Alternativas no paramétricas2

¿Qué vamos a discutir hoy?
- Hemos visto hasta ahora sobre
- Estadística paramétrica
- Estimadores puntuales
- Intervalos de confianza.
- Contrastes de hipótesis.
- Estadística no paramétrica
- Estimación de densidad vía histograma y kernel.
- Bootstrap (Ahora)
- Estadística paramétrica
Distribución empírica
- Para una muestra \(X_1, \dots, X_n\) de variables aleatorias con valores reales, independientes con distribución \(P\), definimos la distribución \(\hat{P}\) como:
\[\hat{P}(A) = \frac{1}{n}\sum_{i=1}^{n} I_A(X_i),\] para \(A \subseteq \mathbb{R}\) y \(I_A(X_i)\) es la función indicadora definida como:
\[I_A(X_i)=\left\lbrace \begin{aligned} 1 & \text{, si } X_i \in A, \\ 0 & \text{, si } X_i \notin A. \end{aligned} \right.\]
Ejemplo:
[1] 1.6393935 3.7942324 0.5696820 3.4537757 2.5820120 0.3386898 3.6935743
[8] 2.9176752 1.0788570 1.2806120[1] 0.2[1] 0.3[1] 0.2[1] 0.3[1] 0[1] 2 3 2 3 0[1] 0.2 0.3 0.2 0.3 0.0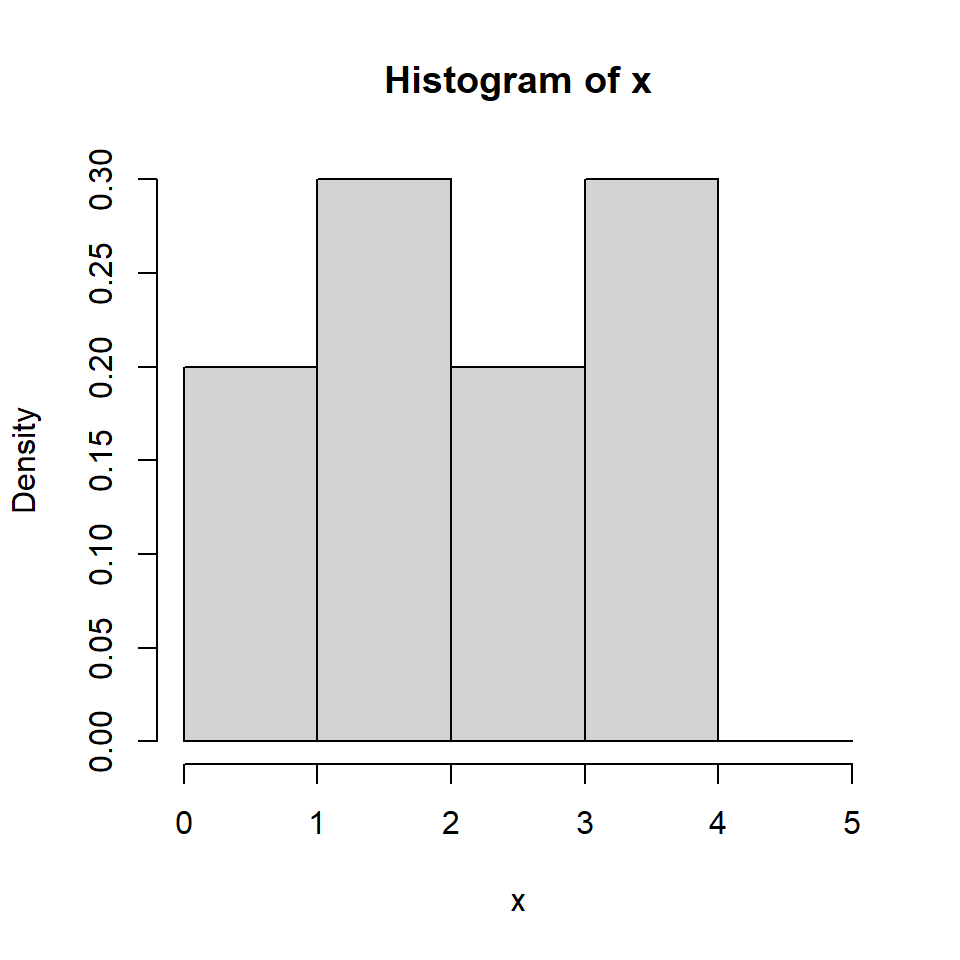
El Principio de Bootstrap
- Si queremos estimar un parámetro \(\theta\), por ejemplo, la media poblacional de \(P\), usualmente es posible obtenerlo por medio de la distribución \(P\):
\[\mu = E(X)=\int x f(x)dx=\int x P(x) dx.\] Es decir, en general \(\theta=T(P)\).
De la población \(P\), extraemos una muestra aleatoria: \(X_1,...,X_n\).
Consideremos un estimador \(\hat{\theta}=s(X_1,...,X_n)\) de \(\theta\).
El objetivo de la inferencia estadística consiste en:
- Usar un algorítmo \(s(X_1,...,X_n)\) para obtener información relacionada a \(\theta\).
- Evaluar la variabilidad de ese algorítmo para ver su eficiencia.
- ¿Qué pasaría si no es posible obtener la variancia teórica de \(\hat{\theta}\)?
Dr. Bradley Efron
El Principio de Bootstrap

Definición 5.1: Una muestra aleatoria de tamaño \(n\), \(X_1^*,...,X_n^*\) extraída de la distribución empírica \(\hat{P}\), es denominada como una muestra de bootstrap.
Observación:
Note que esto significa que las \(n\) observaciones se selecciona con reemplazo de la distribución \(\hat{P}\), o sea los datos originales \(\left\lbrace X_1,...,X_n \right\rbrace\).
Por eso la muestra de bootstrap también se le conoce como muestra remuestreada.
Esto nos lleva al siguiente proceso:
\(X = (X_1, \dots, X_n)^T\) es una muestra aleatoria de una distribución \(P\).
Seleccione \(i_1, \dots, i_n\) independientemente de una distribución uniforme en \({1, \dots, n}\).
Ahora haga \(X_{j}^{*} = X_{i_{j}}\) y \(X^* = (X^*_1, \dots, X^*_n)^T\).
El procedimiento consiste en:
- Escoja B muestras bootstrap independientes \(X^{*(1)}, \dots, X^{*(B)}\) de \(\hat{P}\): \(X_1^{*(b)}, \dots, X^{*(b)}_n \overset{iid}{\sim} \hat{P}\), para \(b = 1, \dots, B\).
- Evalúe las repeticiones de bootstrap: \(\hat{\theta}^{*(b)}=s(X^{*(b)})\).
- Estime la distribución muestral de \(\theta\) con la distribución empírica de las repeticiones bootstrap: \(\hat{\theta}^{*(1)}, \dots,\hat{\theta}^{*(B)}\):
\[\hat{P}\left(\hat{\theta}(A)\right) = \frac{1}{B}\sum_{b=1}^{B} 1_A\left(\hat{\theta}^{*(b)}\right)\]
para conjuntos apropiados de \(A \subseteq \mathbb{R}^p\) (si \(\hat{\theta} \in \mathbb{R}^p\)).
- En otras palabras, la idea es obtener \(B\) réplicas de muestras de Bootstrap: \[X^{*(1)}=\left[ X_1^{*(1)},...,X_n^{*(1)} \right] ~~~~\rightarrow \hat{\theta}^{*(1)}=s\left(X^{*(1)}\right)\] \[X^{*(2)}=\left[ X_1^{*(2)},...,X_n^{*(2)}\right]~~~~\rightarrow \hat{\theta}^{*(2)}=s\left(X^{*(2)}\right)\] \[\vdots\] \[X^{*(B)}=\left[ X_1^{*(B)},...,X_n^{*(B)}\right]~~~~\rightarrow \hat{\theta}^{*(B)}=s\left(X^{*(B)}\right)\] y obtener la distribución empírica de \(\hat{\theta}^*\) como una aproximación de la distribución muestral de \(\hat{\theta}\):
\[P(\hat{\theta} \in A) = \hat{P}(\hat{\theta}^{*} \in A).\]
- Generalmente, nos interesa solamente una medida de esa distribución. Por ejemplo, su variancia.
Bootstrap para calcular errores estándar
Sea \(\hat{\theta}\) un estimador de \(\theta\) y suponga que queremos conocer el error estándar de \(\hat{\theta}\). Un error estándar estimado de bootstrap se puede obtener con el siguiente algoritmo:
- Escoja B muestras bootstrap independientes \(X^{*(1)}, \dots, X^{*(B)}\) de \(\hat{P}\): \(X_1^{*(b)}, \dots, X^{*(b)}_n \sim_{iid} \hat{P}\) para \(b = 1, \dots, B\).
- Evalúe las repeticiones de bootstrap: \(\hat{\theta}^{*(b)}=s(X^{*(b)})\).
- Estime los errores estándares con la desviación estándar de las \(B\) repeticiones:
\[\widehat{\operatorname{ee}}_{boot} = \sqrt{\frac{1}{B-1}\sum_{b=1}^{B}\left(\hat{\theta}^{*(b)}-\hat{\theta}^{*(.)}\right)^2}\]
donde \(\hat{\theta}^{*(.)} = \frac{1}{B}\sum\limits_{b=1}^{B}\hat{\theta}^{*(b)}\).
Bootstrap para calcular el sesgo
Suponga que queremos estimar un parámetro \(\theta = t(P)\) con el estadístico \(\hat{\theta}= s(X)\). El sesgo de un estimador \(\hat{\theta}\) está definido como:
\[\operatorname{sesgo}(\hat{\theta})= E(\hat{\theta})-\theta\]
Si sustituimos \(P\) por la distribución empírica \(\hat{P}\), entonces obtenemos el estimador bootstrap del sesgo:
\[\widehat{\operatorname{sesgo}}(\hat{\theta})= \operatorname{sesgo}^*(\hat{\theta}^*) = E(\hat{\theta}^*)-\theta^*\] donde \(\theta^* = T(\hat{P})\). Note que \(\theta=T(P)\) y \(\theta^*\) pueden ser diferentes.
Bootstrap para calcular el intervalo de confianza
- A partir de las repeticiones bootstrap \(\hat{\theta}^{*(1)}, \dots,\hat{\theta}^{*(B)}\), podemos estimar la distribución muestral de \(\hat{\theta}\) (y calcular el error estándar del estimador).
- Como consecuencia, podemos construir intervalos de confianza para \(\theta\). Hay cuatro opciones:
- IC estándar,
- IC bootstrap t,
- IC percentiles,
- IC percentiles corregido por sesgo.
- IC estándar: Utilizamos el resultado del TLC para decir que \(\hat{\theta}\) es distribuido aproximadamente normal con media \(\theta\) y variancia \(\operatorname{ee}(\hat{\theta})^2\). Entonces, un IC \((1-\alpha)\) aproximado para \(\theta\) está dado por:
\[\hat{\theta} \pm z_{1-\alpha/2} \hat{\operatorname{ee}}_{boot}(\hat{\theta})\]
- IC bootstrap t:
De las muestras bootstrap \(X^{*(b)}\), \(b=1,...,B\), se calcula: \[T^{*(b)}=\frac{\hat{\theta}^{*(b)}-\hat{\theta}}{\hat{\operatorname{ee}}\left( \hat{\theta}^{*(b)}\right)},\] donde \(\hat{\theta}^{*(b)}\) y \(\widehat{\operatorname{ee}}\left(\hat{\theta}^{*(b)}\right)\) es el estimador y su error estándar, respectivamente, calculado con la muestra de boostrap \(b\). Note que su error estándar no está disponible (se debe hacer otro bootstrap para aproximarlo).
De los valores \(T^{*(b)}\), podemos estimar el valor crítico \(t_{\alpha/2}\) como \(\hat{t}_{\alpha/2}\) tal que: \[\frac{1}{B} \sum_{b=1}^{B} 1 {[ T^{*(b)} \leq \hat{t}_{\alpha/2} ]} \approx \alpha/2.\] Entonces: \[\left[ \hat{\theta} + \hat{t}_{\alpha/2} \hat{\operatorname{ee}}_{boot}(\hat{\theta}), \hat{\theta} + \hat{t}_{1-\alpha/2} \hat{\operatorname{ee}}_{boot}(\hat{\theta}) \right]\]
- IC percentiles: Si solo queremos utilizar los cuantiles empíricos:
\[\hat{P}^*\left(\hat{\theta}^*\leq \hat{\theta}_{inf}\right)=\frac{1}{B} \sum_{b=1}^{B}1\left[\hat{\theta}^{*(b)} \leq \hat{\theta}_{inf}\right]\approx \alpha/2\]
\[\hat{P}^*(\hat{\theta}^* \geq \hat{\theta}_{sup}) = \frac{1}{B} \sum_{b=1}^{B} 1\left[\hat{\theta}^{*(b)} \geq \hat{\theta}_{sup}\right] \approx \alpha/2\]
- IC percentiles corregido por sesgo: La opción anterior asume que el área debajo de la curva en las dos colas es igual. Si el estimador \(\hat{\theta}\) no es la mediana de la distribución bootstrap, entonces esta condición no se cumple. En este caso debemos corregirlo, y hay varias opciones que no serán vistas en esta ocasión.
Lab05a
¿Qué discutimos hoy?
- Repaso:
- modelos estadísticos
- Estadística paramétrica y no paramétrica
- Distribución empírica
- Bootstrap