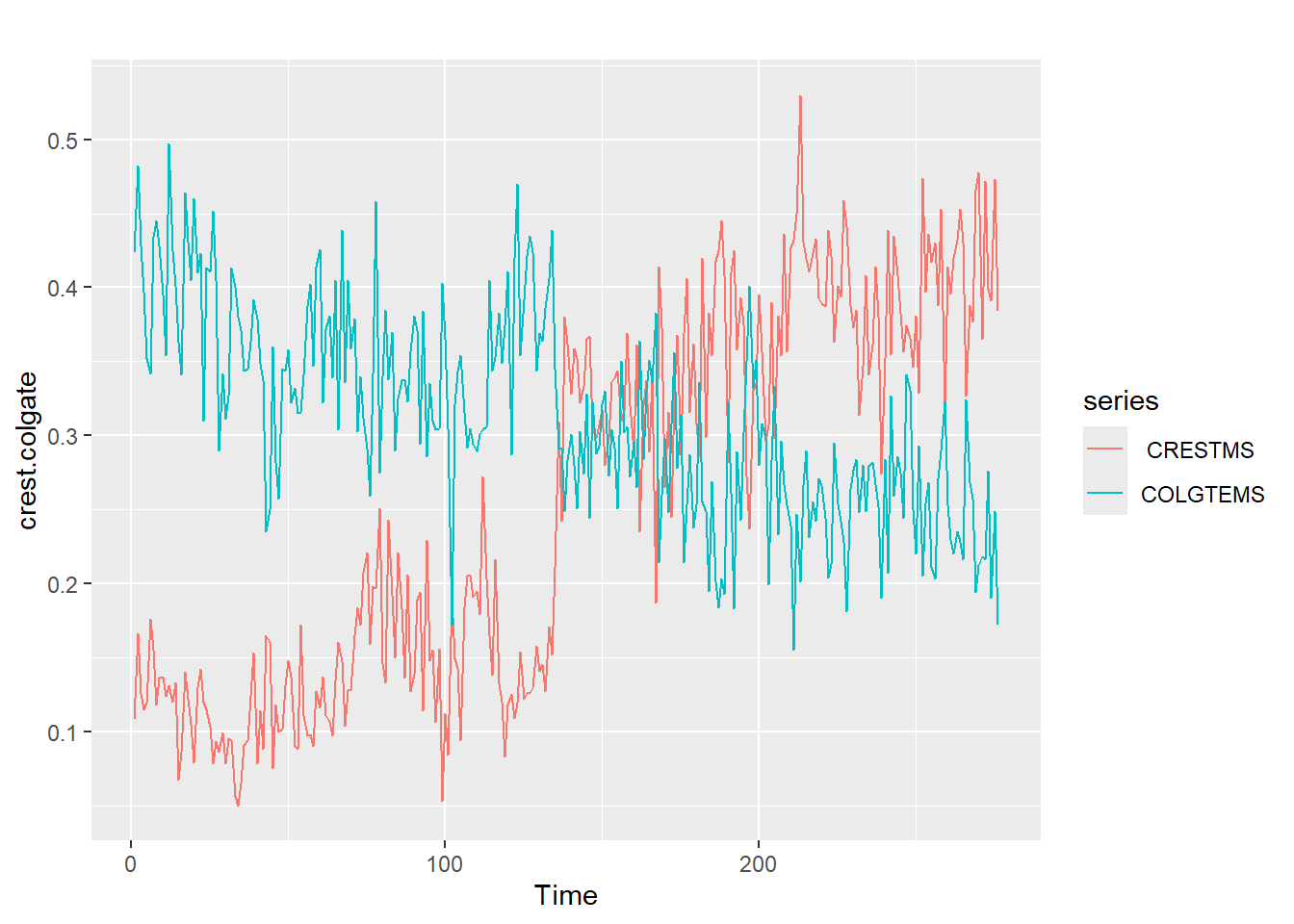
Ejemplo de Crest
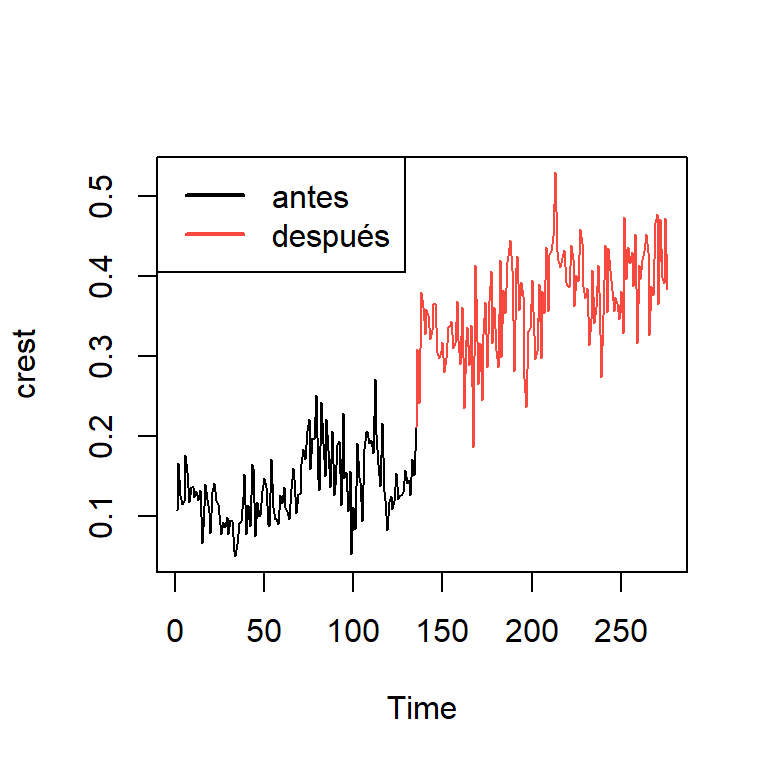
- Series semanales de cuotas de mercado dentífrico de las marcas Colgate y Crest en los Estados Unidos de 1 de enero de 1958 al abril de 1963.
- Al inicio, Colgate aventajaba a la marca Crest en el mercado.
- El 1 de agosto de 1960 ocurrió el cambio de comportamiento: la Asociación Dental Americana dio un respaldo enorme a la marca Crest al hacer público que era una pasta dental eficaz para prevenir las caries dentales.
- Procter y Gamble, la compañía que producía la marca Crest, aprovechó y divulgó intensamente durante dos semanas el enuncio.
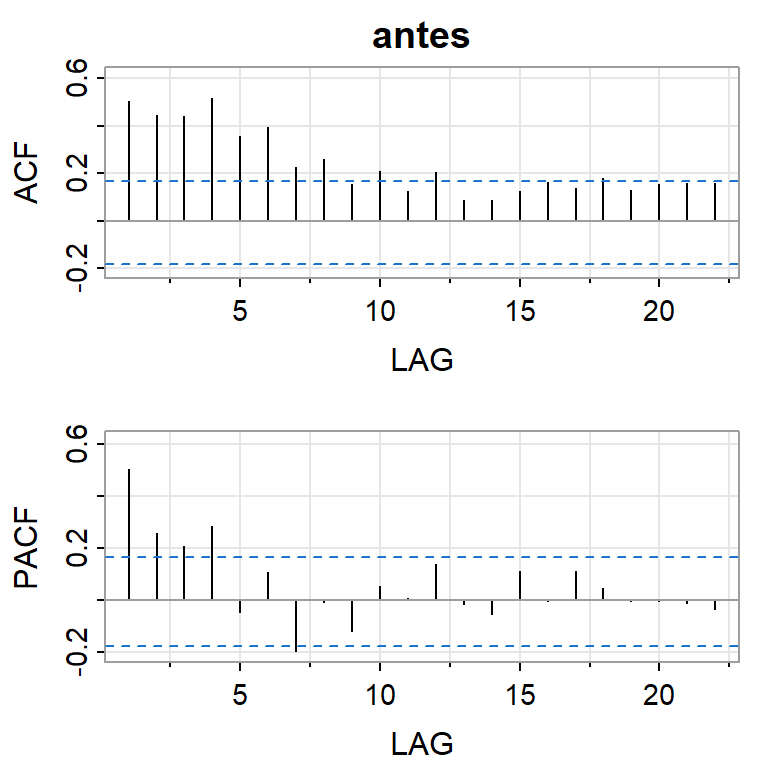
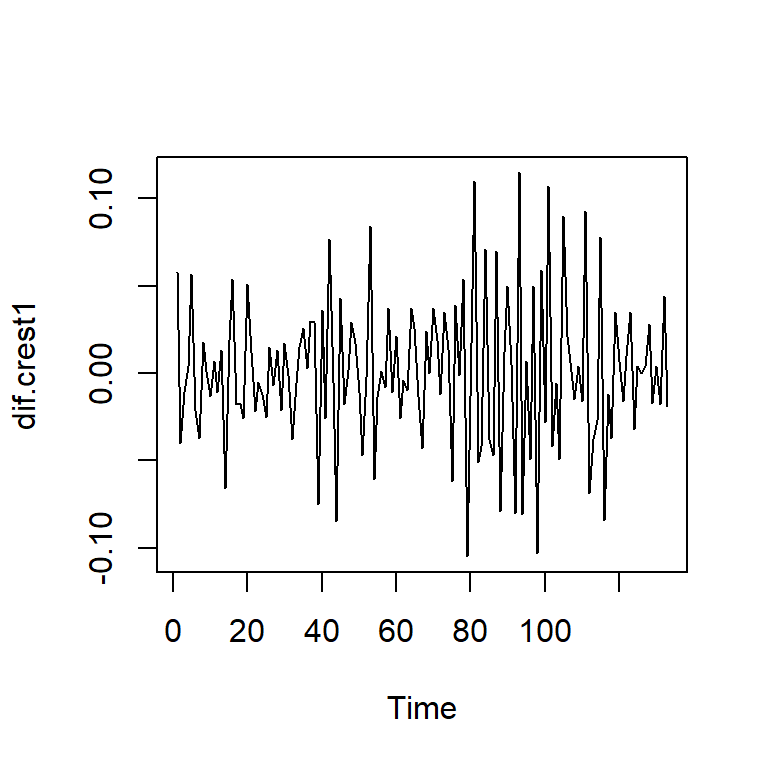
- Serie diferenciada (antes de la intervención)
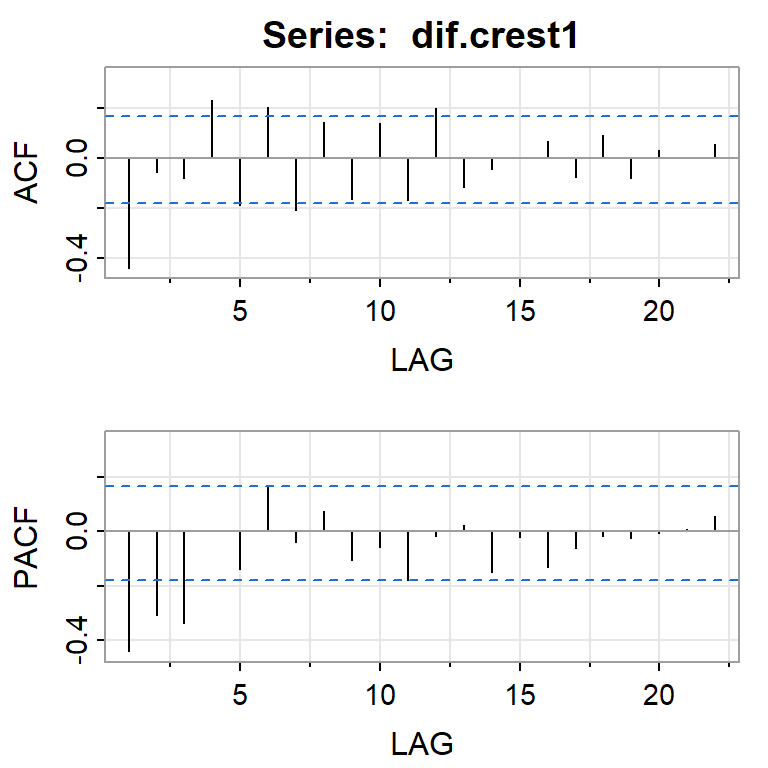
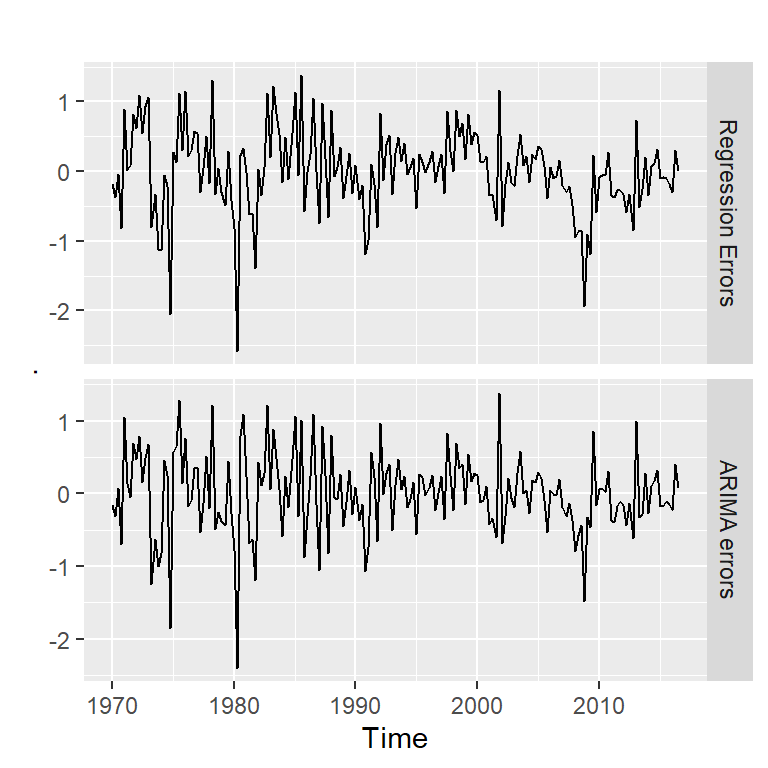
Ljung-Box test
data: Residuals from Regression with ARIMA(0,1,1) errors
Q* = 16.273, df = 19, p-value = 0.639
Model df: 1. Total lags used: 20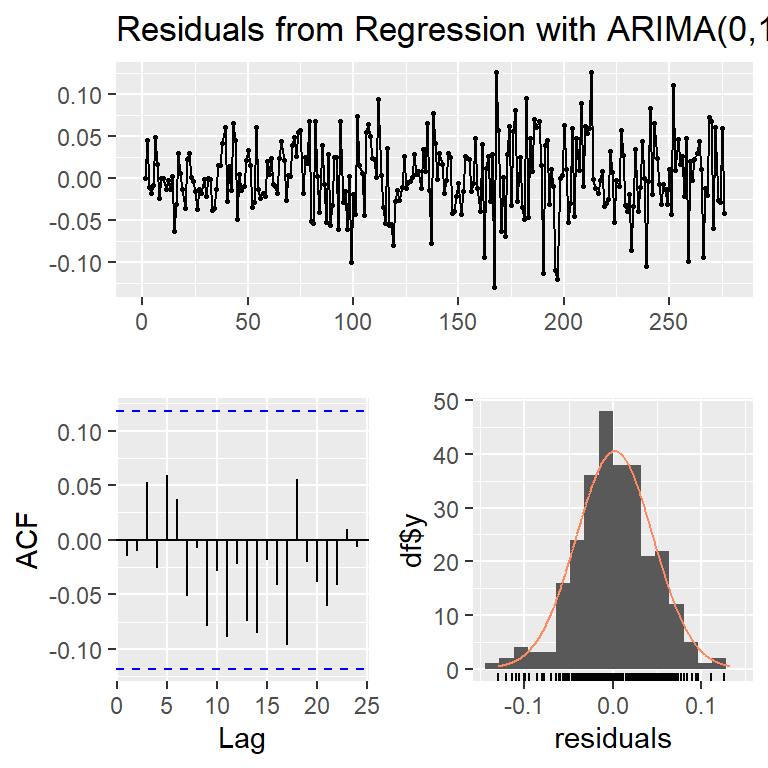
Análisis de intervención
- De manera formal, un modelo de intervención se define como \[Z_t = m_t + N_t,\] donde \(N_t \sim ARIMA(p,d,q)\) (Podría ser SARIMA).
- Una intervención que produce un cambio inmediato y permanente, se puede modelar con
\[m_t = \omega S_t^{(T)},\]
donde \(S_t^{(T)}\) es una función escalonada \[S_t^{(T)} = \begin{cases} 1, & t \geq T, \\ 0, & t < T. \end{cases}\]
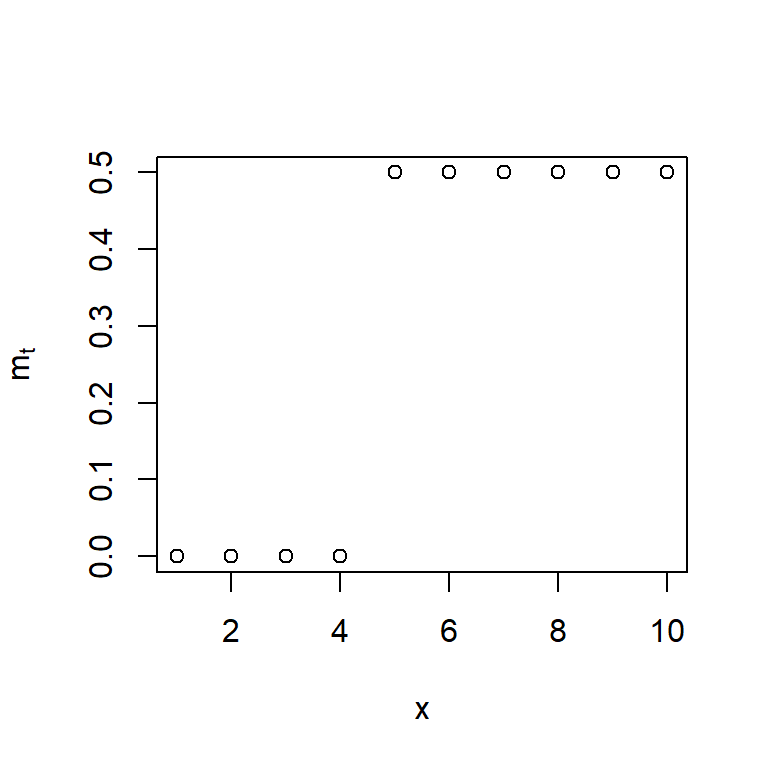
- Note que es posible establecer un efecto rezagado de período \(d\).
\[m_t = \omega S_{t-d}^{(T)}=\omega B^d S_{t}^{(T)},\]
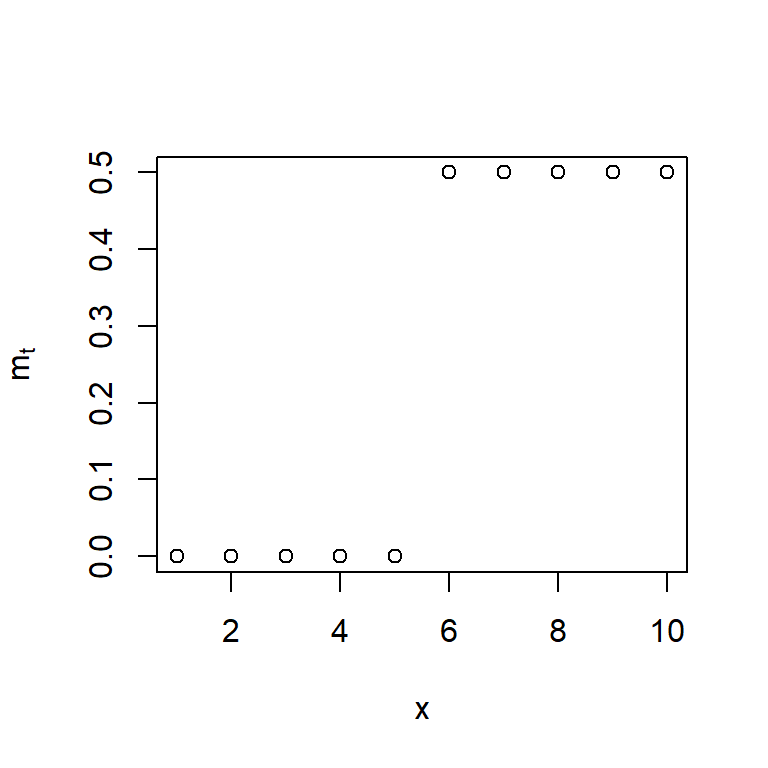
- Otro tipo de intervención produce solamente un cambio inmediato en el tiempo \(t\):
\[m_t = \omega P_t^{(T)},\]
donde \(P_t^{(T)} = S_t^{(T)} - S_{t-1}^{(T)}\) es una función de impulso. \[P_t^{(T)} = \begin{cases} 1, & t = T, \\ 0, & t \neq T. \end{cases}\]
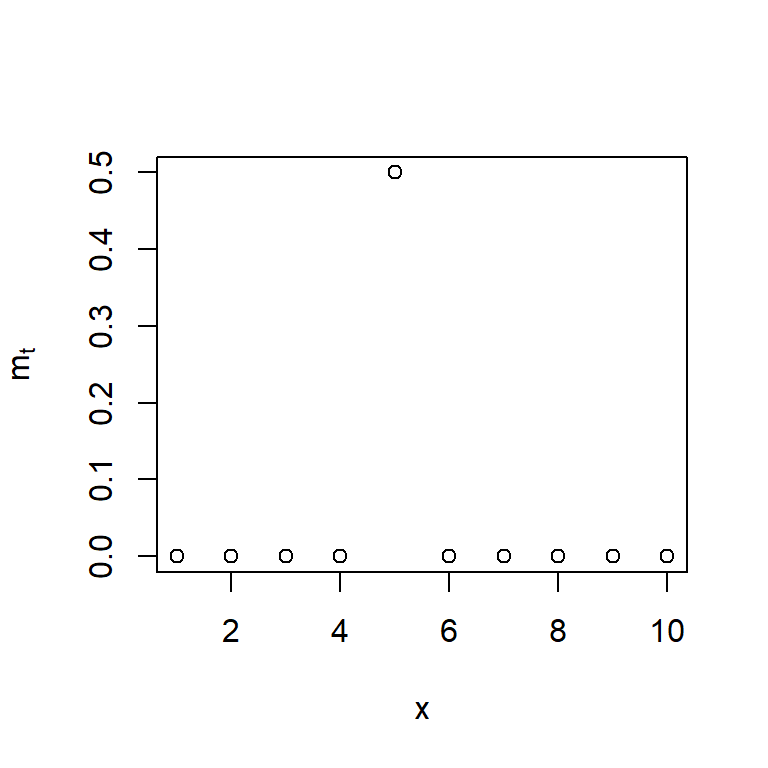
- Otros tipos de intervención se puede incorporar con la especificación de una ecuación tipo AR(1) y con \(d=1\):
\[m_t = \delta m_{t-1} + \omega S_{t-1}^{(T)},\] con la condición inicial de \(m_0=0\).
- Se puede mostrar que con el uso del operador de rezago \(B\), se puede escribir como
\[m_t = \begin{cases} \omega \frac{1-\delta^{t-T}}{1-\delta}, & t > T, \\ 0, & t \leq T. \end{cases}\]
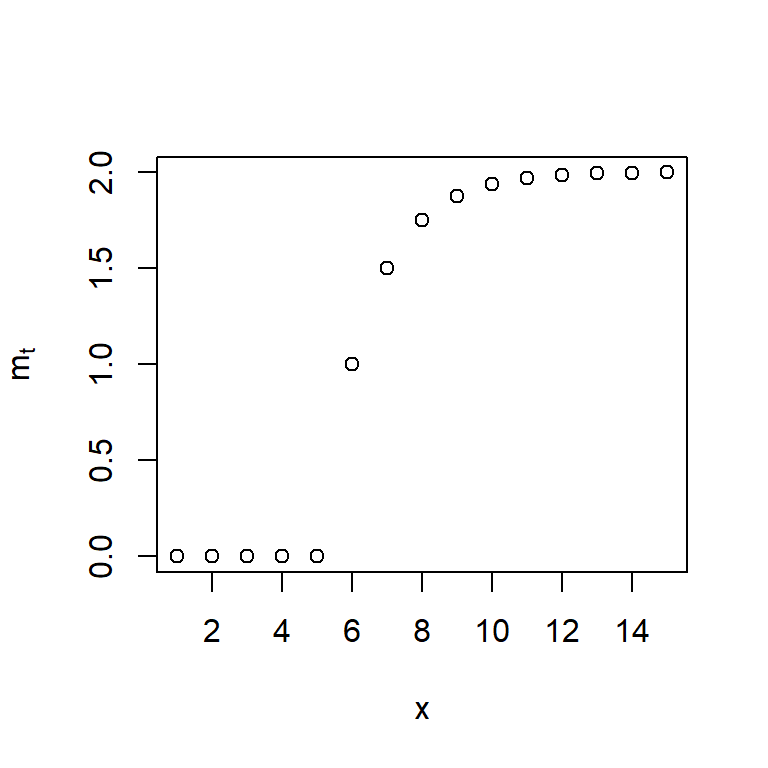
- De igual forma, se puede incorporar con la especificación de una ecuación tipo AR(1) y con \(d=1\) a \(P_{t}^{(T)}\):
\[m_t = \delta m_{t-1} + \omega P_{t-1}^{(T)},\] con la condición inicial de \(m_0=0\).
- Con el uso del operador de rezago \(B\), se puede escribir como
\[m_t =\omega \frac{B}{1-\delta B} P_{t}^{(T)} \]
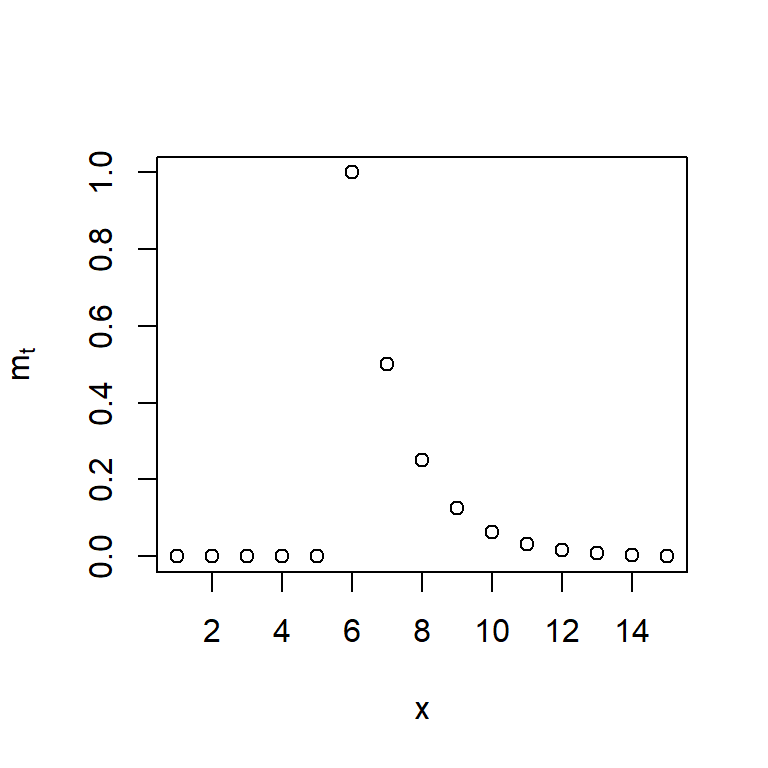
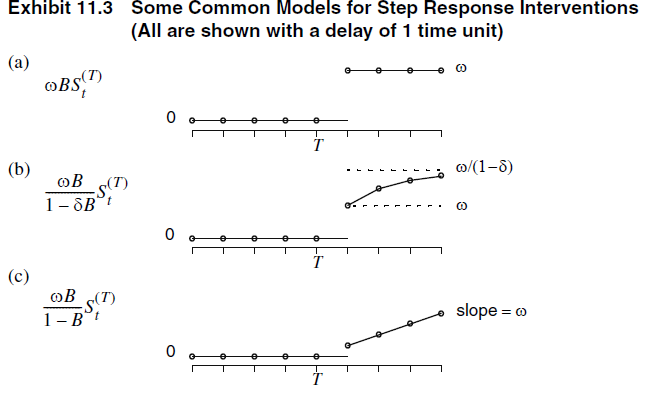
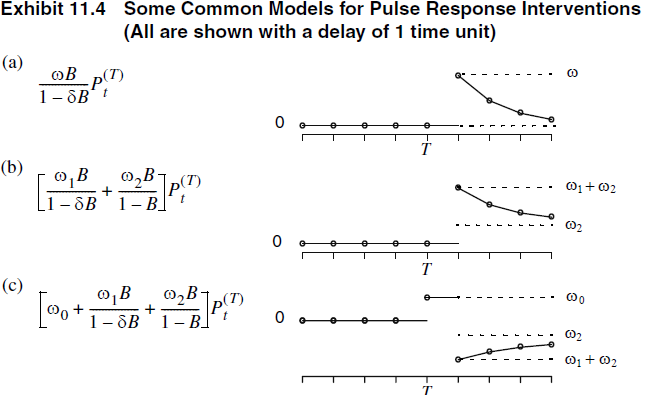
Fuente: Capítulo 11 del Cryer & Chan (2008) Time Series Analysis with Applications in R.
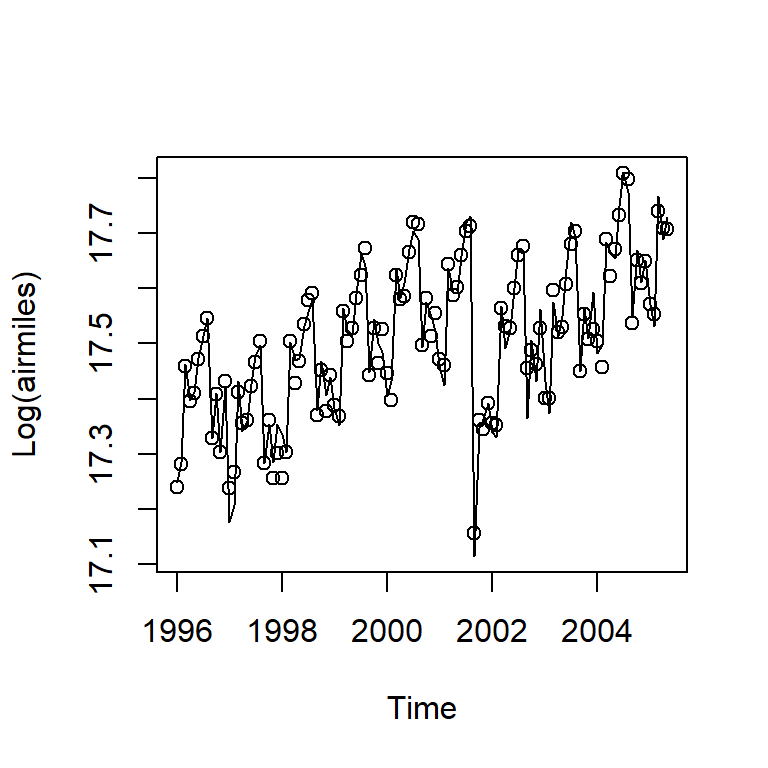
Ejemplo de millas mensuales de pasajeros
- Los datos se tratan de las millas mensuales de pasajeros de aerolíneas en los E.U de enero 1996 a mayo de 2005.
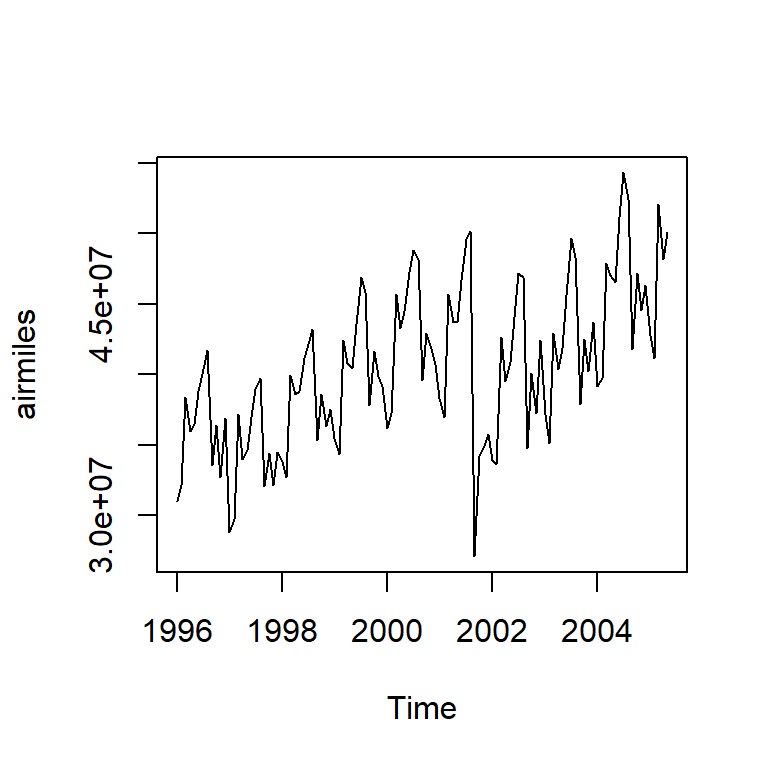
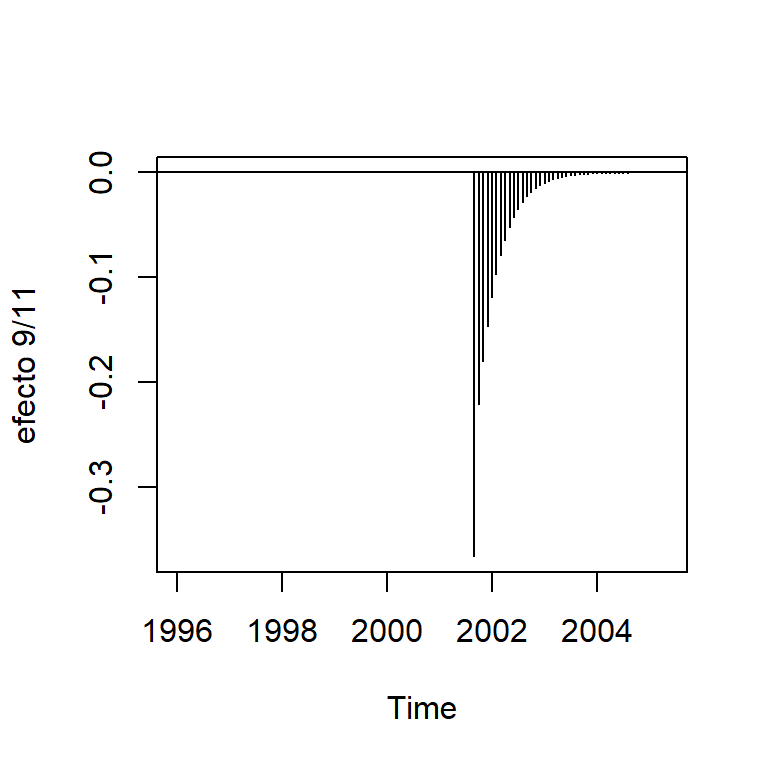
Los ataques terroristas en septiembre 2001 causó un efecto instantáneo (negativo) y lentamente se recupera a lo largo del período.
Por lo que este modelo para intervención es utilizado \[m_t = \omega_0 P_t^{(T)} + \frac{\omega_1}{1-\omega_2 B}P_t^{(T)},\] donde \(T\) es septiembre de 2001. \(\omega_0+\omega_1\) representa el efecto del mes y \(\omega_1 \omega_2^k, k=0,1,2,...\) representa el efecto de decaimiento exponencial.
- Usando los datos antes de la intervención, un \(SARIMA(0,1,1)(0,1,0)_{12}\) es identificado.
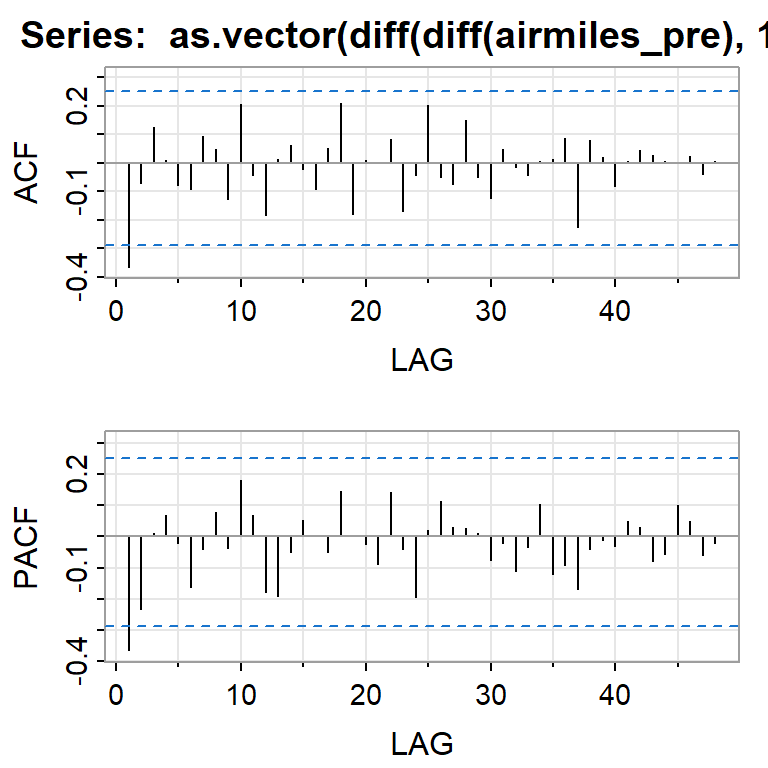
- Después de la estimación y diagnósticos, se volvió a identificar un componente de SMA(1) que resulta ser relevante.