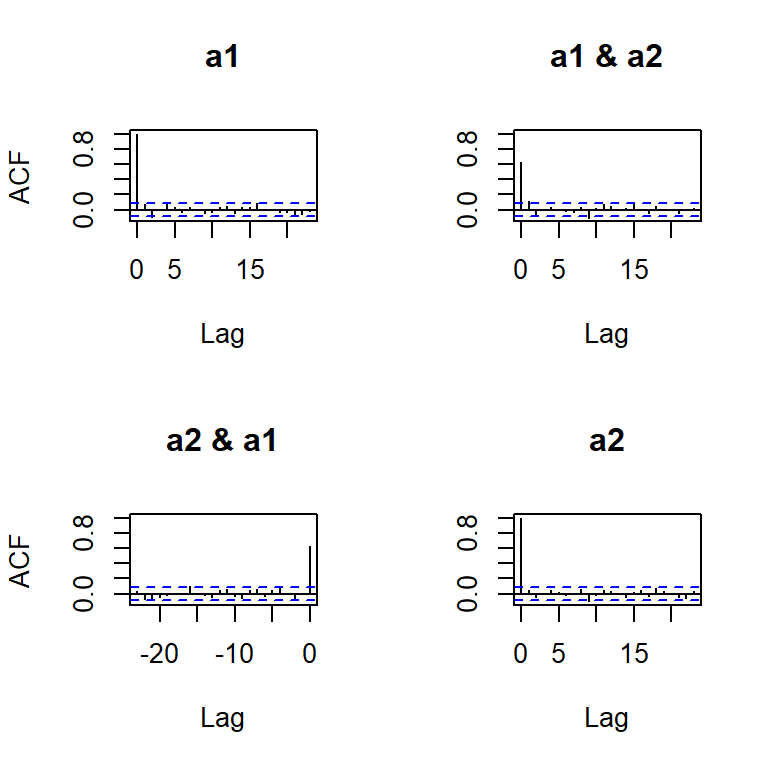En la práctica, es común enfrentar situaciones en donde se presentan varias series temporales.
Objetivos:
Estudiar la relación dinámica de las variables de interés en el tiempo.
Mejorar las predicciones.
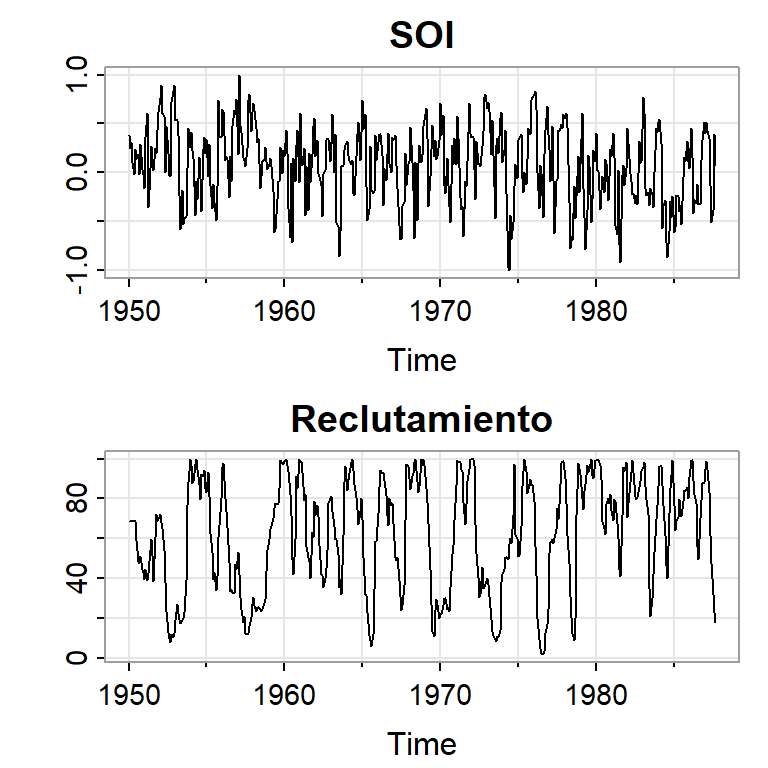
Ejemplo 1: El Niño y la población de peces
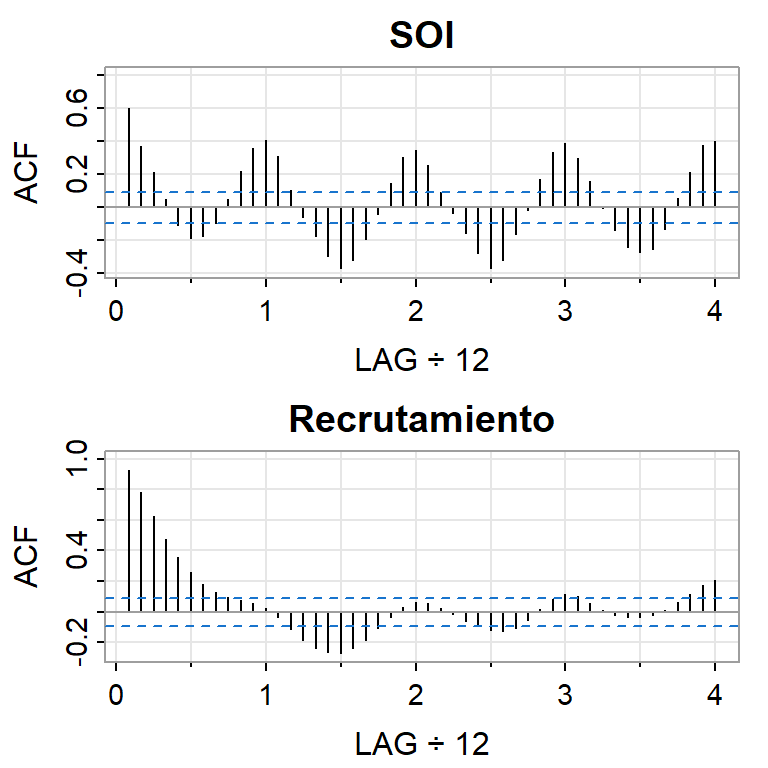
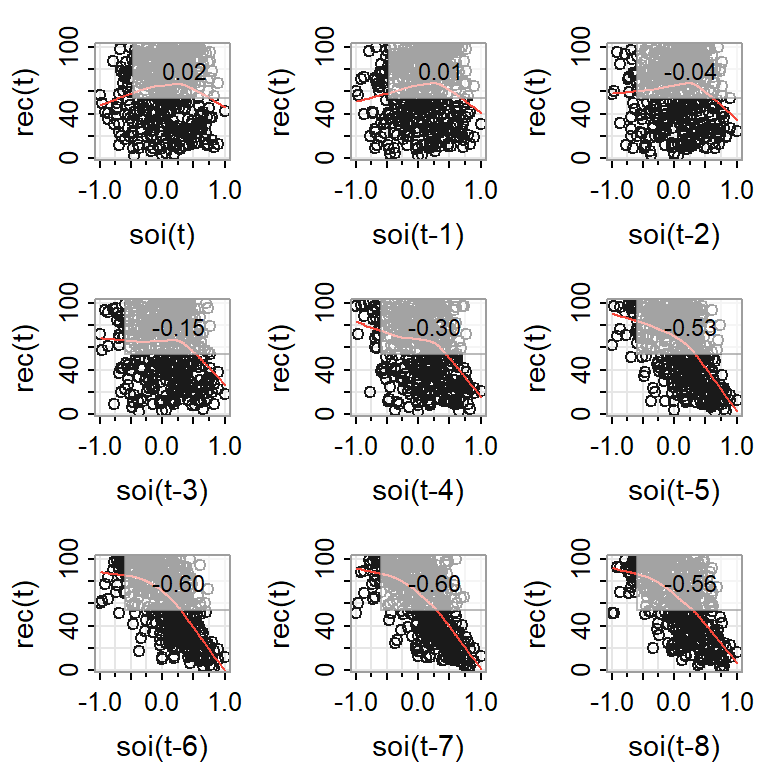
Se tiene la serie ambiental de índice de oscilación del sur (SOI, Southern Oscillation Index), y la serie de número de peces nuevos (Reclutamiento) de 453 meses de 1950 a 1987.
SOI mide cambios en presión relacionada a la temperatura del superficie del mar en el oceano pacífico central, el cual se calienta cada 3-7 años por el efecto El Niño.
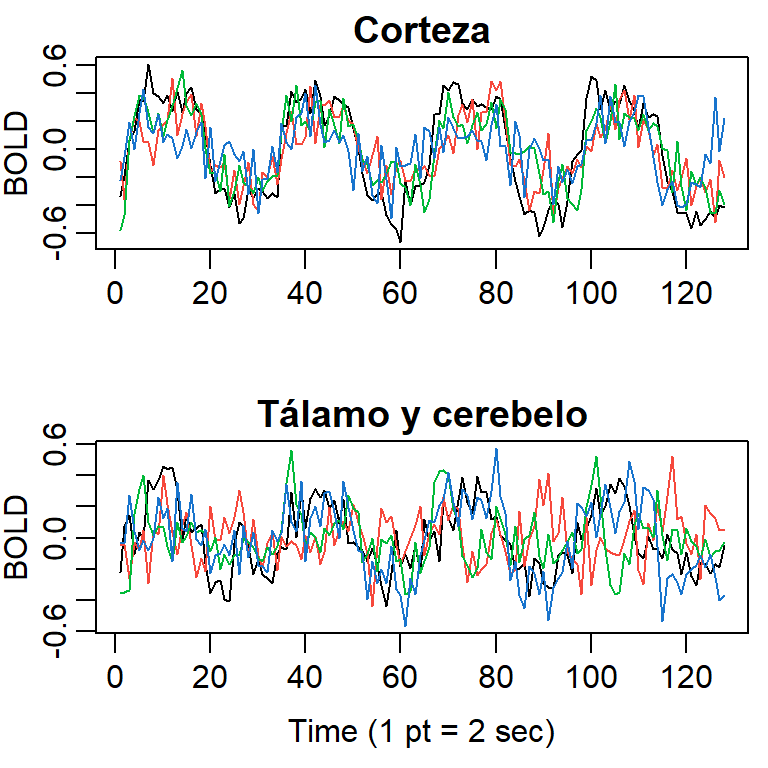
Un estímulo fue aplicado a cinco personas en la mano por 32 segundos y luego paró el estímulo por otros 32 segundos, sucesivamente.
Durante 256 segundos, cada 2 segundos se registró la intensidad del dependiente del nivel en la sangre (BOLD, blood oxygenation-level dependent signal intensity), la cual mide áreas de activación en el celebro \((T=128)\).
Definición 1 (Estacionariedad conjunta (bivariada)) Dos series temporales, \(X_t\) y \(Y_t\) se dicen que son conjuntamente estacionarias, si cada serie es estacionaria, y la función de covariancia cruzada
\[\gamma_{XY}(h)= Cov(X_{t+h},Y_t) =E\left[ (X_{t+h}-\mu_{X})(Y_t-\mu_{Y}) \right]\] es una función que solamente depende de \(h\).
De esta forma, podemos definir la función de correlación cruzada de dos series temporales conjuntamente estacionarias por \[\rho_{XY}(h)=\frac{\gamma_{XY}(h)}{\sqrt{\gamma_X(0),\gamma_Y(0)}}\]
Propiedades:
\(-1 \leq \rho_{XY}(h) \leq 1\)
\(\rho_{XY}(h) \neq \rho_{XY}(-h)\) pues \(Cov(X_2,Y_1)\) y \(Cov(X_1,Y_2)\) no siempre son iguales.
\(\rho_{XY}(h) = \rho_{YX}(-h)\)
Estimación
la función de autocovariancia cruzada muestral es definida por \[\hat{\gamma}_{XY}(h)=\frac{1}{T}\sum_{t=1}^{T-h} (X_{t+h}-\bar{X})(Y_{t}-\bar{Y}),\]
Note que \(\hat{\gamma}_{XY}(-h)=\hat{\gamma}_{YX}(h)\) para \(h=0,1,...,T-1\).
La función de autocorrelación cruzada muestral es definida por \[\hat{\rho}_{XY}(h)=\frac{\hat{\gamma}_{XY}(h)}{\sqrt{\hat{\gamma}_X(0)\hat{\gamma}_Y(0)}}\]Propiedad: La distribución de \(\hat{\rho}_{XY}(h)\) para \(T\) grande es aproximadamente normal con media cero y \[\sigma_{\hat{\rho}_{XY}}=\frac{1}{\sqrt{T}}.\]
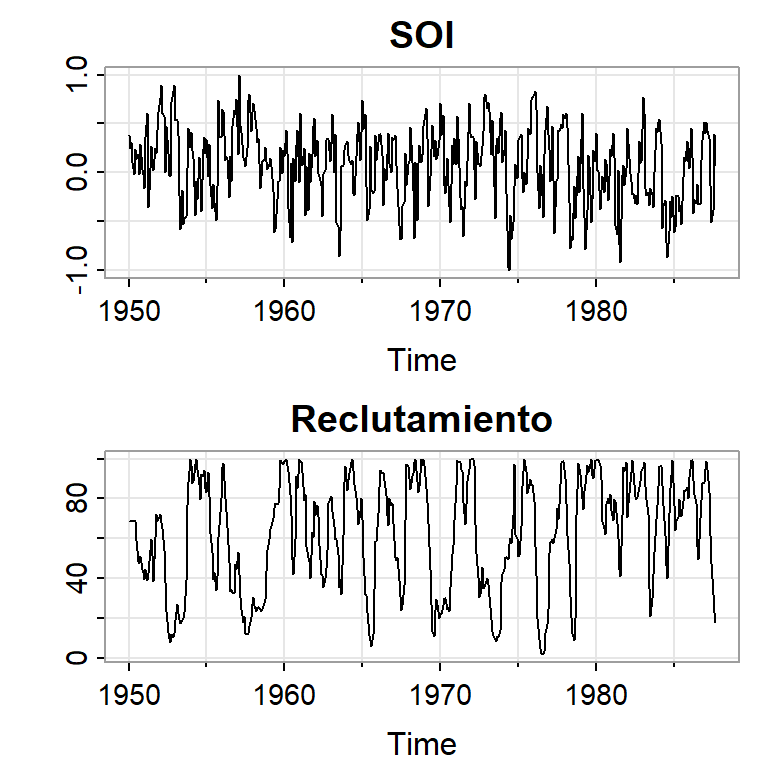
Ejemplo 1: El Niño y la población de peces
Se tiene la serie ambiental de índice de oscilación del sur (SOI, Southern Oscillation Index), y la serie de número de peces nuevos (Reclutamiento) de 453 meses de 1950 a 1987.
SOI mide cambios en presión relacionada a la temperatura del superficie del mar en el oceano pacífico central, el cual se calienta cada 3-7 años por el efecto El Niño.
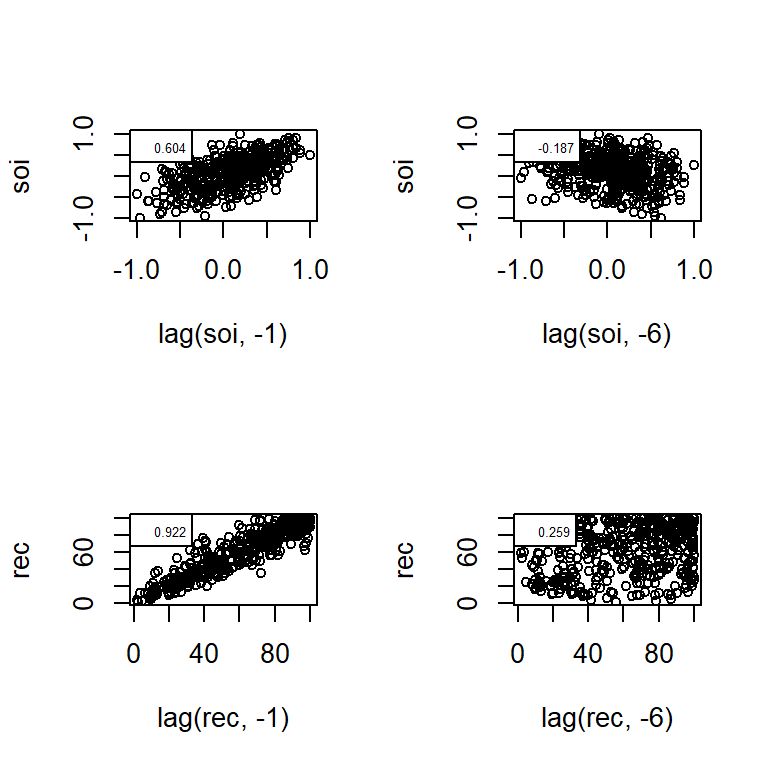
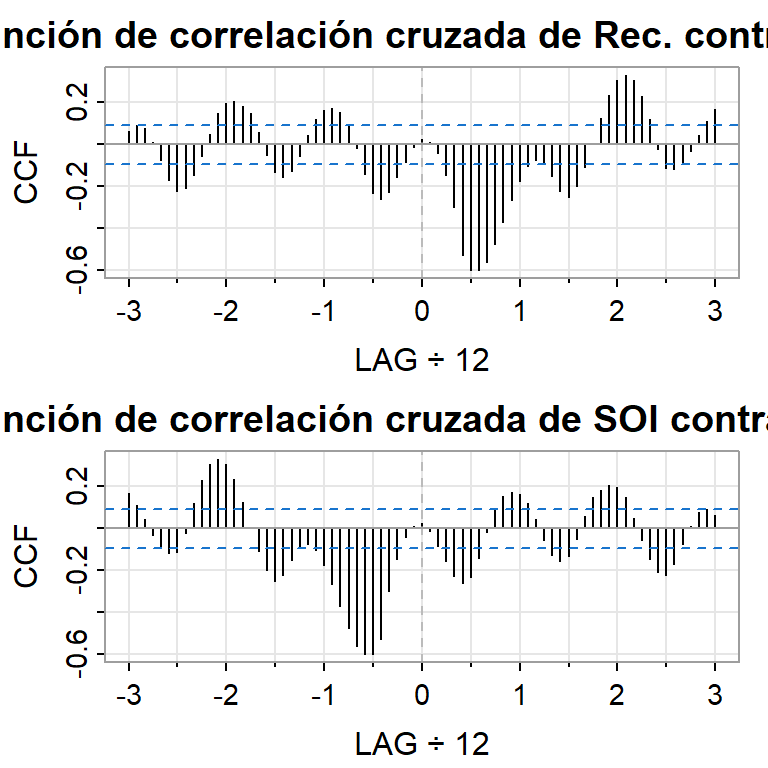
par(mfrow=c(2,1))ccf2(rec,soi, 36, main="función de correlación cruzada de Rec. contra SOI")ccf2(soi,rec, 36, main="función de correlación cruzada de SOI contra Rec.")
(r1=ccf(rec,soi, 5, plot=FALSE))
Autocorrelations of series 'X', by lag
-0.4167 -0.3333 -0.2500 -0.1667 -0.0833 0.0000 0.0833 0.1667 0.2500 0.3333
-0.259 -0.228 -0.154 -0.086 -0.013 0.025 0.011 -0.042 -0.146 -0.297
0.4167
-0.527
(r2=ccf(soi,rec, 5, plot=FALSE))
Autocorrelations of series 'X', by lag
-0.4167 -0.3333 -0.2500 -0.1667 -0.0833 0.0000 0.0833 0.1667 0.2500 0.3333
-0.527 -0.297 -0.146 -0.042 0.011 0.025 -0.013 -0.086 -0.154 -0.228
0.4167
-0.259
Note que \(\hat{\rho}_{XY}(h) = \hat{\rho}_{YX}(-h)\).
Medidas de dependencia (multivariada)
Contenido
Introducción
Medidas de dependencia (bivariada)
Medidas de dependencia (multivariada)
Estacionariedad
VAR(p)
Diagnósticos
ARMAX(p,q) vectorial
Medidas de dependencia (multivariada)
La generalización a series temporales multivariadas con \(k\) componentes, \(X_{t1},...X_{tk}, t=1,...,T\), es intuitivo:
El vector de medias es función del tiempo \(t\): \[\mu_t=E(X_t)=\left(\begin{array}{c} \mu_{t1}\\ \vdots \\ \mu_{tk} \end{array}\right).\]
La función de autocovariancia cruzada:
\[\gamma_{ij}(t,s)= Cov(X_{ti},X_{sj}) =E\left[ (X_{ti}-\mu_{ti})(X_{sj}-\mu_{sj}) \right]\] para \(i,j=1,...,k.\)
O bien, la matriz de autocovariancias: \[\Gamma(t,s)= E[(X_{t}-\mu_{t})(X_{s}-\mu_s)']=E\left[ \left( \begin{array}{c} X_{t1}-\mu_{t1}\\\vdots \\X_{tk}-\mu_{tk} \end{array} \right) \left( X_{s1}-\mu_{s1},\dots ,X_{sk}-\mu_{sk} \right) \right]\]
Definición 2 (Estacionariedad débil) Sea \(X_t=(X_{t1},...,X_{tk})'\) un vector \(k \times 1\) de series temporales. Se dice que \(X_t\) es débilmente estacionario si:
El vector de medias es constante en el tiempo \[\mu=E(X_t)=\left(\begin{array}{c} \mu_1\\ \vdots \\ \mu_k \end{array}\right)\]
Y la matriz de autocovariancia depende únicamente del rezago \(h\), i.e. \[\Gamma(h)= E[(X_{t+h}-\mu)(X_{t}-\mu)']\] donde los elementos de la matriz son funciones de covariancia cruzada, \(\gamma_{ij}(h)= Cov(X_{t+h,i},X_{t,j}) =E\left[ (X_{t+h,i}-\mu_{i})(X_{tj}-\mu_{j}) \right]\) para \(i,j=1,...,k\).
Note que como \(\gamma_{ij}(h)=\gamma_{ji}(-h)\), entonces
\[\Gamma(-h)=\Gamma'(h)\]
la matriz de autocorrelaciones también depende únicamente del rezago \(h\), i.e. \[\boldsymbol{\rho}(h)= D^{-1}\Gamma(h) D^{-1}=\left[ \rho_{h,ij} \right]\] donde \(D=diag\left\lbrace \sigma_1,...,\sigma_k \right\rbrace\) es la matriz diagonal de desviaciones estándares de los componentes de \(X_t\).
Al igual que \(\Gamma(h)\), se tiene que \[\boldsymbol{\rho}(-h)=\boldsymbol{\rho}'(h)\]
Estacionariedad estricta
Definición 3 (Estacionariedad estricta) Sea \(X_t=(X_{t1},...,X_{tk})'\) un vector \(k \times 1\) de series temporales. Se dice que \(X_t\) es estrictamente estacionario, si la distribución conjunta multivariada de una colección de m tiempos: \[\left\lbrace X_{t_1},...,X_{t_m} \right\rbrace\] es igual a \[\left\lbrace X_{t_1+h},...,X_{t_m+h} \right\rbrace\] donde \(m,j\) y \(t_1,...,t_m\) son enteros positivos arbitrarios.
Nota
Una serie temporal estrictamente estacionaria es débilmente estacionaria, si sus primeros dos momentos existen.
Ruido blanco
Definición 4 (Ruido blanco)
Es una colección de vectores de variables aleatorias no correlacionadas, \(a_t\), con media \(0\) y matriz de covariancias \(\Sigma_a\).
Denotado por \(a_t \sim wn(0,\Sigma_a)\).
Si una secuencia de variables es i.i.d., i.e. \(a_t \sim iid(0,\Sigma_a)\), entonces \(a_t \sim wn(0,\Sigma_a)\).
Sin embargo, si un ruido blanco es Gaussiano, entonces \(a_t \overset{iid}{\sim} N(0,\Sigma_a)\).
Es un caso particular de los modelos de series temporales multivariados que supone que la observación de cada variable depende linealmente de los rezagos pasados de ella misma y también de otras variables.
Comúnmente se les conoce como modelos autorregresivos multivariados o modelos autorregresivos vectoriales.
Empezamos con el modelo autorregresivo vectorial de orden 1, VAR(1), de dimensión 3 (3 series): \(X_{t,1},X_{t,2},X_{t,3}\).
También es posible extender el modelo anterior con intercepto y tendencia: \[\boldsymbol{X}_{t}=\boldsymbol{\Gamma} \boldsymbol{u}_t+\boldsymbol{\Phi}\boldsymbol{X}_{t-1}+\boldsymbol{w}_{t},\]
Note que X en ARX se refiere al vector exógeno denotado por \(u_t\) y se puede extender fácilmente incluyendo variable exógenas.
VARX(p)
De esta forma, se puede generalizar a series temporales \(K\)-dimensionales y \(p\) rezagos:
\[\boldsymbol{X}_{t}=\boldsymbol{\Gamma} \boldsymbol{u}_t+\boldsymbol{\Phi_1}\boldsymbol{X}_{t-1}+...+\boldsymbol{\Phi_p}\boldsymbol{X}_{t-p}+\boldsymbol{w}_{t}\] en donde \(u_t\) es un vector \(k \times 1\) de \(k\) variables exógenas y \(\boldsymbol{\Gamma}\) es una matriz \(r \times k\) de coeficientes asociados a las variables exógenas, y
Considere el modelo en término del polinomio de rezagos:
\[A(B) \boldsymbol{X}_{t}=\boldsymbol{\Gamma} \boldsymbol{u}_t+\boldsymbol{w}_{t}\] donde \(A(B)=I-\boldsymbol{\Phi_1}B-...-\boldsymbol{\Phi_p}B^{p}\) es el polinomio autoregresivo
HQ (Hannan-Quinn):\[HQ(p)= \log \det(\tilde{Z}_u(p))+\frac{2\log(\log(T))}{T}pK^2\] donde \(\tilde{Z}_u(p)=T^{-1}\sum_{t=1}^T \hat{w}_t \hat{w}'_t\), \(p^*\) es el total de parámetros en cada ecuación y \(p\) es el orden de rezago.
BIC o criterio de información de Schwarz (SC):\[SC(p)= \log \det(\tilde{Z}_u(p))+\frac{\log(T)}{T}pK^2\]
El estadístico de Portmanteau:\[Q_h=T \sum_{j=1}^h tr(\hat{C}'_j\hat{C}^{-1}_0\hat{C}_j\hat{C}^{-1}_0)\] donde \(\hat{C}_i=\frac{1}{T}\sum_{j=i+1}^T \hat{w}_t\hat{w}'_{t-i}\). Para \(T\) y \(h\) suficientemente grandes, el estadístico se aproxima a la distribución \(\chi^2(K^2(h-n^*))\), donde \(n^*\) es la cantidad de parámetros excluyendo los de términos determinísticos.
El estadístico de Portmanteau ajustado (muestras pequeñas):\[Q^*_h=T^2 \sum_{j=1}^h \frac{1}{T-j} tr(\hat{C}'_j\hat{C}^{-1}_0\hat{C}_j\hat{C}^{-1}_0)\]
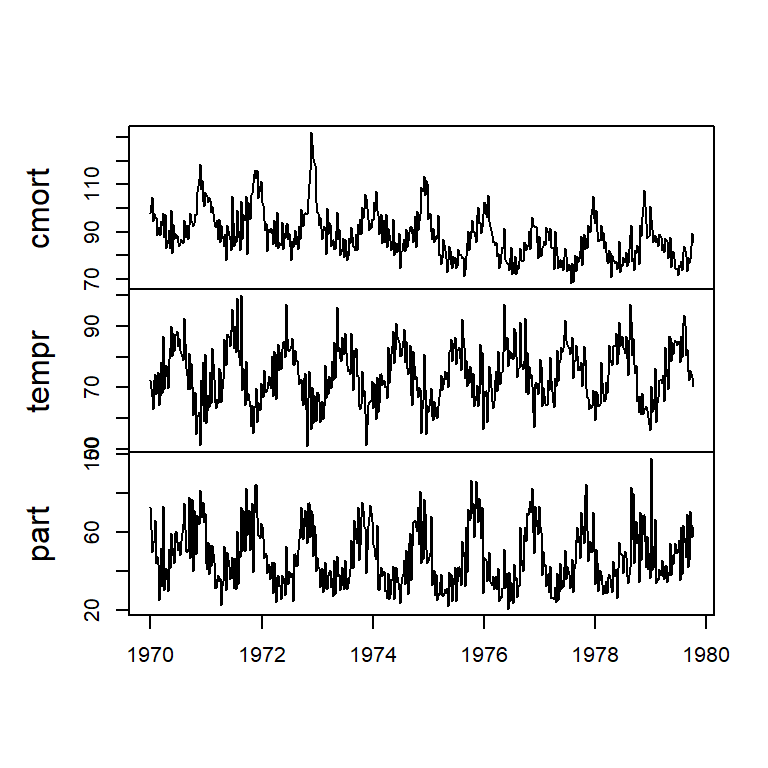
Ejemplo
3 series semanales en la zona rural de Los Angeles, EU de 1970 a 1980 \((T=508)\).
promedio semanal de mortalidad cardiovascular.
temperatura (F)
nivel de partícula (contaminación)
ARMAX(p,q) vectorial
Contenido
Introducción
Medidas de dependencia (bivariada)
Medidas de dependencia (multivariada)
Estacionariedad
VAR(p)
Diagnósticos
ARMAX(p,q) vectorial
ARMAX(p,q) vectorial
El modelo ARMAX(p,q) \(r\)-dimensionales:
\[\boldsymbol{X}_{t}=\boldsymbol{\Gamma} \boldsymbol{u}_t+ \sum_{i=1}^p \boldsymbol{\Phi_i}\boldsymbol{X}_{t-i} - \sum_{j=1}^q \boldsymbol{\Theta_j}\boldsymbol{w}_{t-j} +\boldsymbol{w}_{t}\] con \(\boldsymbol{\Phi_p}, \boldsymbol{\Theta_q} \neq \boldsymbol{0}\) y \(\Sigma_\boldsymbol{w}\) definida positiva.
Los coeficientes \(\boldsymbol{\Phi_i}:i=1,...,p\), \(\boldsymbol{\Theta_j}:j=1,...,q\) son matrices \(r \times r\)
VARMA(p,q)
Para el caso del VARMA(p,q), i.e. tiene media cero, el modelo se especifica de la forma
\[\boldsymbol{\Phi}(B) \boldsymbol{X}_{t}= \boldsymbol{\Theta}(B) \boldsymbol{w}_{t}\] en donde
\(\boldsymbol{\Phi}(B)=I- \boldsymbol{\Phi}_1 B-...- \boldsymbol{\Phi}_p B^p\) es el operador autorregresivo y
\(\boldsymbol{\Theta}(B)=I- \boldsymbol{\Theta}_1 B-...- \boldsymbol{\Theta}_q B^q\) es el operador de medias móviles.
El modelo se dice que es causal (estacionario) si las raíces de \(|\boldsymbol{\Phi}(B)|\), están fuera del círculo unitario.
El modelo se dice que es invertible si las raíces de \(|\boldsymbol{\Theta}(B)|\), están fuera del círculo unitario.