x = c(0,1,2,3)
prob = dbinom(x, size =3, prob=0.4)
acum = pbinom(x, size =3, prob=0.4)
cbind(x,prob,acum) x prob acum
[1,] 0 0.216 0.216
[2,] 1 0.432 0.648
[3,] 2 0.288 0.936
[4,] 3 0.064 1.000[1] 1.2[1] 0.72Información importante
Reglamentación
¿Qué vimos en modelos probabilísticos discretos y contínuos?
https://seeing-theory.brown.edu
https://www.acsu.buffalo.edu/~adamcunn/probability/probability.html
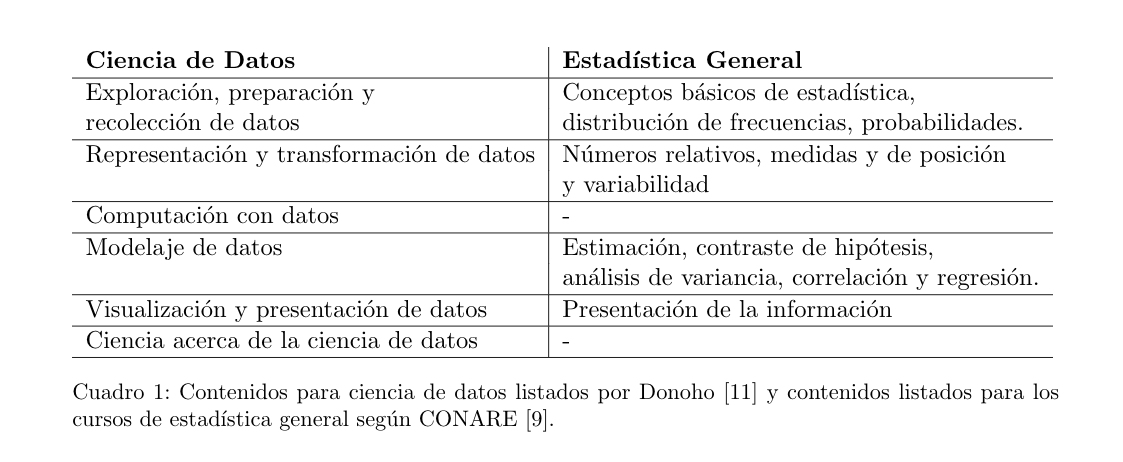
En medio del auge de ciencia de datos, datos grandes, y tantas puertas que la tecnología nos ha abierto.
Ciencia de Datos vs Estadística.
¿Para qué necesitamos Teoría Estadística?
Necesitamos entender el porqué los resultados teóricos funcionan.
Por ejemplo, si tomamos el promedio de un conjunto de dato,
Variable aleatoria (v.a.)
Muestra aleatoria (m.a.)
Parámetro
Estadístico
Estimador
Modelos estadísticos y familias de modelos
Estadística paramétrica y no paramétrica
Modos de convergencia
Ley de los grandes números
Teorema del límite central
Estadísticos de orden
Una variable aleatoria (v.a.) \({\displaystyle X}\) es una función real definida en el espacio de probabilidad \({\displaystyle (\Omega ,{\mathcal {A}},P)}\), asociado a un experimento aleatorio. \[X:\Omega \to \mathbb{R}.\]
V.A. discreta
Denote con \(Y\) cualquier variable aleatoria. La función de distribución de \(Y\), denotada por \(F(y)\), es tal que \(F(y)=P(Y \leq y)\) para \(-\infty<y<\infty\).
Propiedades de una función de distribución: Si \(F(y)\) es una función de distribución, entonces
Valor esperado \[\mu=E(Y)=\sum\limits_y y \cdot p(y).\]
Variancia \[Var(Y)=E\left[(Y-\mu)^2\right]=\sum\limits_y (y-\mu)^2\cdot p(y).\]
Ejemplo con la distribución binomial
Recuerden que la distribución binomial tiene la siguiente función de probabilidad:
\[p(y)= \begin{cases} \left(\begin{array}{l} n \\ y\end{array}\right) p^y q^{n-y}, \quad y=0,1,2, \ldots, n \text { y } 0 \leq p \leq 1, \\ 0 \quad \text{en otros casos.} \end{cases}\]
Ejemplo con la distribución binomial
x = c(0,1,2,3)
prob = dbinom(x, size =3, prob=0.4)
acum = pbinom(x, size =3, prob=0.4)
cbind(x,prob,acum) x prob acum
[1,] 0 0.216 0.216
[2,] 1 0.432 0.648
[3,] 2 0.288 0.936
[4,] 3 0.064 1.000[1] 1.2[1] 0.72Recuerde que demostraron las fórmulas:
\[E(X)=np = 3\cdot 0.4 = 1.2\] \[Var(X)=npq = 3\cdot 0.4 \cdot 0.6 = 0.72\]
V.A. continua
Una variable aleatoria \(Y\) con función de de distribución \(F(y)\) se dice que es continua si \(F(y)\) es continua, para \(-\infty<y<\infty\).
Se puede deducir que \(P(Y=y)=0\).
Sea \(F(y)\) la función de distribución para una variable aleatoria continua \(Y\). Entonces \(f(y)\), dada por \[f(y)=\frac{d F(y)}{d y}=F^{\prime}(y)\] siempre que exista la derivada, se denomina función de densidad de probabilidad para la variable aleatoria \(Y\).
Inversamente, se deduce \[F(y)=\int_{-\infty}^y f(t) d t.\]
\[\mu=E(Y)=\int\limits_{-\infty}^{\infty} y \cdot f(y) dy\]
\[Var(Y)=E\left[(Y-\mu)^2\right]=\int\limits_{-\infty}^{\infty} (y-\mu)^2 f(y) dy.\]
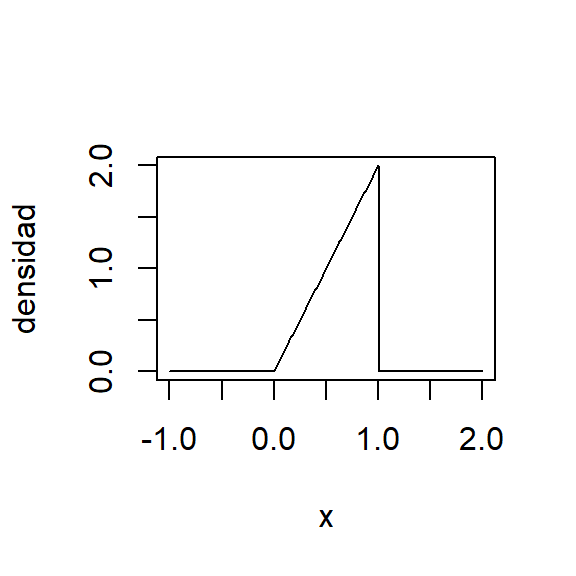
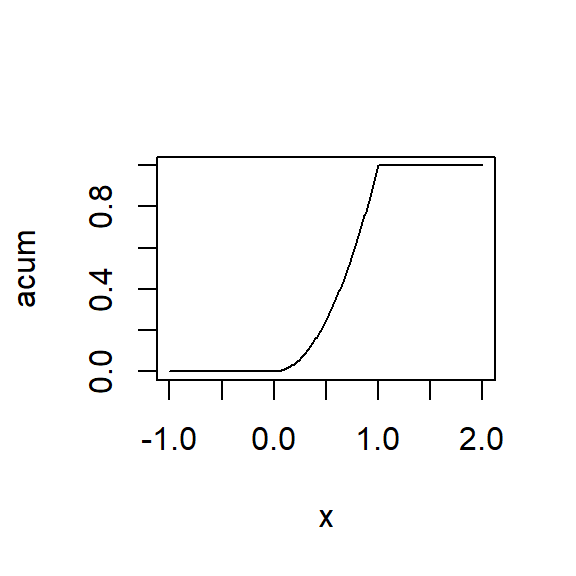
Ejemplo con la distribución beta
Suponga que \(Y\) tiene una distribución beta con parámetros \(\alpha>0\) y \(\beta>0\), es decir \[f(y)= \begin{cases}\frac{y^{\alpha-1}(1-y)^{\beta-1}}{B(\alpha, \beta)}, & 0 \leq y \leq 1 \\ 0, & \text { otro caso}\end{cases}\]
donde \[ B(\alpha, \beta)=\int_0^1 y^{\alpha-1}(1-y)^{\beta-1} d y=\frac{\Gamma(\alpha) \Gamma(\beta)}{\Gamma(\alpha+\beta)} . \]
Ejemplo con la distribución beta
Recuerde que demostraron las fórmulas: \(E(X)=\frac{\alpha}{\alpha + \beta} = \frac{2}{3},~~~Var(X)=\frac{\alpha \beta}{(\alpha + \beta)^2 (\alpha + \beta + 1)} = \frac{2}{3^2 4}=\frac{1}{18}.\)
Tarea: Compruebe la esperanza y la variancia usando las integrales.
Sean \(X_{1}, X_{2}, ... , X_{n}\) un conjunto de \(n\) variables aleatorias (v.a.) independientes e idénticamente distribuidas; este conjunto se denomina muestra aleatoria de una población infinita.
Es una característica de la población. Algunos parámetros de interés podría ser la media, varianza o la proporción en una población.
Es una función de la muestra aleatoria, \(T=f\left(X_{1}, X_{2}, ... , X_{n}\right)\). Un estadístico es a su vez una variable aleatoria y como tal tiene su propia distribución, denominada distribución muestral, con sus parámetros correspondientes.
Cuando un estadístico, llámese \(\hat{\theta}\), se utiliza para aproximar el valor de un parámetro \(\theta\), entonces se acostumbra llamar a ese estadístico con el nombre de estimador.
Notación: \(\theta\) parámetro a estimar y \(\hat{\theta}\) es el estimador de \(\theta\).
Ejemplo: