Estimación por intervalo2

¿Qué vamos a discutir hoy?
- Hemos visto hasta ahora sobre
- Estimadores puntuales.
- Intervalos de confianza clásicos.
- Ahora:
- Repaso de algunas distribuciones muestrales útiles
- Algunos intervalos de confianza más comunes.
Repaso de algunas distribuciones muestrales útiles
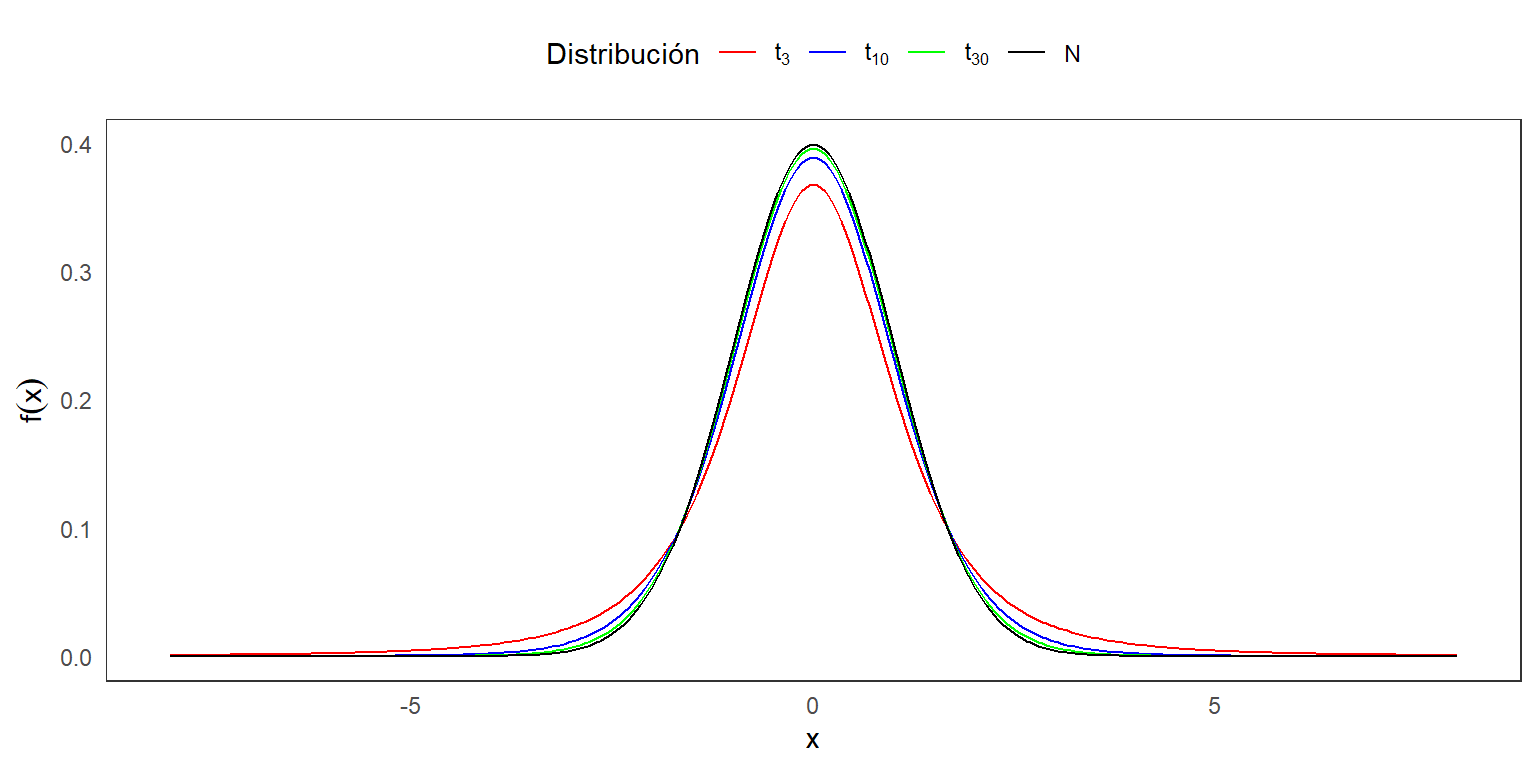
Distribución de t-Student
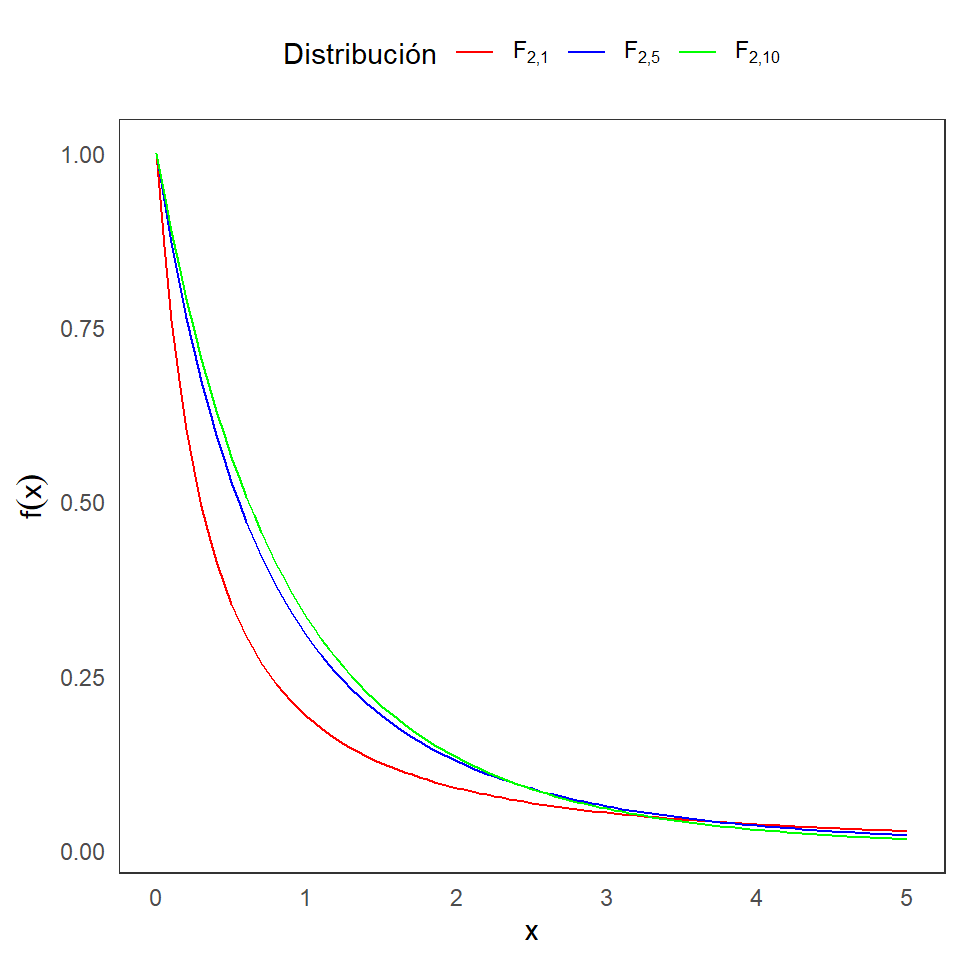
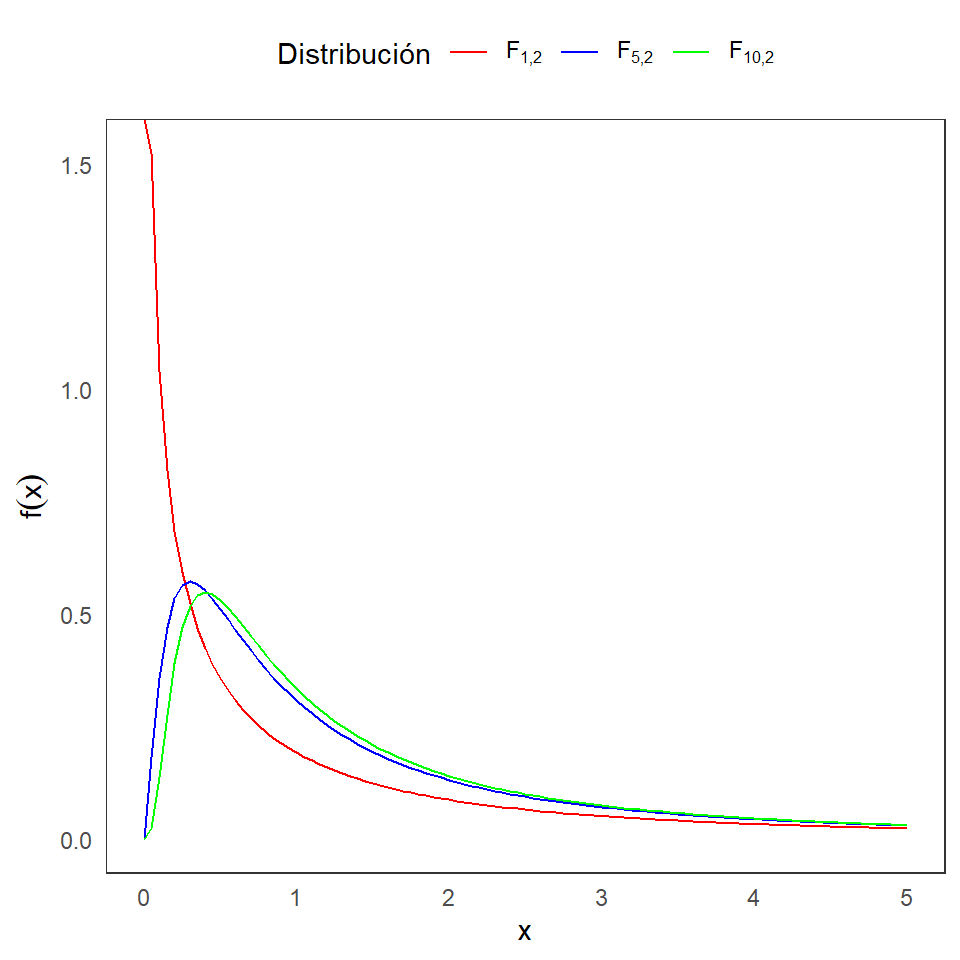
Distribución F de Fisher
Distribución de t-Student
Definición 3.2: Sean dos variables aleatorias independientes X y Y, tal que \(X \sim N(0,1)\) y \(Y \sim \chi^2_{m}\). Defina:
\[T=\frac{X}{\sqrt{\frac{Y}{m}}}.\] La distirbución de \(T\) se llama una distribución t-Student con \(m\) grados de libertad, y se denota como \(t_m\).
La función de densidad es: \[f(x|m)= \frac{\Gamma\left(\frac{m+1}{2}\right)}{(m\pi)^{1/2}\Gamma(\frac{m}{2})}\left(1+\frac{x^2}{m}\right)^{\frac{-(m+1)}{2}},~~~ -\infty<x<\infty.\]
Distribución F de Fisher
Definición 3.3: Sean dos variables aleatorias independientes X y Y, tal que \(X \sim \chi^2_{m}\) y \(Y \sim \chi^2_{n}\), con \(m\) y \(n\) enteros positivos. Defina:
\[F=\frac{\frac{X}{m}}{\frac{Y}{n}}.\] La distirbución de \(F\) se llama una distribución F con \(m\) y \(n\) grados de libertad, y se denota como \(F_{m,n}\).
La función de densidad es: \[f(x|m,n)= \frac{\Gamma\left(\frac{m+n}{2}\right) m^{m/2}n^{n/2}}{\Gamma(\frac{m}{2})\Gamma(\frac{n}{2})} \frac{x^{m/2-1}}{(mx+n)^{(m+n)/2}},~~~ 0<x,\] y \(f(x|m,n)=0\) para \(x\leq 0\).
Teoremas relacionados
Teorema 3.1:
Si \(X\) tiene una distribución \(F\) con \(m\) y \(n\) grados de libertad, entonces \(Y=1/X\) también tiene una distribución \(F\) con \(n\) y \(m\) grados de libertad.
Si \(X\) tiene una distribución t con \(m\) grados de libertad, entonces \(X^2\) tiene una distribución \(F\) con \(1\) y \(m\) grados de libertad.
IC para poblaciones normales
- Intervalos de confianza para \(\mu\) (\(\sigma^2\) conocido).
- Intervalos de confianza para \(\mu\) (\(\sigma^2\) desconocido).
- Intervalos de confianza para \(\mu_1-\mu_2\) (\(\sigma_1^2\) y \(\sigma_2^2\) conocidas).
- Intervalos de confianza para \(\mu_1-\mu_2\) (\(\sigma_1^2=\sigma_2^2\) desconocida).
Intervalos de confianza para \(\mu\) (\(\sigma^2\) conocido)
Sea \(X_{1}, X_{2}, ... , X_{n}\) una muestra aleatoria de una población Normal con media \(\mu\) y variancia \(\sigma^2\), donde \(\mu\) es desconocido pero \(\sigma^2\) es conocido. Vamos a construir un intervalo de confianza bilateral para \(\mu\) con probabilidad \(1-\alpha\).
Comosidere el pivote a \(Z = \dfrac{\bar{X} - \mu}{\dfrac{\sigma}{\sqrt{n}}}\), ya que \(Z \sim N(0,1)\). Luego procedemos a encontrar los valores \(a\) y \(b\) que satisfacen \(P(a \leq Z \leq b) = 1-\alpha\) y \(P(Z < a) = P(Z > b) = \frac{\alpha}{2}\).
Tenemos que
\(P(z_{\frac{\alpha}{2}} \leq Z \leq z_{1-\frac{\alpha}{2}}) = 1-\alpha\)
- Sin embargo, sabemos que la distribución Normal Estándar es simétrica alrededor de cero, por lo que \(z_{\frac{\alpha}{2}} = -z_{1-\frac{\alpha}{2}}\). Por lo tanto podemos escribir \[a = -z_{1-\frac{\alpha}{2}} ~~\text{y}~~ b = z_{1-\frac{\alpha}{2}}\]
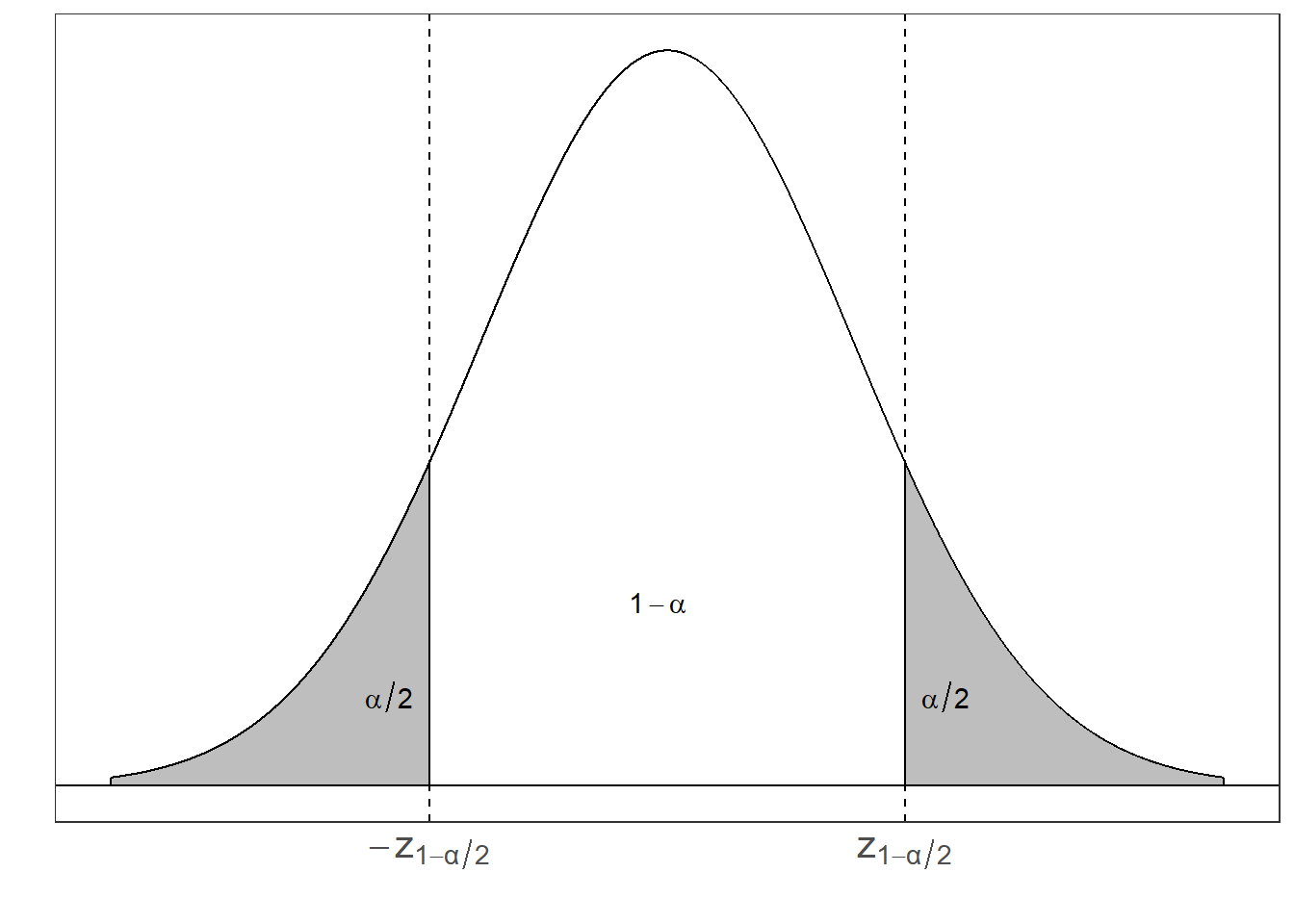
Cuantiles de una distribución N(0,1)
- Con estos valores podemos proceder a despejar \(\mu\) de la expresión \(P(a \leq Z \leq b) = 1-\alpha\): \[P(a \leq Z \leq b) = P\left(-z_{1-\frac{\alpha}{2}} \leq \dfrac{\bar{X} - \mu}{\dfrac{\sigma}{\sqrt{n}}} \leq z_{1-\frac{\alpha}{2}} \right)\]
\[= P\left( \bar{X} - z_{1-\frac{\alpha}{2}} \dfrac{\sigma}{\sqrt{n}} \leq \mu \leq \bar{X} + z_{1-\frac{\alpha}{2}} \dfrac{\sigma}{\sqrt{n}} \right) = 1-\alpha\]
- Por lo tanto, con confianza del \((1-\alpha)\%\), el intervalo \(\bar{X} \pm z_{1-\frac{\alpha}{2}} \dfrac{\sigma}{\sqrt{n}}\) contiene al valor de \(\mu\).
Intervalos de confianza para \(\mu\) (\(\sigma^2\) desconocido)
- En este caso, debemos hacer uso de un nuevo pivote. Considere:
\[T = \dfrac{\bar{X} - \mu}{\dfrac{s}{\sqrt{n}}}\]
- Recordemos que esta variable aleatoria se distribuye como una t-student con \(n-1\) grados de libertad y cumple las condiciones de un pivote.
- Está en términos de la muestra aleatoria (a través de \(\bar{X}\) y \(S\)) y del parámetro desconocido \(\mu\) y
- Adicionalmente su distribución es conocida y no depende de \(\mu\).
- Ahora procedemos a encontrar los valores de \(a\) y \(b\).
- Las tablas de la t-student generalmente acumulan hacia la derecha, pero para efecto del curso, usamos las probabilidades acumuladas de las colas izquierdas.
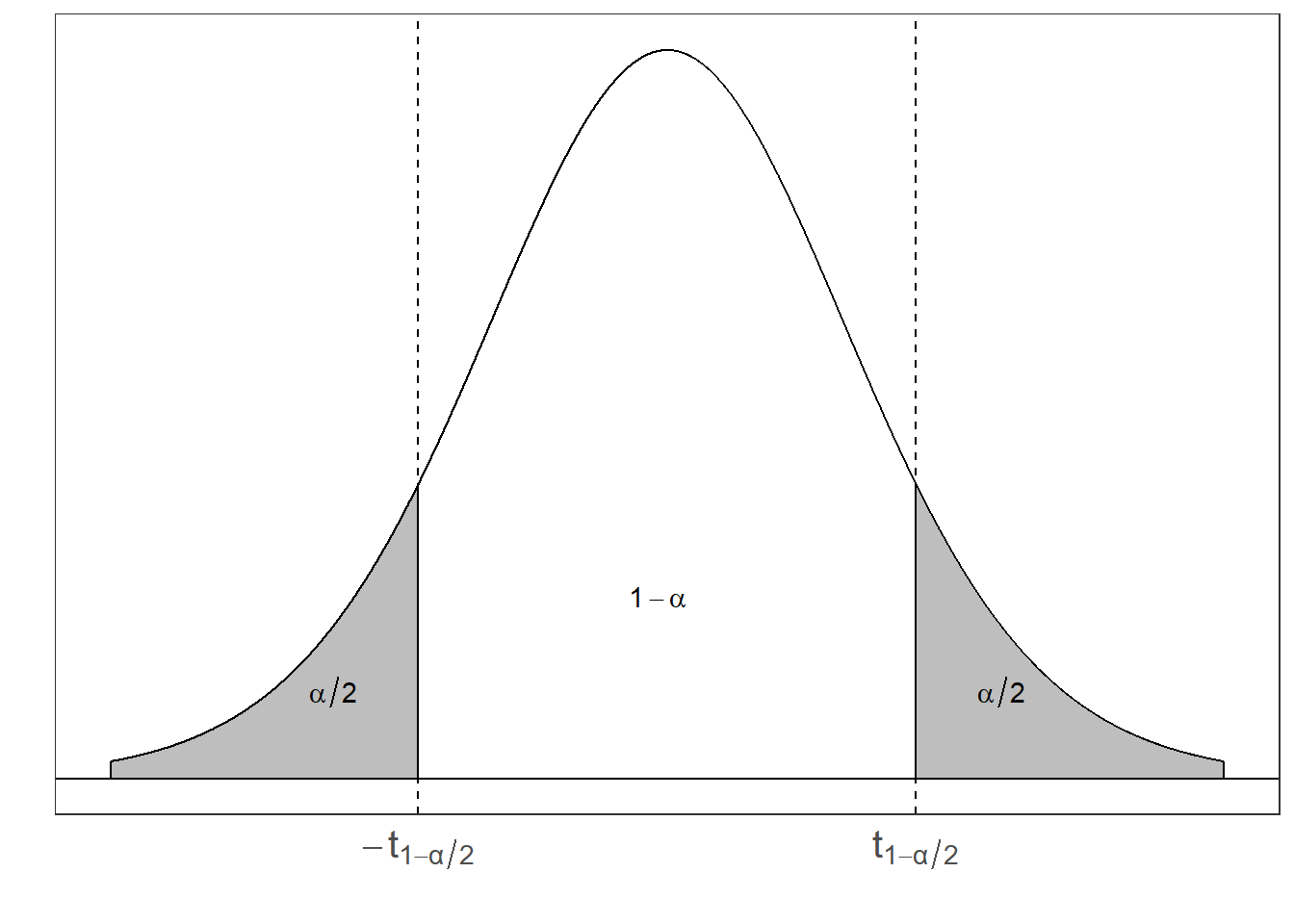
\[P(a \leq T \leq b) =P(t_{\frac{\alpha}{2},n-1} \leq T \leq t_{1-\frac{\alpha}{2},n-1}) = P\left(-t_{1-\frac{\alpha}{2},n-1} \leq \dfrac{\bar{X} - \mu}{\dfrac{S}{\sqrt{n}}} \leq t_{1-\frac{\alpha}{2},n-1} \right).\]
Si despejamos el valor de \(\mu\), obtenemos el intervalo \(\bar{X} \pm t_{\frac{\alpha}{2}, n-1} \dfrac{s}{\sqrt{n}}\).
Por lo tanto podemos concluir que con una confianza del \((1-\alpha)\%\) el intervalo \(\bar{X} \pm t_{1-\frac{\alpha}{2}, n-1} \dfrac{s}{\sqrt{n}}\) contiene el verdadero valor de \(\mu\).
Intervalos de confianza para \(\mu_{1} - \mu_{2}\) (\(\sigma_1^2\) y \(\sigma_2^2\) conocidas)
Ahora supongamos que tenemos dos poblaciones normales e independientes y que obtenemos una muestra de cada una.
Sean \(X_{1}, X_{2}, ... , X_{n}\) y \(Y_{1}, Y_{2}, ... , Y_{m}\) estas dos muestras aleatorias, tal que \(X_{j} \sim N(\mu_{1}, \sigma^{2}_{1})\) y \(Y_{i} \sim N(\mu_{2}, \sigma^{2}_{2})\), donde \(\mu_{1}\) y \(\mu_2\) son parámetros desconocidos y \(\sigma^{2}_{1}\) y \(\sigma^{2}_{2}\) son parámetros conocidos. Nos interesa construir un intervalo bilateral, con una confianza del \((1-\alpha)\%\), para \(\mu_{1} - \mu_{2}\).
Recordemos que \(\bar{X} \sim N\left(\mu_{1}, \dfrac{\sigma^{2}_{1}}{n}\right)\) y \(\bar{Y} \sim N\left(\mu_{2}, \dfrac{\sigma^{2}_{2}}{m}\right)\). Además, \(\bar{X} - \bar{Y}\) se distribuye Normal con media \(\mu_{1} - \mu_{2}\) y variancia \(\dfrac{\sigma^{2}_{1}}{n} + \dfrac{\sigma^{2}_{2}}{m}\).
Estandarizando dicha variable, tenemos un pivote:
\[Z = \dfrac{(\bar{X} - \bar{Y}) - (\mu_{1} - \mu_{2})}{\sqrt{\dfrac{\sigma^{2}_{1}}{n} + \dfrac{\sigma^{2}_{2}}{m}}}\]
- Siguiendo el mismo paso del primer caso de esta sección, obtener que \(a = -z_{1-\frac{\alpha}{2}}\) y \(b = z_{1-\frac{\alpha}{2}}\). Ahora procedemos a despejar nuestro parámetro de interés, \(\mu_{1} - \mu_{2}\), de la expresión \(P(a \leq Z \leq b) = 1-\alpha\).
\[P(a \leq Z \leq b) = P\left(-z_{1-\frac{\alpha}{2}} \leq \dfrac{(\bar{X} - \bar{Y}) - (\mu_{1} - \mu_{2})}{\sqrt{\dfrac{\sigma^{2}_{1}}{n} + \dfrac{\sigma^{2}_{2}}{m}}} \leq z_{1-\frac{\alpha}{2}} \right)=1-\alpha.\]
- El IC para \(\mu_{1} - \mu_{2}\) está dado por \((\bar{X} - \bar{Y}) \pm z_{1-\frac{\alpha}{2}} \sqrt{\dfrac{\sigma^{2}_{1}}{n} + \dfrac{\sigma^{2}_{2}}{m}}\).
Nota: Si fuese el caso donde las variancias poblaciones son iguales (i.e. \(\sigma^{2}_{1} = \sigma^{2}_{2} = \sigma^{2}\)) Entonces podriamos escribir el intervalo como:
\[(\bar{X} - \bar{Y}) \pm z_{1-\frac{\alpha}{2}} \cdot \sigma \sqrt{\dfrac{1}{n} + \dfrac{1}{m}}.\]
Intervalos de confianza para \(\mu_{1} - \mu_{2}\) (\(\sigma_1^2=\sigma_2^2\) desconocida)
¿Por qué es importante el supuesto de homoscedasticidad (\(\sigma^{2}_{1} = \sigma^{2}_{2} = \sigma^{2}\))? Para poder encontrar un pivote satisfactorio.
Considere \[T = \dfrac{Z}{\sqrt{\dfrac{W}{v}}}\] donde \(Z \sim N(0,1)\) y \(W \sim \chi^{2}_{(v)}\). Para este caso podemos usar la misma \(Z\) que usamos anteriormente:
\[Z = \dfrac{(\bar{X} - \bar{Y}) - (\mu_{1} - \mu_{2})}{\sigma \sqrt{\dfrac{1}{n} + \dfrac{1}{m}}}\]
- Ahora debemos construir una \(\chi^2\) adecuada que nos permita cancelar el \(\sigma\) que se encuentra en \(Z\). Sabemos lo siguiente: \[\dfrac{(n-1)S^{2}_1}{\sigma^{2}} \sim \chi^{2}_{(n-1)}, \qquad \text{y} \qquad \dfrac{(m-1)S^{2}_2}{\sigma^{2}} \sim \chi^{2}_{(m-1)}\] donde \(S^{2}_1\) y \(S^{2}_2\) son las variancias muestrales de la primera y segunda población, respectivamente. También sabemos que la suma de ji-cuadrado es una ji-cuadrado con la suma de los grados de libertad:
\[W = \dfrac{(n-1)S^{2}_{1} + (m-1)S^{2}_{2} }{\sigma^{2}} \sim \chi^{2}_{(n+m-2)}\]
Si procedemos a dividir esta ji-cuadrado entre sus grados de libertad obtenemos: \[\dfrac{W}{v} = \dfrac{(n-1)S^{2}_{1} + (m-1)S^{2}_{2} }{\sigma^{2}(n+m-2)}\]
- Para simplificar un poco esta expresión vamos a definir \(S^{2}_{p} = \dfrac{(n-1)S^{2}_{1} + (m-1)S^{2}_{2}}{(n+m-2)}\), por lo tanto \[\dfrac{W}{v} = \dfrac{S^{2}_{p}}{\sigma^{2}}\]
- Ya con esto podemos definir una t-student, la cual tendría la forma:
\[T = \dfrac{(\bar{X} - \bar{Y}) - (\mu_{1} - \mu_{2})}{S_{p} \sqrt{\dfrac{1}{n} + \dfrac{1}{m}}}\]
Esta es una t-student con \(n+m-2\) grados de libertad y la podemos usar como pivote pues cumple todas las condiciones y ya no está en términos de parámetros desconocidos.
El procedimiento a seguir es similar al otro caso donde teniamos una t-student y luego de desarrollarlo obtenemos el intervalo
\[\displaystyle (\bar{X} - \bar{Y}) \pm t_{1-\frac{\alpha}{2}, n+m-2} \cdot S_{p} \sqrt{\frac{1}{n} + \dfrac{1}{m}}\]
Concluimos que con una probabilidad de \(1-\alpha\) el intervalo \((\bar{X} - \bar{Y}) \pm t_{1-\frac{\alpha}{2}, n+m-2} \cdot S_{p} \sqrt{\frac{1}{n} + \frac{1}{m}}\) contiene el verdadero valor de \(\mu_{1} - \mu_{2}\).
Pivotes para distribuciones con forma posición-escala
En los ejercicios 9.8 y 9.9 de Casella y Berger, se utiliza la siguiente tabla para clasificar las funciones de densidad según forma. En esta tabla se refieren a la mayoría de distribuciones de la familia Exponencial, en las cuales la función de densidad se puede reescribir siguiendo la forma de la primera columna.
| Forma | Tipo | Pivote |
|---|---|---|
| \(f(x-\mu)\) | Posición | \(\bar{X}-\mu\) |
| \(\dfrac{1}{\sigma}f(x/\sigma)\) | Escala | \(\dfrac{\bar{X}}{\sigma}\) |
| \(\dfrac{1}{\sigma}f\left( \dfrac{x-\mu}{\sigma}\right)\) | Posición-Escala | \(\dfrac{\bar{X}-\mu}{S}\) |
Para entender las 3 formas, veamos los siguientes ejemplos:
- Para \(f(x-\mu)\):
Sea \(X \sim N(\mu, 1)\), entonces la función de densidad es:
\[f(x) = \dfrac{1}{\sqrt{2\pi}} e^{\dfrac{-1}{2}(x-\mu)^2} = g(z)\] en donde \(z = x-\mu\), y \(g(z)=\dfrac{1}{\sqrt{2\pi}} e^{\dfrac{-1}{2}z^2}\).
- Para \(\dfrac{1}{\sigma}f(x/\sigma)\):
Sea \(X \sim N(0, \sigma^2)\), entonces la función de densidad es:
\[f(x) = \dfrac{1}{\sigma}\dfrac{1}{\sqrt{2\pi}} e^{\dfrac{-1}{2}(x/\sigma)^2} = \dfrac{1}{\sigma} g(z)\] en donde \(z = x/\sigma\), y \(g(z)=\dfrac{1}{\sqrt{2\pi}} e^{\dfrac{-1}{2}(z)^2}\).
- Finalmente, para \(\dfrac{1}{\sigma}f\left(\dfrac{x-\mu}{\sigma}\right)\):
Sea \(X \sim N(\mu, \sigma^2)\), entonces la función de densidad es:
\[f(x) = \dfrac{1}{\sigma}\dfrac{1}{\sqrt{2\pi}} e^{\dfrac{-1}{2}\left(\dfrac{x-\mu}{\sigma}\right)^2} = \dfrac{1}{\sigma} g(z)\] en donde \(z = \dfrac{x-\mu}{\sigma}\), y \(g(z)=\dfrac{1}{\sqrt{2\pi}} e^{\dfrac{-1}{2}(z)^2}\).
¿Qué discutimos hoy?
Estimación por intervalos, método del pivote. Fórmulas para las estimaciones por intervalo más comunes (media, diferencias de medias para distribuciones normales),
Intervalos de confianza para variancias, y para muestras grandes.